![]()
Page 101 – The GitHub Blog
Updates, ideas, and inspiration from GitHub to help developers build and design software.
GitHub Discussions is out of beta
17 Aug 2021, 7:59 pm
Creating open source software today is so much more than the source code. It’s about managing the influx of great ideas, developing the next generation of maintainers, helping new developers learn and grow, and establishing the culture and personality of your community.
Over the past year, thousands of communities of all shapes and sizes have been using the GitHub Discussions beta as the central space for their communities to gather on GitHub in a productive and collaborative manner. We’ve learned a lot from your customer feedback and have shipped many highly requested features along the way, so we’re ready now for Discussions to enter its next chapter.
Today, we’re excited to announce that GitHub Discussions is officially out of beta. Let’s take a look at what you can do with Discussions and how top open source communities are using it.
What can you do with Discussions?
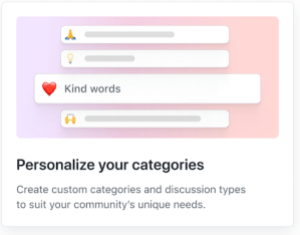
GitHub Discussions equips your community and core team with the tools and processes to make community engagement fun and collaborative. In addition to marking the most helpful answers, upvoting, customizing categories, and pinning big announcements, we’ve added the following features to Discussions to help maintainers stay on top of community management.
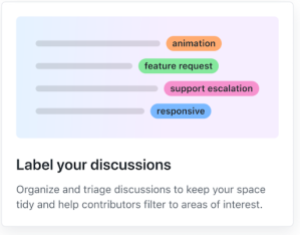
- Label your discussions. Maintainers can now organize and triage discussions with labels to keep the space tidy and help members filter to areas of interest.
- Connect to your apps. Power users can integrate with GitHub Actions or any existing workflows via the new Discussions GraphQL API and Webhooks.
- Respond on-the-go with mobile. Check in and respond to discussions whenever and wherever is most convenient with GitHub Discussions on mobile.
Just because Discussions is now out of beta doesn’t mean we’ll stop shipping your highly requested features. We’re excited to share upcoming features that will help maintainers become more connected to their communities than ever.
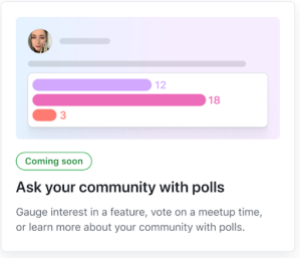
- Ask your community with polls. With the new Polls category, maintainers will be able to gauge interest in a feature, vote on a meetup time, or learn more about their communities.
- Monitor community insights. Soon you’ll be able to track the health and growth of your community with a dashboard full of actionable data.
As a recap, here’s what you can do with Discussions, including a sneak peek at what’s to come.

What are open source communities saying about Discussions?
We’ve been very intentional in partnering closely with vibrant open source communities. Managing an open source community is already burdensome enough, and Discussions has made maintainers’ lives easier, not harder.
“GitHub Discussions has allowed us to grow the Next.js community in the same tool that we use to collaborate. This has allowed us to collaborate and interact with our community that has grown by 900% since moving to GitHub Discussions.”
~ @timneutkens, maintainer of Next.js
“ Discussions have enabled the communities I work with to engage in a space dedicated to them that’s accessible, removing the necessity to set up bespoke solutions or to take on the burden of maintaining additional external services.”
~ @bnb, maintainer of Node
“We had forum software before, but allowing all our contributors to find the forum on one platform has done wonders for the engagement. Being able to easily link between issues and discussions, allowing everyone to keep track of the history, has been one of those delightful experiences that sometimes make tech feel like magic (again).”
~ @SMillerDev, maintainer of Homebrew
“GitHub Discussions enabled us to make feature launches more community-centered as each feature and experiment got its own discussion in a dedicated space outside of the issue tracker. With its threading support, we were able to individually address comments without losing them in the larger discussion. A great side-effect of this is that our issue tracker is now separate from questions, feature requests, and general chit-chat.”
~ @LekoArts, maintainer of Gatsby
How do I get started?
If you are an admin or a maintainer of a repository, you can enable Discussions under “Features” in the repository settings. Happy discussion-ing!
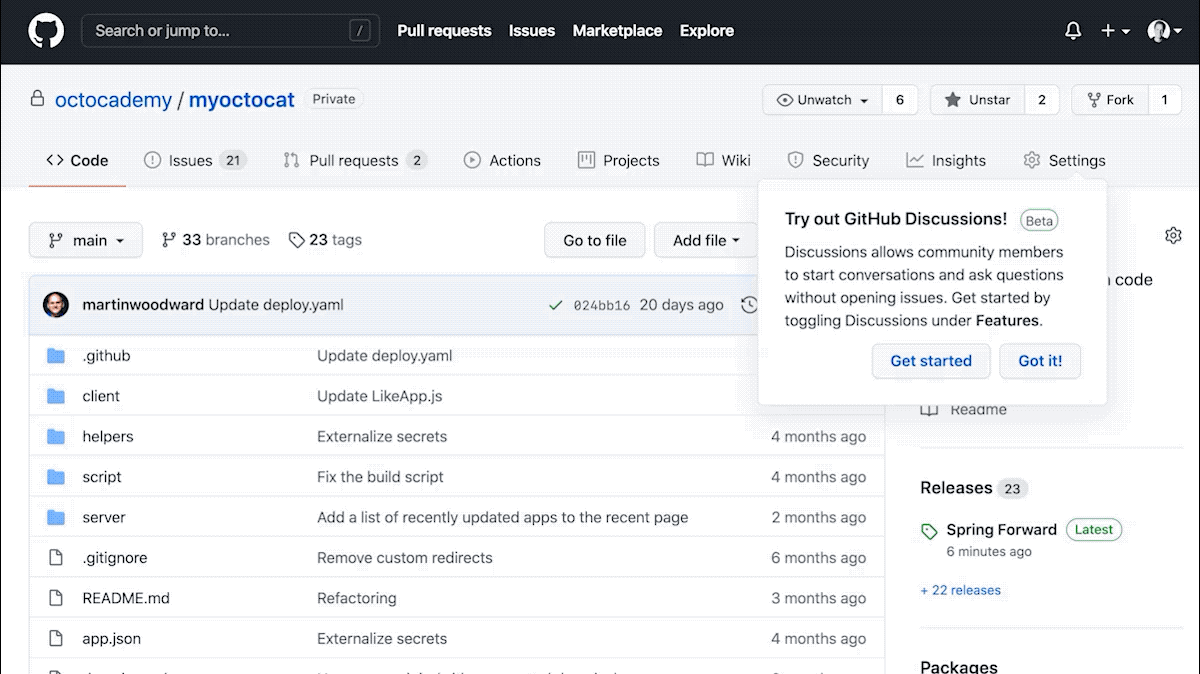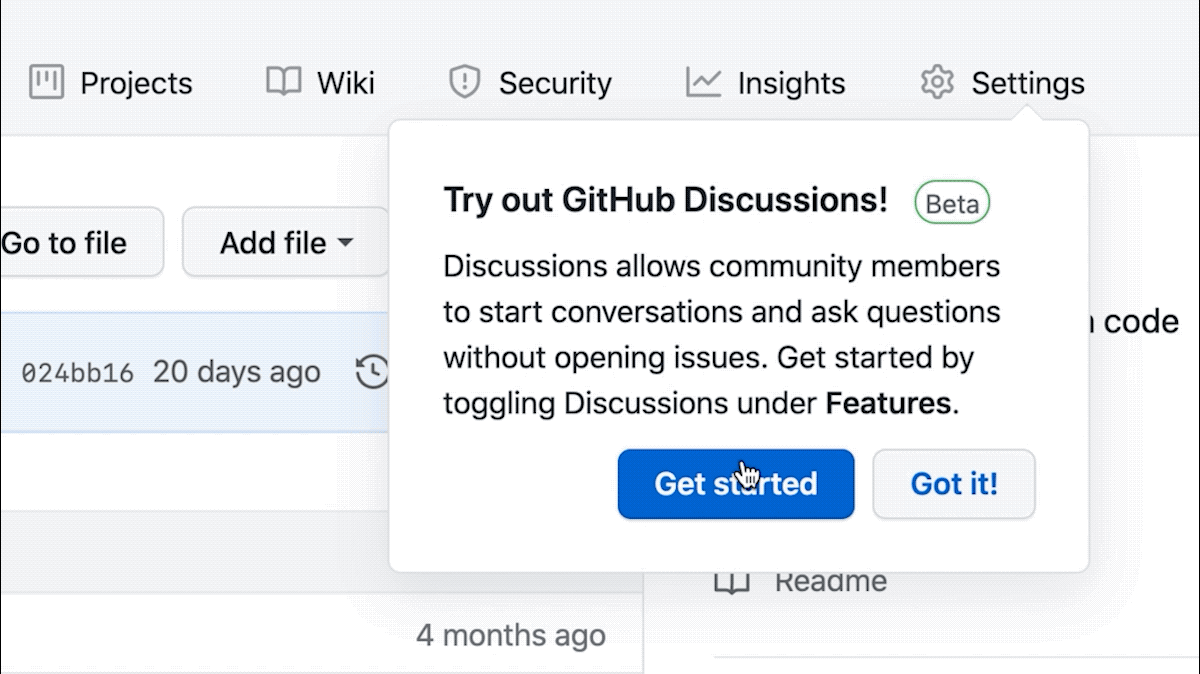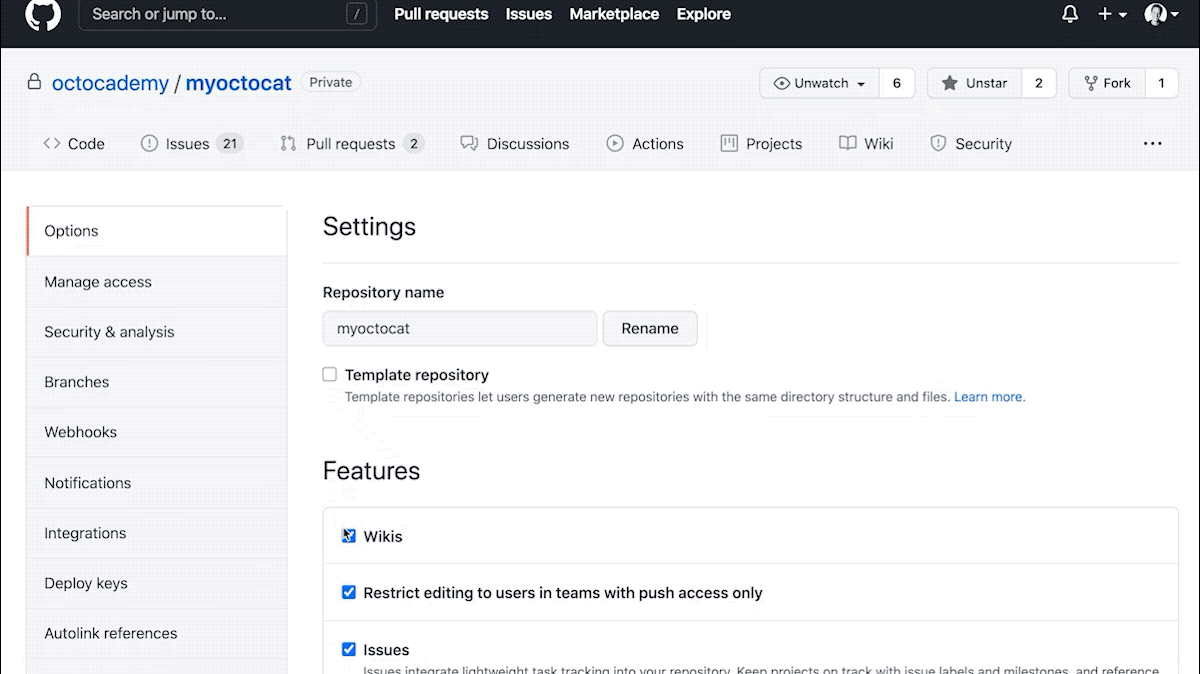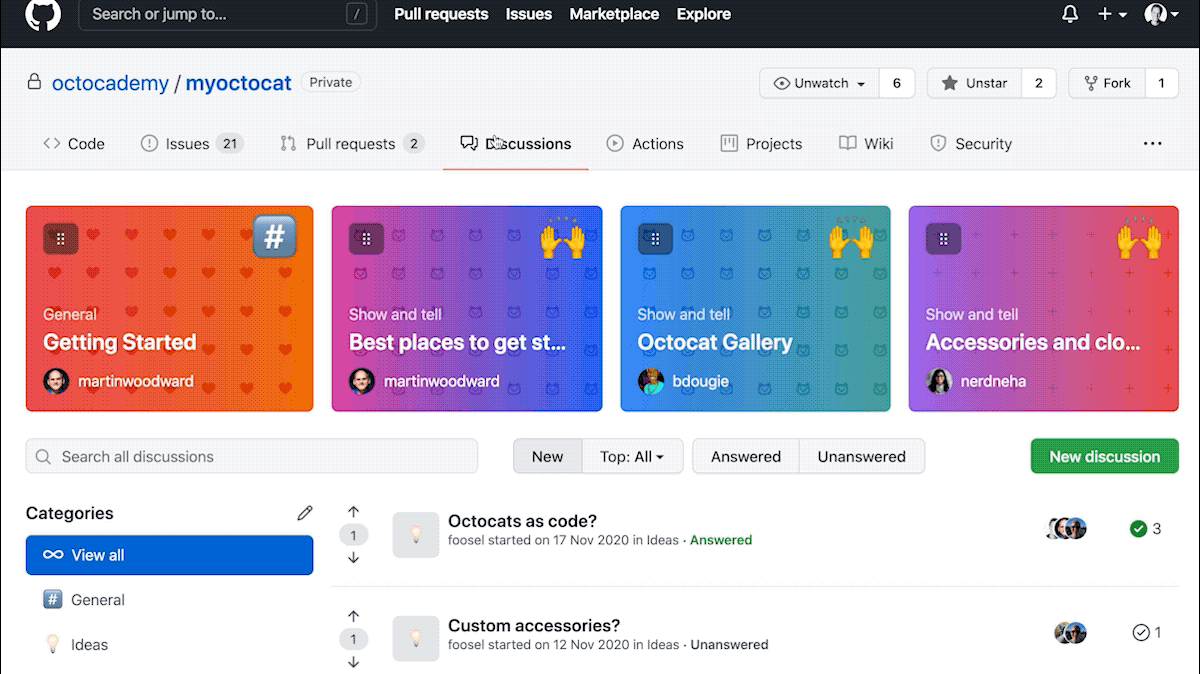
For feedback and questions, visit GitHub Discussions feedback. For more information, visit GitHub Discussions documentation.
The post GitHub Discussions is out of beta appeared first on The GitHub Blog.
Highlights from Git 2.33
16 Aug 2021, 11:15 pm
The open source Git project just released Git 2.33 with features and bug fixes from over 74 contributors, 19 of them new. We last caught up with you on the latest in Git when 2.31 was released. Here’s a look at some of the most interesting features and changes since then.
Geometric repacking
In a previous blog post, we discussed how GitHub was using a new mode of git repack to implement our repository maintenance jobs. In Git 2.32, many of those patches were released in the open-source Git project. So, in case you haven’t read our earlier blog post, or just need a refresher, here are some details on geometric repacking.
Historically, git repack did one of two things: it either repacked all loose objects into a new pack (optionally deleting the loose copies of each of those objects), or it repacked all packs together into a single, new pack (optionally deleting the redundant packs).
Generally speaking, Git has better performance when there are fewer packs, since many operations scale with the number of packs in a repository. So it’s often a good idea to pack everything together into one single pack. But historically speaking, busy repositories often require that all of their contents be packed together into a single, enormous pack. That’s because reachability bitmaps, which are a critical optimization for server-side Git performance, can only describe the objects in a single pack. So if you want to use bitmaps to effectively cover many objects in your repository, those objects have to be stored together in the same pack.
We’re working toward removing that limitation (you can read more about how we’ve done that), but one important step along the way is to implement a new repacking scheme that trades off between having a relatively small number of packs, and packing together recently added objects (in other words, approximating the new objects added since the previous repack).
To do that, Git learned a new “geometric” repacking strategy. The idea is to determine a (small-ish) set of packs which could be combined together so that the remaining packs form a geometric progression based on object size. In other words, if the smallest pack has N objects, then the next-largest pack would have at least 2N objects, and so on, doubling (or growing by an arbitrary constant) at each step along the way.
To better understand how this works, let’s work through an example on seven packs. First, Git orders all packs (represented below by a green or red square) in ascending order based on the number of objects they contain (the numbers inside each square). Then, adjacent packs are compared (starting with the largest packs and working toward the smaller ones) to ensure that a geometric progression exists:
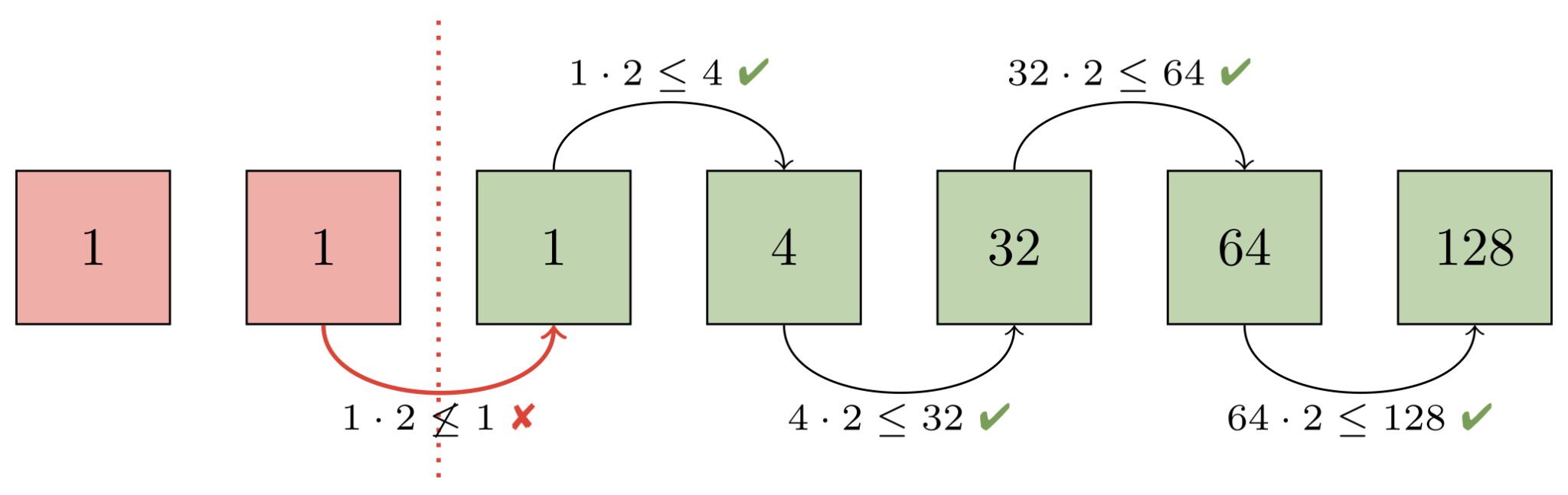
Here, the progression is broken between the second and third pack. That’s because both of those packs each have the same number of objects (in this case, just one). Git then decides that at least the first two packs will be contained in a new pack which is designed to restore the geometric progression. It then needs to figure out how many larger packs must also get rolled up in order to maintain the progression:
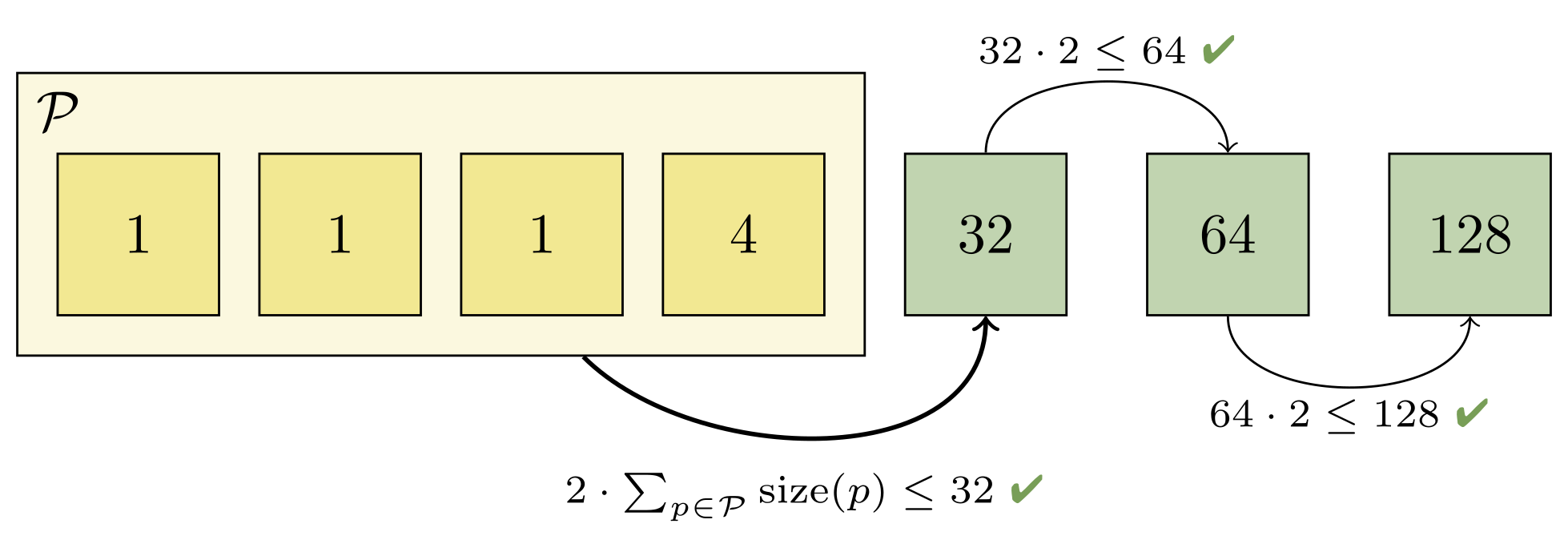
Combining the first two packs would give us two objects, which would still be too large to fit into the progression (since the next largest pack only has one object). But rolling up the first four packs is sufficient, since the fifth pack contains more than twice as many objects as the first four packs combined:
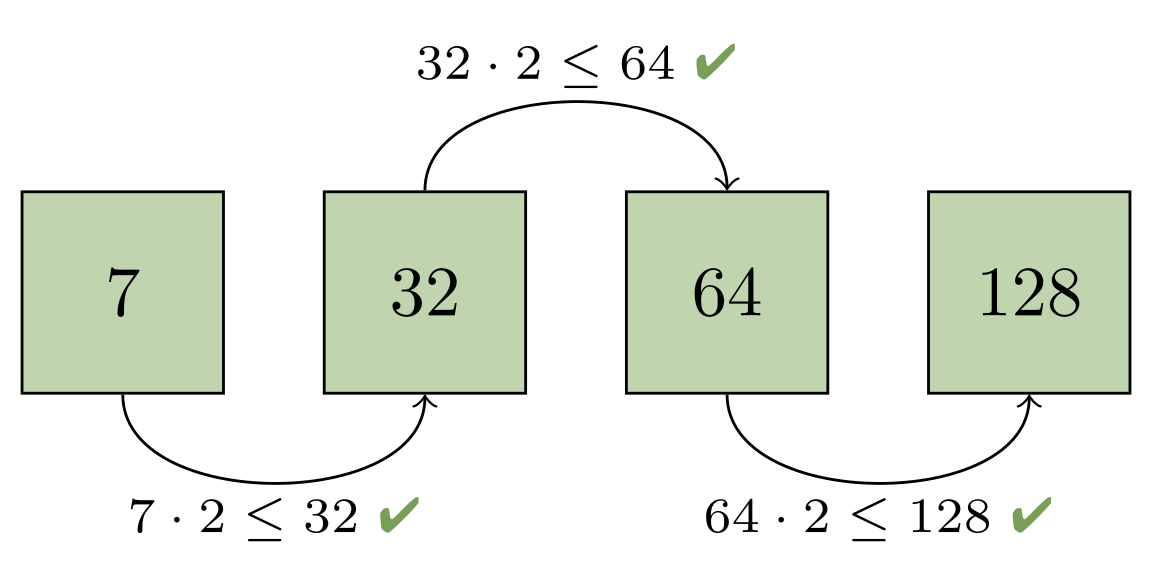
You can try this out yourself by comparing the pack sizes on a repository on your laptop before and after geometric repacking with the following script:
$ packsizes() {
find .git/objects/pack -type f -name '*.pack' |
while read pack; do
printf "%7d %s\n" \
"$(git show-index < ${pack%.pack}.idx | wc -l)" "$pack"
done | sort -rn
}
$ packsizes # before
$ git repack --geometric=2 -d
$ packsizes # after
We have also contributed patches to write the new on-disk reverse index format for multi-pack indexes. This format will ultimately be used to power multi-pack bitmaps by allowing Git to map bit positions back to objects in a multi-pack index.
Together, these two features will make it possible to cover the objects in the resulting packs with a reachability bitmap, even when there’s more than one pack remaining. Those patches are still being polished and reviewed, but expect an update from us when they’re incorporated into a release.
merge-ort: a new merge strategy
When Git performs a merge between two branches, it uses one of several “strategy” backends to resolve the changes. The original strategy is simply called resolve and does a standard three-way merge. But that default was replaced early in Git’s history by merge-recursive, which had two important advantages:
- In the case of “criss-cross” merges (where there is not a single
common point of divergence between two branches), the strategy
performs a series of merges (recursively, hence the name) for each
possible base. This can resolve cases for which theresolve
strategy would produce a conflict. -
It detects file-level renames along each branch. A file that was
modified on one side but renamed on the other will have its
modifications applied to the renamed destination (rather than
producing a very confusing conflict).
merge-recursive served well as Git’s default for many years, but it had a few shortcomings. It was originally written as an external Python script which used Git’s plumbing commands to examine the data. This was later rewritten in C, which provided a speed boost. But its code organization and data structures still reflected its origins: it still operated primarily on Git’s “index” (the on-disk area where changes are collected for new commits) and the working tree.
This resulted in several bugs over the years around tricky corner cases (for example, this one or some of these).
merge-recursive‘s origins also made it harder to optimize and extend the code. Merge time isn’t a bottleneck in most workflows, but there are certainly large cases (especially involving renames) where merge-recursive could be very slow. Likewise, the merge backend is used for many operations that combine two sets of changes. A cherry-pick or rebase operation may perform a series of merges, and speeding them up has a noticeable effect.
The merge-ort strategy is a from-scratch rewrite with the same concepts (recursion and rename-detection), but solving many of the long-standing correctness and performance problems. The result is much faster. For a merge (but a large, tricky one containing many renames), merge-ort gains over a 500x speedup. For a series of similar merges in a rebase operation, the speedup is over 9000x (because merge-ort is able to cache and reuse some computation common to the merges). These cases were selected as particularly bad for the merge-recursive algorithm, but in our testing of typical cases we find that merge-ort is always a bit faster than merge-recursive. The real win is that merge-ort consistently performs at that fast speed while merge-recursive has high variance.
On top of that, the resulting code is cleaner and easier to work with. It fixes some known bugs in merge-recursive. It’s more careful about not accessing unchanged parts of the tree, meaning that people working with partial clones should be able to complete more merges without having to download extra objects. And because it doesn’t rely on the index or working tree while performing the merge, it will open up new opportunities for tools like git log to show merges (for example, a diff between the vanilla merge result and the final committed state, which shows how the author resolved any conflicts).
The new merge-ort is likely to become the default strategy in a future version of Git. In the meantime, you can try it out by running git merge -s ort or setting your pull.twohead config to ort (despite the name, this is used for any merge, not just git pull). You might not see all of the same speedups yet; some of them will require changes to other parts of Git (for example, rebase helping pass the cached data between each individual merge).
Rather than link to the source commits, of which there are over 150 spread across more than a dozen branches, check out this summary from the author on the mailing list. Or if you want to go in-depth, check out his series of blog posts diving into the rationale and the details of various optimizations:
part 1
part 2
part 3
part 4
part 5
All that
Per our usual style, we like to cover two or three items from recent releases in detail, and then a dozen or so smaller topics in lesser detail. Now that we’ve gotten the former out of the way, here’s a selection of interesting changes in Git 2.32 and 2.33:
- You might have used
git rev-listto drive Git’s history traversal machinery.
It can be really useful when scripting, especially if you need to list the
commits/objects between two endpoints of history.git rev-listhas a very handy--prettyflag which allows it to format the
commits it encounters.--prettycan display information about a commit
(such as its author, author date, hash, parts of its message, and so on). But it can be difficult to use when scripting. Say you want the list of days that you wrote commits. You might think to run something like:$ git rev-list --format=%as --author=peff HEAD | head -4 commit 27f45ccf336d70e9078075eb963fb92541da8690 2021-07-26 commit 8231c841ff7f213a86aa1fa890ea213f2dc630be 2021-07-26(Here, we’re just asking
rev-listto show the author date of each commit
written by @peff.) But what are those lines interspersed withcommit?
That’s due to a historical quirk whererev-listfirst writes a line
containingcommit <hash>before displaying a commit with--pretty.
In order to keep backwards compatibility with existing scripts, the
quirk must remain.In Git 2.33, you can specify
--no-commit-headerto opt out of this
historical design decision, which makes scripting the above much easier:
[source]
-
Here’s a piece of Git trivia: say you wanted to list all blobs smaller than 200 bytes. You might consider using
rev-list‘s--filterfeature (the same mechanism that powers partial clones) to accomplish this. But what would you expect the following to print?$ git rev-list --objects --no-object-names \ --filter=blob:limit=200 v2.32.0..v2.33.0 \ | git cat-file --batch-check='%(objecttype)' | sort -u(In this example, we’re asking
rev-listto list all objects introduced
since version 2.32, filtering all blobs which are larger than 200 bytes.
Then, we askcat-fileto print out the types of all of those objects and
list the unique values).If you expected just “blob,” you’d be wrong! The
--filter=blob:limit=200
only filters blobs. It doesn’t stoprev-listfrom printing non-blob objects.In Git 2.32, you can solve this problem by excluding the blobs with a new
--filter=object:type=<type>filter. Since multiple--filters are combined together by taking the union of their results, this does the trick:$ git rev-list --objects --no-object-names \ --filter=object:type=blob \ --filter=blob:limit=200 \ --filter-provided-objects v2.32.0..v2.33.0 \ | git cat-file --batch-check='%(objecttype)' | sort -u blob(Here,
--filter-provided-objectsallowsrev-listto apply the same
filters to the tips of its traversal, which are exempt from filtering by
default).[source]
-
You might be aware of
git log‘s “decorate” feature, which adds output to
certain commits indicating which references point at them. For example:$ git log --oneline --decorate | head -1 2d755dfac9 (HEAD -> master, tag: v2.33.0-rc1, origin/master, origin/HEAD) Git 2.33-rc1By default, Git loads these decorations if the output is going to a terminal or if
--decoratewas given. But loading these decorations can be wasteful in examples like these:$ git log --graph --decorate --format='%h %s' | head -1 2d755dfac9 Git 2.33-rc1Here, Git would have wasted time loading all references since
--decorate
was given but its--formatdoesn’t cause any decoration information to be
written to the output.Git 2.33 learned how to detect if loading reference decorations will be useful (if they will show up in the output at all), and it optimizes the loading process to do as little work as possible even when we are showing decorations, but the decorated object does not appear in the output.
[source]
-
Speaking of
git log --formatplaceholders, Git 2.32 comes with a couple of
new ones. You can now display the author and committer date in the “human” format (which we talked about when it was introduced back in Git 2.21) with%ahand%ch.The new
%(describe)placeholder makes it possible to include the output of
git describealongside commits displayed in the log. You can use%(describe)to get the bare output ofgit describeon each line, or you can write%(describe:match=<foo>,exclude=<bar>)to control the--matchand--excludeoptions. -
Have you ever been working on a series of patches and realized that you
forgot to make a change a couple of commits back? If you have, you might
have been tempted toresetback to that point, make your changes, and then
cherry-pickthe remaining commits back on top.There’s a better way: if you make changes directly in your working copy
(even after you wrote more patches on top), you can make a special “fixup”
commit with thegit commit --fixupoption. This option creates a new
commit with the changes that you meant to apply earlier. Then, when you
rebase, Git automatically sequences the fixup commit in the right place and
squashes its contents back where you originally wanted them.But what if instead of changing the contents of your patch, you wanted to
change the log message itself? In Git 2.32,git commitlearned a new
--fixup=(amend|reword):<commit>option, which allows you to tweak the
behavior of--fixup. With--fixup=amend, Git will replace the log
message and the patch contents with your new one, all without you having to
pause your workflow to rebase.
If you use
--fixup=rewordinstead, you can tell Git to just replace the
log message while leaving the contents of the reworded patch untouched.[source]
-
You might be familiar with Git’s “trailers” mechanism, the structured
information that can sometimes appear at the end of a commit. For example, you might have seen trailers used to indicate the Developer’s Certificate of Origin at the end of a commit withSigned-off-by. Or perhaps you have seen projects indicate who reviewed what withReviewed-by.These trailers are typically written by hand when crafting a commit message
in your editor. But now Git can insert these trailers itself via the new
--trailerflag when runninggit commit. Trailers are automatically
inserted in the right place so that Git can parse them later on. This can be
especially powerful with the new--fixupoptions we just talked about. For
example, to add missing trailers to a commit,foo:$ git commit --no-edit \ --fixup=reword:foo \ --trailer='Signed-off-by=Mona Lisa Octocat <mona@github.com>' $ EDITOR=true git rebase -i --autosquash foo^[source]
-
Here’s the first of two checkout-related tidbits. Git uses the
git checkoutprogram to update your working copy (that is, the actual files on disk that you read/edit/compile) to match a particular state in history. Until very recently,git checkoutworked by creating, modifying, or removing files and directories one-by-one.When spinning-disk drives were more common, any performance improvement that
could be had by parallelizing this process would have been negligible, since
hard-disk drives are more frequently I/O-bound than more modern solid-state
and NVMe-based drives.(Of course, this is a little bit of an over-simplification: sometimes having
more tasks gives the I/O scheduler more items to work with, which actually
can help most on a spinning disks, since requests can be ordered by platter
location. It’s for this reason that Git refreshes the index using parallel
lstat()threads.)In Git 2.32,
git checkoutlearned how to update the working copy in
parallel by dividing the updates it needs to execute into different groups,
then delegating each group to a worker process. There are two knobs to
tweak:checkout.workersconfigures how many workers to use when updating the
tree (and you can use ‘0’ to indicate that it should use as many workers
as there are logical CPU cores).-
checkout.thresholdForParallelismconfigures how many updates are
necessary before Git kicks in the parallel code paths over the
sequential ones.
Together, these can provide substantial speed-ups when checking out repositories in different environments, as demonstrated here.
-
In an earlier blog post, Derrick Stolee talked about sparse checkouts. The goal of sparse checkout is to make it feel like the repository you’re working in is small, no matter how large it actually is.
Even though sparse checkouts shrink your working copy (that is, the number of files and directories which are created on disk), the index–the data structure Git uses to create commits–has historically tracked every file in the repository, not just those in your sparse checkout. This makes operations that require the index slow in sparse checkouts, even when the checkout is small, since Git has to compute and rewrite the entire index for operations which modify the index.
Git 2.32 has updated many of the index internals to only keep track of files in the sparse checkout and any directories at the boundary of the sparse checkout when operating in cone mode.
Different commands that interact with the index each have their own
assumptions about how the index should work, and so they are in the process
of being updated one-by-one. So far,git checkout,git commit, andgithave been updated, and more commands are coming soon.
statusYou can enable the sparse index in your repository by enabling the
index.sparseconfiguration variable. But note, while this feature is still
being developed it’s possible that Git will want to convert the sparse index
to a full one on the fly, which can be slower than the original operation you were performing. In future releases, fewer commands will exhibit this behavior until all index-related commands are converted over. -
Here’s a short and sweet one from 2.32: a new
SECURITY.mddocument was introduced to explain how to securely report vulnerabilities in Git. Most importantly, the email address of the security-focused mailing list (git-security@googlegroups.com) is listed more prominently. (For the extra-curious, the details of how embargoed security releases are coordinated and distributed are covered as well.)[source]
Finally, a number of bitmap-related optimizations were made in the last couple
of releases. Here are just a few:
- When using reachability bitmaps to serve, say, a fetch request, Git marks
objects which the client already has as “uninteresting,” meaning that they
don’t need to be sent again. But until recently, if a tag was marked as
uninteresting, the object being pointed at was not also marked as
uninteresting.Because the haves and wants are combined with an
AND NOT, this bug didn’t
impact correctness. But it can cause Git to waste CPU cycles since it can
cause full-blown object walks when the objects that should have been marked
as uninteresting are outside of the bitmap. Git 2.32 fixes this bug by
propagating the uninteresting status of tags down to their tagged objects.[source]
-
Some internal Git processes have to build their own reachability bitmaps on
the fly (like when an existing bitmap provides complete coverage
up to the most recent branches and tags, so a supplemental bitmap must be
generated and thenOR‘d in). When building these on-the-fly bitmaps, we
can avoid traversing into commits which are already in the bitmap, since we
know all of the objects reachable from that commit will also be in the
bitmap, too.But we don’t do the same thing for trees. Usually this isn’t a big deal.
Root trees are often not shared between multiple commits, so the
walk is often worthwhile. But traversing into shared sub-trees is wasteful
if those sub-trees have already been seen (since we know all of their
reachable objects have also been seen).Git 2.33 implements the same optimization we have for skipping already-seen
commits for trees, too, which has provided some substantial speed-ups,
especially for server-side operations.[source]
-
When generating a pack while using reachability bitmaps, Git will try to
send a region from the beginning of an existing packfile more-or-less
verbatim. But there was a bug in the “Enumerating objects” progress meter
that caused the server to briefly flash the number of reused objects and
then reset the count back to zero before counting the objects it would
actually pack itself.This bug was somewhat difficult to catch or notice because the pack reuse
mechanism only recently became more aggressive, and because you have to see it at exactly the right moment in your terminal to notice.But regardless, this bug has been corrected, so now you’ll see an accurate
progress meter in your terminal, no matter how hard you stare at it.[source]
…And a bag of chips
That’s just a sample of changes from the latest couple of releases. For more, check out the release notes for 2.32 and 2.33, or any previous version in the Git repository.
The post Highlights from Git 2.33 appeared first on The GitHub Blog.
Securing your GitHub account with two-factor authentication
16 Aug 2021, 6:00 pm
We’ve invested a lot in making sure that GitHub’s developer communities have access to the latest technology to protect their accounts from compromise by malicious actors. Some of these investments include verified devices, preventing the use of compromised passwords, WebAuthn support, and supporting security keys for SSH Git operations. These security features make it easier for developers to have strong account authentication on the platform, and today, we’re excited to share a few updates in this area.
No more password-based authentication for Git operations
In December, we announced that beginning August 13, 2021, GitHub will no longer accept account passwords when authenticating Git operations and will require the use of strong authentication factors, such as a personal access token, SSH keys (for developers), or an OAuth or GitHub App installation token (for integrators) for all authenticated Git operations on GitHub.com. With the August 13 sunset date behind us, we no longer accept password authentication for Git operations.
Enabling two-factor authentication (2FA) on your GitHub account
If you have not done so already, please take this moment to enable 2FA for your GitHub account. The benefits of multifactor authentication are widely documented and protect against a wide range of attacks, such as phishing. There are a number of options available for using 2FA on GitHub, including:
- Physical security keys, such as YubiKeys
- Virtual security keys built-in to your personal devices, such as laptops and phones that support WebAuthn-enabled technologies, like Windows Hello or Face ID/Touch ID
- Time-based One-Time Password (TOTP) authenticator apps
- Short Message Service (SMS)
While SMS is available as an option, we strongly recommend the use of security keys or TOTPs wherever possible. SMS-based 2FA does not provide the same level of protection, and it is no longer recommended under NIST 800-63B. The strongest methods widely available are those that support the emerging WebAuthn secure authentication standard. These methods include physical security keys as well as personal devices that support technologies such as Windows Hello or Face ID/Touch ID. We are excited and optimistic about WebAuthn, which is why we have invested early and will continue to invest in it at GitHub.
Commit verification with your security key
After securing your account with a security key, there’s more you can do with them. You can also digitally sign your git commits using a GPG key stored on your security key. Here is a detailed configuration guide for setting up your YubiKey with GitHub for commit verification and for SSH-based authentication. We’ve also partnered with Yubico to create a step-by-step video guide to help you enable your security key for SSH keys and commit verification.
Getting a security key
 Lastly, in 2015, we announced our support of Universal 2 Factor Authentication and created GitHub branded YubiKeys to mark the occasion. We thought it was fitting for this moment to make another batch with Yubico. As we continue our efforts to secure GitHub and the developer communities that depend on it, we are once again offering branded YubiKey 5 NFC and YubiKey 5C NFC keys! Get yours while supplies last at The GitHub Shop.
Lastly, in 2015, we announced our support of Universal 2 Factor Authentication and created GitHub branded YubiKeys to mark the occasion. We thought it was fitting for this moment to make another batch with Yubico. As we continue our efforts to secure GitHub and the developer communities that depend on it, we are once again offering branded YubiKey 5 NFC and YubiKey 5C NFC keys! Get yours while supplies last at The GitHub Shop.

The post Securing your GitHub account with two-factor authentication appeared first on The GitHub Blog.
What’s new from GitHub Changelog? July 2021 Recap
13 Aug 2021, 12:15 am
What was big in July?
Security is a topic that can feel daunting at times, but it doesn’t have to. The security team at GitHub has been working to streamline the processes for discovering, reporting, and fixing common vulnerabilities through features such as GitHub Security Advisories, Dependency Graph, Dependabot Alerts, and Dependabot Security Updates. And, in July, we brought all of these supply chain security features to the Go community.
Literally everything we shipped
General updates
You can now set an expiration date on new or existing personal access tokens! GitHub will send you an email when it’s time to renew a token that’s about to expire. A new response header, (GitHub-Authentication-Token-Expiration) indicates the expiration date, which you can use in scripts to (for example) log a warning message as the date approaches.
For anyone with an academic bent: If you add a CITATION.cff file to your repository, GitHub will now parse your information into APA and BibTeX citation formatting that can be copied by academics who cite your work. Check out the documentation for how to add a CITATION.cff file. We think it’s pretty cool!
New to GitHub.com? Welcome! We’ve redesigned the onboarding experience for new accounts.
GitHub Actions
In April, we shipped an update for GitHub Actions that required maintainers to approve Actions runs for first-time contributors. Based on user feedback, you can now configure this behavior at the repository, organization, or enterprise level.

Want to run Node.js projects faster on GitHub Actions? Enable dependency caching on the setup-node action! setup-node supports caching from both npm and yarn package managers. If you’ve got questions, join us in the GitHub Support Community discussion.
- uses: actions/setup-node@v2
with:
node-version: '14'
cache: npm
GitHub Discussions
Use a new beta feature to translate GitHub Discussions content into Korean, Brazilian Portuguese, and English. Click the overflow menu beside any discussion comment and you’ll see a link to translate it to your preferred language (based on the default language configuration of your web browser). Support for more languages coming soon. Be sure to leave feedback!
GitHub Releases
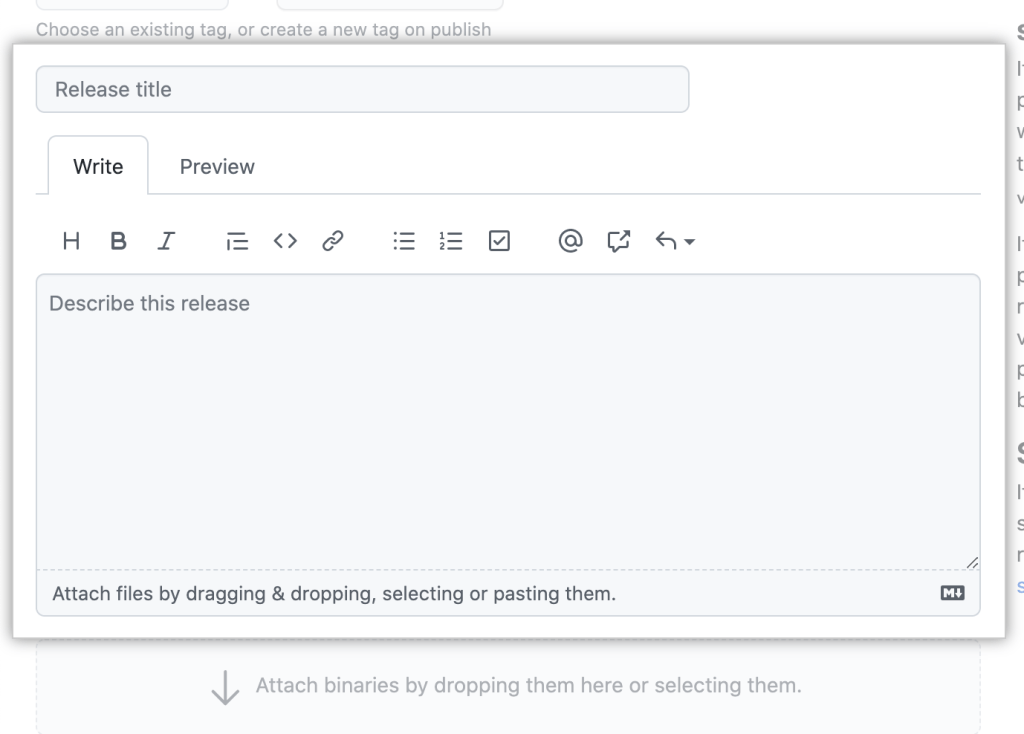
Creating or editing a release in a GitHub repository? We added a text-editing toolbar to the markdown editor! Show off your excitement with bold and italics, or learn more about managing releases in our documentation.
GitHub Security
The CodeQL team had another busy month. If you are using CodeQL for your code scanning, here’s what happened in July:
- CodeQL package manager is now in public beta! CodeQL packages can contain CodeQL queries and CodeQL libraries. If you upload a pack to the package registry on GitHub.com, CodeQL will automatically fetch any required dependencies when running queries from the pack. See the Changelog entry for more functionality details.
- Your CodeQL security alerts now display severity levels:
critical,high,medium, orlow. CodeQL automatically calculatessecurity-severityand assigns an exact numerical score to each security query. The Changelog entry walks you through this scoring, plus how to view alerts and customize settings.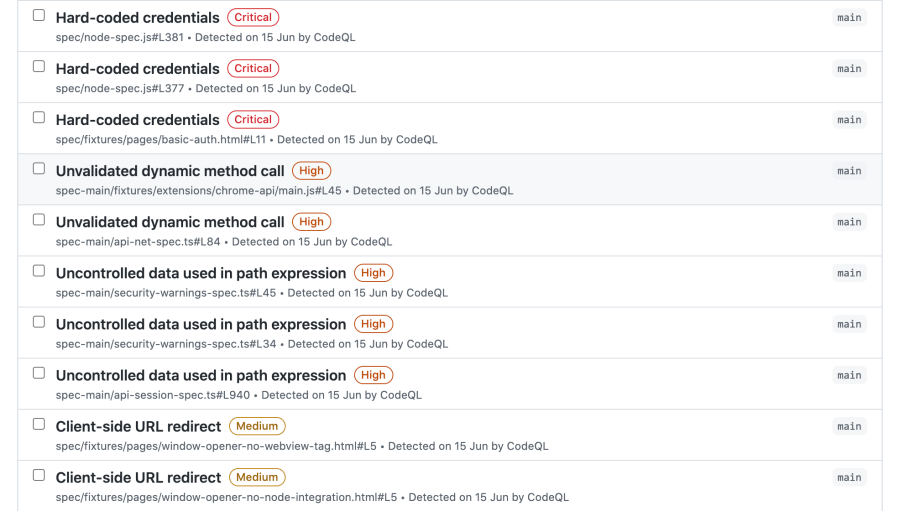
- We’ve improved the depth of CodeQL’s analysis by adding support for more libraries and frameworks and increasing the coverage of our existing library and framework models for several languages (C++, JavaScript, Python, and Java). See the full list of additions.
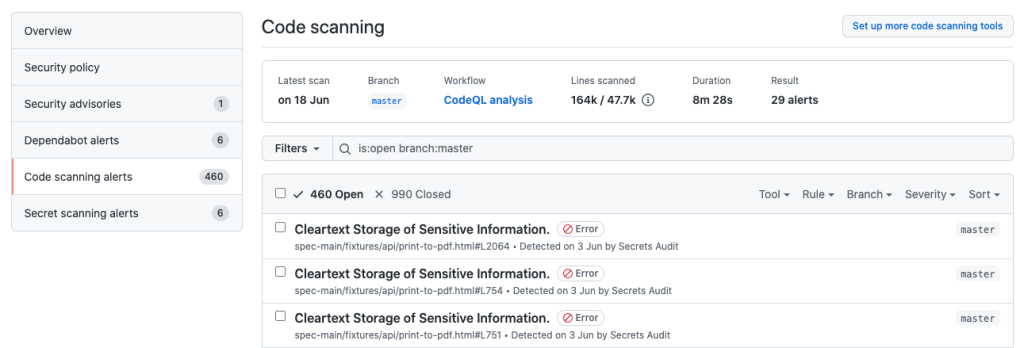
Speaking of code scanning, we’ve made some changes to how we display scan results. Your repository’s security view shows alerts for the default branch of your repository (under “Code scanning alerts”), but you can use the branch filter to display alerts on non-default branches, and we’ve extended the search syntax so that you can use a more simplified version of the previous queries.
A couple more security updates:
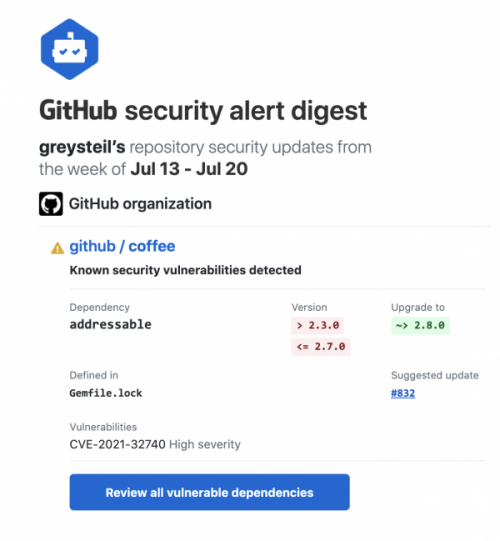
We’re happy to welcome Linear and Ionic as GitHub secret scanning integrators. We now scan for their developer tokens! Learn more about secret scanning or about joining our partner program.
In June, security alert notifications became opt-in on a per-repository basis. Security alert digest emails will now respect these settings!
GitHub Sponsors
If you have a GitHub Sponsors profile, you can now set custom donation amounts as an option both for recurring sponsorships and for one-time sponsorships.

Maybe you haven’t joined GitHub Sponsors because you aren’t sure how to set up a business bank account or fiscal host for your organization? We’re happy to announce that organizations can now join GitHub Sponsors using a personal bank account, too!
Take a look at our public roadmap for what’s coming next, follow GitHub Changelog on Twitter, and check back on the GitHub Blog for another recap next month.
The post What’s new from GitHub Changelog? July 2021 Recap appeared first on The GitHub Blog.
Seamless teaching and learning through GitHub Classroom and Visual Studio Code
12 Aug 2021, 6:00 pm
Students learning computer science are met with numerous challenges beyond just the course material. Complex tooling, confusing setup, and overwhelming systems can frustrate students and teachers alike before even starting their coursework.
To explore these challenges, we have met with numerous students and professors around the world to explore these challenges.
- Real-world tools assume you’re a pro: Professional developers like to customize their tools, so environments support advanced customizations, without always showing the quick and easy getting started route.
- Educators are oversubscribed: Teachers need to scale without sacrificing quality.
- Students are overwhelmed without easy access to help: Friction with tools often causes students to drop their intro classes.
As a result, we’re excited to bring together Visual Studio Code and GitHub Classroom for a seamless teaching and learning experience with our latest extension!
Visual Studio Code extensions let you add additional tooling to your base installation to best support your workflow. This GitHub Classroom extension for Visual Studio Code provides a simplified introduction to Git, GitHub Classroom, and Visual Studio Code, while providing students with key GitHub Classroom capabilities, like integrated autograding and live collaboration.
Learn with Visual Studio Code

GitHub Classroom aims to make it as simple as possible for students to get started with GitHub. As a part of this effort, our extension for Visual Studio Code provides a student-centric experience focused on making it even easier for students to manage their assignments.
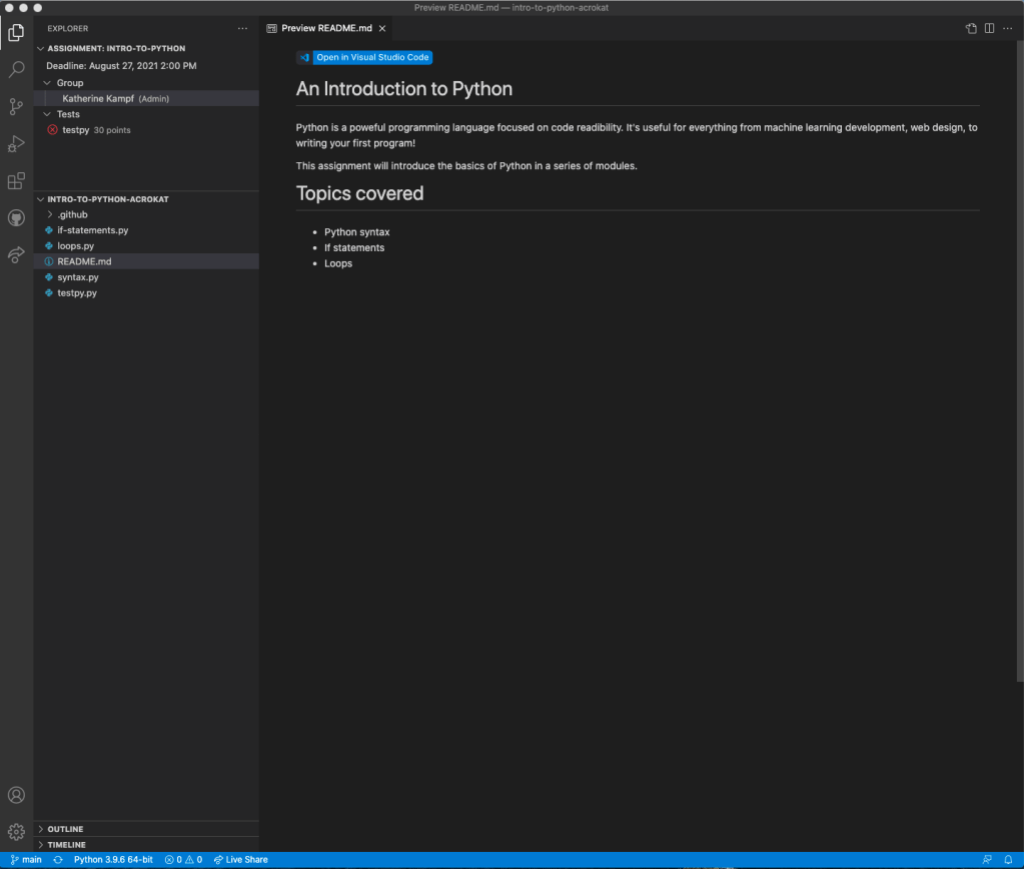
Students can either self-install the extension and import their assignments, or use the one-click “Open in Visual Studio Code” experience from any assignment in which a teacher enables Visual Studio Code as an editor.
Once in the extension, students can browse their code, edit, and commit changes, submit their assignment, and see their integrated autograding results. Also, for group projects and office hours, students can use Microsoft Live Share to collaborate with their group members and/or TAs!
Read more on how to get started in our docs!
Teach with Visual Studio Code
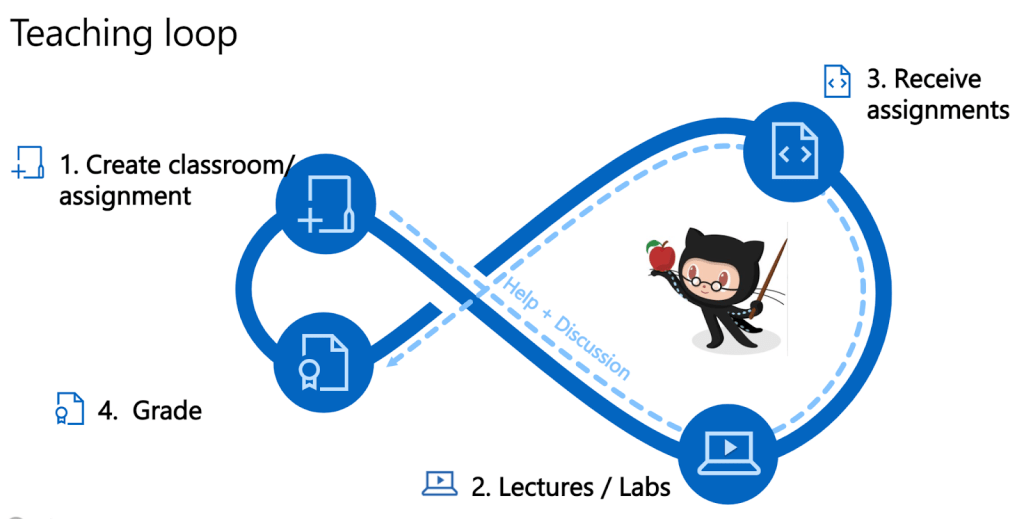
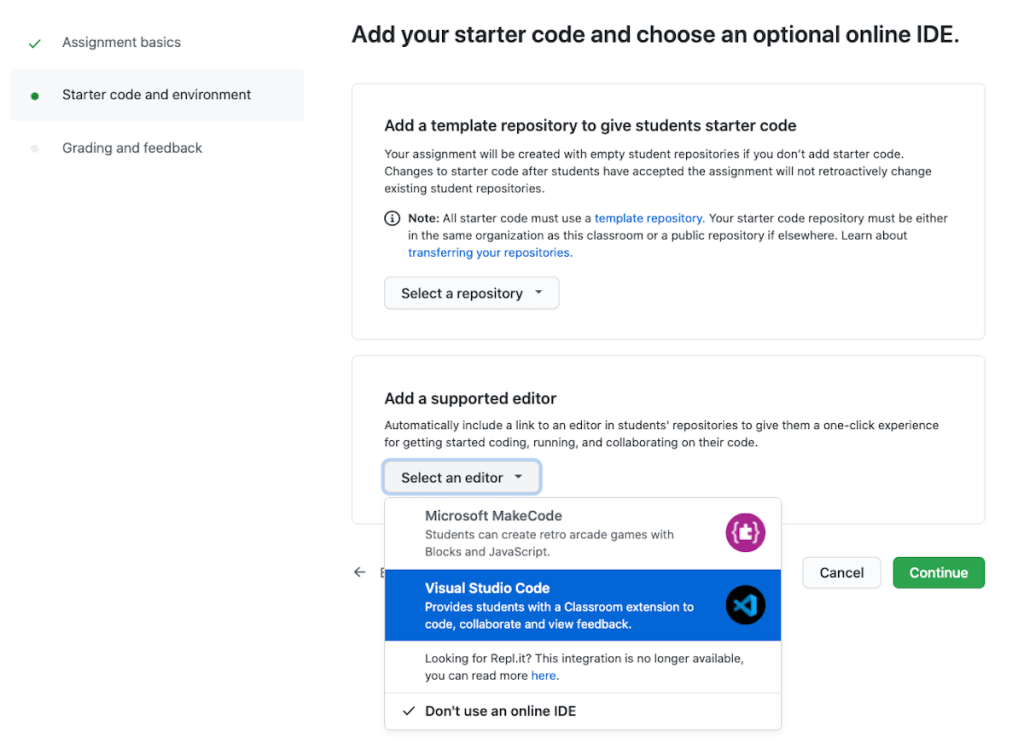
Rather than spending a lot of time in office hours setting up student machines, we’ve added an option for teachers to include a magic “Open in Visual Studio Code” button on student assignments. Once a student clicks this button, we will handle installing Visual Studio Code and the extension if needed. It will then open up directly to that assignment! Magic, if we do say so ourselves. 
To utilize Visual Studio Code as the preferred editor for your assignment, select the Visual Studio Code option when creating a new assignment.
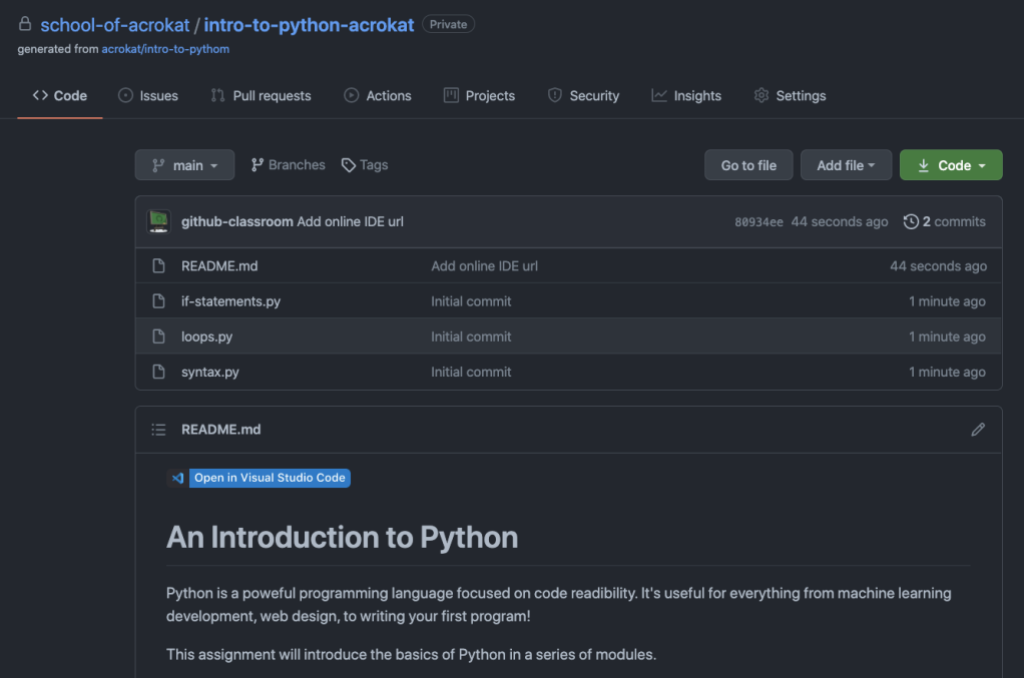
Now, all student repositories will include the badge below!
Get started today
As a student or teacher, you can install the extension today via the Visual Studio Code Marketplace! Teachers, you can also experiment with creating Visual Studio Code enabled assignments by creating a new assignment via GitHub Classroom.
The post Seamless teaching and learning through GitHub Classroom and Visual Studio Code appeared first on The GitHub Blog.
GitHub’s Engineering Team has moved to Codespaces
11 Aug 2021, 4:00 pm
Today, GitHub is making Codespaces available to Team and Enterprise Cloud plans on github.com. Codespaces provides software teams a faster, more collaborative development environment in the cloud. Read more on our Codespaces page.
The GitHub.com codebase is almost 14 years old. When the first commit for GitHub.com was pushed, Rails was only two years old. AWS was one. Azure and GCP did not yet exist. This might not be long in COBOL time, but in internet time it’s quite a lot.
Over those 14 years, the core repository powering GitHub.com (github/github) has seen over a million commits. The vast majority of those commits come from developers building and testing on macOS.

But our development platform is evolving. Over the past months, we’ve left our macOS model behind and moved to Codespaces for the majority of GitHub.com development. This has been a fundamental shift for our day-to-day development flow. As a result, the Codespaces product is stronger and we’re well-positioned for the future of GitHub.com development.
The status quo
Over the years, we’ve invested significant time and effort in making local development work well out of the box. Our scripts-to-rule-them-all approach has presented a familiar interface to engineers for some time now—new hires could clone github/github, run setup and bootstrap scripts, and have a local instance of GitHub.com running in a half-day’s time. In most cases things just worked, and when they didn’t, our bootstrap script would open a GitHub issue connecting the new hire with internal support. Our #friction Slack channel—staffed by helpful, kind engineers—could debug nearly any system configuration under the sun.

Yet for all our efforts, local development remained brittle. Any number of seemingly innocuous changes could render a local environment useless and, worse still, require hours of valuable development time to recover. Mysterious breakage was so common and catastrophic that we’d codified an option for our bootstrap script: --nuke-from-orbit. When invoked, the script deletes as much as it responsibly can in an attempt to restore the local environment to a known good state.
And of course, this is a classic story that anyone in the software engineering profession will instantly recognize. Local development environments are fragile. And even when functioning perfectly, a single-context, bespoke local development environment felt increasingly out of step with the instant-on, access-from-anywhere world in which we now operate.
Collaborating on multiple branches across multiple projects was painful. We’d often find ourselves staring down a 45-minute bootstrap when a branch introduced new dependencies, shipped schema changes, or branched from a different SHA. Given how quickly our codebase changes (we’re deploying hundreds of changes per day), this was a regular source of engineering friction.
And we weren’t the only ones to take notice—in building Codespaces, we engaged with several best-in-class engineering organizations who had built Codespaces-like platforms to solve these same types of problems. At any significant scale, removing this type of productivity loss becomes a very clear productivity opportunity, very quickly.

Development infrastructure
In the infrastructure world, industry best practices have continued to position servers as a commodity. The idea is that no single server is unique, indispensable, or irreplaceable. Any piece could be taken out and replaced by a comparable piece without fanfare. If a server goes down, that’s ok! Tear it down and replace it with another one.
Our local development environments, however, are each unique, with their own special quirks. As a consequence, they require near constant vigilance to maintain. The next git pull or bootstrap can degrade your environment quickly, requiring an expensive context shift to a recovery effort when you’d rather be building software. There’s no convention of a warm laptop standing by.
But there’s a lot to be said for treating development environments as our own—they’re the context in which we spend the majority of our day! We tweak and tune our workbench in service of productivity but also as an expression of ourselves.
With Codespaces, we saw an opportunity to treat our dev environments much like we do infrastructure—a commodity we can churn—but still maintain the ability to curate our workbench. Visual Studio Code extensions, settings sync, and dotfiles repos bring our environment to our compute. In this context, a broken workbench is a minor inconvenience—now we can provision a new codespace at a known good state and get back to work.
Adopting Codespaces
Migrating to Codespaces addressed the shortcomings in our existing developer environments, motivated us to push the product further, and provided leverage to improve our overall development experience.
And while our migration story has a happy ending, the first stages of our transition were… challenging. The GitHub.com repository is almost 13 GB on disk; simply cloning the repository takes 20 minutes. Combined with dependency setup, bootstrapping a GitHub.com codespace would take upwards of 45 minutes. And once we had a repository successfully mounted into a codespace, the application wouldn’t run.
Those 14 years of macOS-centric assumptions baked into our bootstrapping process were going to have to be undone.
Working through these challenges brought out the best of GitHub. Contributors came from across the company to help us revisit past decisions, question long-held assumptions, and work at the source-level to decouple GitHub development from macOS. Finally, we could (albeit very slowly) provision working GitHub.com codespaces on Linux hosts, connect from Visual Studio Code, and ship some work. Now we had to figure out how to make the thing hum.
45 minutes to 5 minutes
Our goal with Codespaces is to embrace a model where development environments are provisioned on-demand for the task at hand (roughly a 1:1 mapping between branches and codespaces.) To support task-based workflows, we need to get as close to instant-on as possible. 45 minutes wasn’t going to meet our task-based bar, but we could see low-hanging fruit, ripe with potential optimizations.
Up first: changing how Codespaces cloned github/github. Instead of performing a full clone when provisioned, Codespaces would now execute a shallow clone and then, after a codespace was created with the most recent commits, unshallow repository history in the background. Doing so reduced clone time from 20 minutes to 90 seconds.
Our next opportunity: caching the network of software and services that support GitHub.com, inclusive of traditional Gemfile-based dependencies as well as services written in C, Go, and a custom build of Ruby. The solution was a GitHub Action that would run nightly, clone the repository, bootstrap dependencies, and build and push a Docker image of the result. The published image was then used as the base image in github/github’s devcontainer—config-as-code for Codespaces environments. Our codespaces would now be created at 95%+ bootstrapped.
These two changes, along with a handful of app and service level optimizations, took GitHub.com codespace creation time from 45 minutes to five minutes. But five minutes is still quite a distance from “instant-on.” Well-known studies have shown people can sustain roughly ten seconds of wait time before falling out of flow. So while we’d made tremendous strides, we still had a way to go.
5 minutes to 10 seconds
While five minutes represented a significant improvement, these changes involved tradeoffs and hinted at a more general product need.
Our shallow clone approach—useful for quickly launching into Codespaces—still required that we pay the cost of a full clone at some point. Unshallowing post-create generated load with distracting side effects. Any large, complex project would face a similar class of problems during which cloning and bootstrapping created contention for available resources.
What if we could clone and bootstrap the repository ahead of time so that by the time an engineer asked for a codespace we’d already done most of the work?
Enter prebuilds: pools of codespaces, fully cloned and bootstrapped, waiting to be connected with a developer who wants to get to work. The engineering investment we’ve made in prebuilds has returned its value many times over: we can now create reliable, preconfigured codespaces, primed and ready for GitHub.com development in 10 seconds.
New hires can go from zero to a functioning development environment in less time than it takes to install Slack. Engineers can spin off new codespaces for parallel workstreams with no overhead. When an environment falls apart—maybe it’s too far behind, or the test data broke something—our engineers can quickly create a new environment and move on with their day.
Increased leverage
The switch to Codespaces solved some very real problems for us: it eliminated the fragility and single-track model of local development environments, but it also gave us a powerful new point of leverage for improving GitHub’s developer experience.
We now have a wedge for performing additional setup and optimization work that we’d never consider in local environments, where the cost of these optimizations (in both time and patience) is too high. For instance, with prebuilds we now prime our language server cache and gem documentation, run pending database migrations, and enable both GitHub.com and GitHub Enterprise development modes—a task that would typically require yet another loop through bootstrap and setup.
With Codespaces, we can upgrade every engineer’s machine specs with a single configuration change. In the early stages of our Codespaces migration, we used 8 core, 16 GB RAM VMs. Those machines were sufficient, but GitHub.com runs a network of different services and will gladly consume every core and nibble of RAM we’re willing to provide. So we moved to 32 core, 64 GB RAM VMs. By changing a single line of configuration, we upgraded every engineer’s machine.

Codespaces has also started to steal business from our internal “review lab” platform—a production-like environment where we preview changes with internal collaborators. Before Codespaces, GitHub engineers would need to commit and deploy to a review lab instance (which often required peer review) in order to share their work with colleagues. Friction. Now we ctrl+click, grab a preview URL, and send it on to a colleague. No commit, no push, no review, no deploy — just a live look at port 80 on my codespace.
Command line
Visual Studio Code is great. It’s the primary tool GitHub.com engineers use to interface with codespaces. But asking our Vim and Emacs users to commit to a graphical editor is less great. If Codespaces was our future, we had to bring everyone along.
Happily, we could support our shell-based colleagues through a simple update to our prebuilt image which initializes sshd with our GitHub public keys, opens port 22, and forwards the port out of the codespace.

From there, GitHub engineers can run Vim, Emacs, or even ed if they so desire.
This has worked exceedingly well! And, much like how Docker image caching led to prebuilds, the obvious next step is taking what we’ve done for the GitHub.com codespace and making it a first-class experience for every codespace.
Reception
Change is hard, doubly so when it comes to development environments. Thankfully, GitHub engineers are curious and kind—and quickly becoming Codespaces superfans.
| I used codespaces yesterday while my dev environment was a little broken and I finished the entire features on codespaces before my dev env was done building lol ~@lindseyb My friends, I’m here to tell you I was a Codespaces skeptic before this started and now I am not. This is the way. I really was more productive with respect to the Rails part of my work this week than I think I ever have been before. Everything was just so fast and reliable. Whomever has worked on getting codespaces up and running, you enabled me to have an awesome first week! I do solemnly swear that never again will my CPU have to compile ruby from source. |
Codespaces are now the default development environment for GitHub.com. That #friction Slack channel that we mentioned earlier to help debug local development environment problems? We’re planning to archive it.
We’re onboarding more services and more engineers throughout GitHub every day, and we’re discovering new stories about the value Codespaces can generate along the way. But at the core of each story, you’ll discover a consistent theme that resonates with every engineer: I found a better tool, I’m more productive now, and I’m not going back.
The post GitHub’s Engineering Team has moved to Codespaces appeared first on The GitHub Blog.
August 2021 Campus Experts applications are open!
9 Aug 2021, 2:00 pm
GitHub Education is looking for the next generation of student community leaders. Are you building a community on your campus? If so, we want to help! Whether you’re growing an established community or starting from scratch, the GitHub Campus Experts Program will provide you with the tools and resources you need to make a meaningful impact on your campus.
The GitHub Campus Expert application for the August 2021 generation is officially open. Are you eligible for the program? Campus Experts must be at least 18 years of age, a GitHub user for at least six months, and enrolled in a post-secondary formal education institution.
Apply to become a Campus Expert! Applications close August 29, 2021.
Why should you apply?
On-campus engagement looks different than it did last year. We know running events can be challenging with unstable internet connection, moderators on hand, and lagging live streams. That is why it’s even more important than ever to have the resources and tools you need to be effective and engaging.
From community leadership training to stickers and cheat sheets for events, the Campus Experts Program helps bridge the gap by providing all the tools and resources you need to organize extraordinary events and keep your community engaged. We know the impact student leaders have on their campus. Becoming a Campus Expert will allow you and your community to thrive.
New and improved application
If you applied in February 2021, you’ll notice that some of the questions have changed. These changes are based on applicant feedback. The new questions are meant to be more descriptive to help ensure the information we request is clear and concise. The questions now focus on how the program benefits will help you to build a stronger community, achieve your goals, and organize welcoming experiences for everyone.
Campus Experts come from a range of backgrounds but all have one thing in common: they are deeply passionate about technology, and we want to hear from all of you. We are proud to see the program grow from a small group of handpicked students in 2016 to what it is now: a global community of student leaders from more than 35 countries.
Ready to apply?
Fall semester is right around the corner. Make sure to submit your application by August 29, 2021. This is an opportunity for you to take your leadership and campus to the next level. As a Campus Expert, you’ll have access to GitHub Campus Experts training, resources, and support to excel in the activities you organize on your campus. We’ll reach out to all applicants on September 13, 2021, with an update on their application status and next steps.
Ready to become a Campus Expert? Read on for tips and tricks to make sure your application stands out.
 Before applying, browse the Campus Experts website, and learn about the program’s mission, the benefits, and hear the story of other students in the program. Think about how the program benefits can help solve a struggle your community is facing and increase impact. Let us know what makes your community unique, and don’t forget to be specific. Sign in to GitHub Global Campus and find who the closest Campus Expert is. Ask them about their experience in the program and how they have built or grew their community.
Before applying, browse the Campus Experts website, and learn about the program’s mission, the benefits, and hear the story of other students in the program. Think about how the program benefits can help solve a struggle your community is facing and increase impact. Let us know what makes your community unique, and don’t forget to be specific. Sign in to GitHub Global Campus and find who the closest Campus Expert is. Ask them about their experience in the program and how they have built or grew their community.Apply to become a GitHub Campus Expert before August 29
The post August 2021 Campus Experts applications are open! appeared first on The GitHub Blog.
Release Radar · Mid-year 2021 Edition
5 Aug 2021, 5:00 pm
It’s been a busy time of the year for our Hubbers (GitHub employees). We’ve been shipping products, getting ready for launches, and taking some much needed time off for the summer. Well, it’s summer for those US/UK-based Hubbers, but some of us are in Australia where it’s cold! While we’ve been launching awesome features like GitHub Issues and Desktop 2.9, our community has been shipping lots of new updates. These new releases include everything from world-changing tech to weekend hobbies. Here are some of our top staff picks from amazing open source projects that shipped major releases this June/July.
Terraform 1.0
This is an exciting one for the open source community. Terraform is now available to the general public. Terraform is a tool for building, changing, and versioning infrastructure safely and efficiently. Made by Hashicorp, Terraform is built to help you manage your workflows. Whilst Terraform has been around for a while, with over 100,000,000 downloads, Terraform 1.0 is a huge milestone for the team. Hashicorp has four requirements for a product to be released as Version 1.0: General Availability. The product must have been deployed broadly with many years of production, it has to have major use cases that are understood and supported, have a well defined user experience, and the technical architecture of the product must be mature and stable. Terraform met all these requirements and is now here for you. Download it now, or check out the Hashicorp blog for more info on Terraform GA.
PostgREST 8.0
Another huge one for the open source community is PostgREST. PostgREST serves a fully RESTful API from any existing PostgreSQL database. It’s fast, clean, and compliant. Version 8.0 of this product comes with a tonne of upgrades. There are a lot of added features such as allowing https status override, schema cache reloading, and config file loading. There’s no longer any down time when reloading the schema cache and there are now CLI options for debugging. And that’s not all. Read up on all the changes and bug fixes in the PostgREST release notes.
Cypress 8.0
As the web evolves (remember the days of monochrome, single page, Times New Roman websites?) so too does testing. Cypress is a tool for testing anything that would run in a browser. It’s fast and reliable, plus it’s available on Mac, Linux, and Windows. With version 8.0, the team made some changes to help ensure a consistent run experience across all browsers. The new update means when you test your product on the web, it will be run in a standard, default format. There’s also a few new features and the usual bug fixes. Read more about these changes and how to migrate your code to Cypress 8.0 on the Cypress docs page.
mitmproxy 7.0
Speaking of the web, if you want a free and open source HTTPS proxy that’s also interactive, mitmproxy should be your pick. The team just released Version 7.0, which comes with a new proxy core. This means lots of improvements and changes. Mitmproxy now supports proxying raw TCP connections and will accept HTTP/2 requests and forward them to the HTTP/1 server. Neat! There’s also the console UI, which is now available natively. Read up on all the changes that come with Mitmproxy 7.0 on the mitmproxy changelog.
rrweb 1.0
Understand your users’ experiences with rrweb. Rrweb records a web session and replays it with user interactions. It’s perfect for understanding UX, reproducing bugs, demoing your product, or collaborating in real time. This project is now generally available as Version 1.0. Congrats to the team on shipping their first major release.
Lottie Android 4.0
If you’ve ever tried using fancy Adobe effects in videos and transferring them to an app, you’ll know it’s super painful. Well, Lottie changes that. Now, you can create amazing animations and ship them right away. Lottie is a mobile library for Android and iOS. It parses Adobe After Effects animations, exports them as json files and renders them natively on mobile. With Lottie Android 4.0 comes the first stable release of Lottie Compose, which allows you to do all the fancy things with your json file. Fun fact, Lottie is made by Airbnb!
Husky 7.0
Who doesn’t love doggos? Husky improves your git commits with more “ woof“. We assume the “woof” here means linting your commit messages, running test, linting code, and more. Whenever you push your code, Husky supports all things git. Version 7.0 comes with some improved directory structure, updated CLI, and dropped support for Node 10—make sure you’re up to date. Check out more in the release notes.
woof“. We assume the “woof” here means linting your commit messages, running test, linting code, and more. Whenever you push your code, Husky supports all things git. Version 7.0 comes with some improved directory structure, updated CLI, and dropped support for Node 10—make sure you’re up to date. Check out more in the release notes.
Kratos 2.0
Like it’s namesake, Kratos helps you quickly build a bulletproof application from scratch. That’s definitely what the Greeks did right? Kratos is a Go framework for microservices. Version 2.0 comes with a lot of new commands, examples, and bug fixes. Read all about them in the Kratos release notes. Fun fact: this project’s name takes its inspiration from God of War the video game! That game, in turn, is based on Greek mythology—hence Kratos, the god of strength.
JavaScript Cookie 3.0
Did someone say cookies?  Not all cookies are bad for you, and JavaScript Cookie is one of those cookies that are good. This is a lightweight JavaScript API for handling cookies. It works in all browsers, with any characters. Version 3.0 has a lot of updates. They’ve also dropped support for older versions of Internet Explorer (IE 10 and below), as well as Node (Node 12 and below). Check out all the updates and changes on the JavaScript Cookie release notes.
Not all cookies are bad for you, and JavaScript Cookie is one of those cookies that are good. This is a lightweight JavaScript API for handling cookies. It works in all browsers, with any characters. Version 3.0 has a lot of updates. They’ve also dropped support for older versions of Internet Explorer (IE 10 and below), as well as Node (Node 12 and below). Check out all the updates and changes on the JavaScript Cookie release notes.
html2canvas 1.0
This is what it sounds like! html2canvas is a JavaScript HTML renderer that allows you to take screenshots of webpages. The script renderers the canvas as an image and reads the various elements in that image. This is the first release of html2canvas and you can download it right now. Congrats to the team on shipping the first release of their product!
React Native Camera 4.0
Do you use React Native and need a camera module? React Native Camera is the module for you. It’s a comprehensive module that supports photos, videos, face detection on mobile (Android and iOS), barcode scanning, and text recognition. Version 4.0 sees the migration to Google Machine Learning (ML) kit. Check out React Native Camera and try it out for yourself today. I hear the project is also looking for maintainers, so if you’re ever thought about getting into open source or maintaining a project, now is the time.
WebSockets 8.0
ws, or WebSockets have released a new version of ws, a Node.js library. It’s a simple and fast WebSocket client and server implementation. Version 8.0 has lots of breaking changes including UI changes to help developers debug even easier. The WebSocket constructor will provide SyntaxErrors based on a number of invalid protocols, helping you determine the cause of any issues. With this latest update, you can also migrate existing code by decoding the buffer explicitly, or closing connections manually. Plus, there’s the usual bug fix  . Check out all the changes on the WebSocket Changelog.
. Check out all the changes on the WebSocket Changelog.
BLAKE3 1.0
If you’re looking for a cryptographic hash function, look no further than BLAKE3. It’s fast, secure, and contains one algorithm with no variants. BLAKE3 contains three official implementations including the blake3 Rust crate, b3sum Rust crate, and C implementation. This is the first major release of BLAKE3 so massive congrats to the team on releasing version 1.0. Read more about this project on the BLAKE3 readme file.
TOAST UI Editor 3.0
Not everyone likes doing documentation. If you’re one of those people, you might like TOAST UI Editor. This editor allows you to edit Markdown files using text or WYSIWYG. There’s also the added benefit of syntax highlighting, scroll-sync, previews, and charts. With the release of 3.0, there are a lot of bug fixes, plus some dependency updates. Check out all the changes on the Editor Changelog.
Nest.js 8.0
There’s always a lot of talk about Node.js for these Release Radars, and this edition is no different. Nest.js is a progressive Node.js framework for building efficient and scalable server-side applications. It uses modern JavaScript and is built with TypeScript. Version 8.0 has lots of features, improvements, fixes, and more. New features include the addition of new classes and a RouterModule. Read about these new classes, fixes, dependencies, depreciations, and improvements on the Nest.js release notes.
Supabase Auth 2.0
Do you want an open source alternative to Firebase? Supabase is your answer. Supabase has just released Supabase Auth 2.0, which allows mobile login. As part of this new launch, users can now login using passwordless SMS based OTP with supabase-js or with the Auth API directly. Users can authenticate their Supabase by verifying OTPs, and using Phone Auth in conjunction with a password. Supabase already supports Twilio as an SMS provider with more options said to be on the way. If you want to know more about Supabase, check out our Open Source Friday chat with Paul Cobblestone:
June-July Release Radar
Well that’s all for this month’s top release picks. Congratulations to everyone who shipped a new release, whether it was version 1.0 or version 8.0. Keep up the great work everyone! If you’ve got a new release coming, we’d love to see it. Tag us when you share your release on social media, and we’ll keep an eye out. If you missed out our last Release Radar, check out the amazing community projects from May.
The post Release Radar · Mid-year 2021 Edition appeared first on The GitHub Blog.
GitHub Availability Report: July 2021
4 Aug 2021, 4:00 pm
In July, we experienced no incidents resulting in service downtime to our core services.
Please follow our status page for real time updates. To learn more about what we’re working on, check out the GitHub engineering blog.
The post GitHub Availability Report: July 2021 appeared first on The GitHub Blog.
15+ new code scanning integrations with open source security tools
28 Jul 2021, 4:01 pm
Last year, we released code scanning, a vulnerability detection feature in GitHub Advanced Security that’s also free on GitHub.com for public repositories. With code scanning, you can use GitHub CodeQL for static analysis, or you can choose from one of the many third-party integrations available in the GitHub Marketplace to execute security scans in your continuous integration pipeline and surface the results directly in GitHub. Today, we’re happy to announce more than 15 new integrations with open source security tools that broaden our language coverage to include PHP, Swift, Kotlin, Ruby, and more.
Below is a list of all the new integrations, with links to their GitHub Actions in the GitHub Marketplace. These integrations are brought to us by a number of key contributors from our open source community. Big thanks to @ajinabraham, @Moose0621, @GeekMasher, @Muglug, @GriffinMB, @jarlob, @presidentbeef, @A-Katopodis, @OwenRumney, @swinton and others for their contributions to the growing ecosystem of open source static analysis tools.
New open source scanner integrations
Mobile languages
Detekt is a static code analysis tool for the Kotlin programming language. A GitHub Action is available for Detekt, and a preconfigured workflow for Static Analysis Results Interchange Format (SARIF) upload is available in the GitHub user interface (UI) under the “Security” tab.
MobSF is an automated, all-in-one mobile application framework (Android/iOS Swift/Windows) for pen testing, malware analysis and security assessment that’s capable of performing static and dynamic analysis. With the help of @ajinabraham, MobSF now supports code scanning. Check out the GitHub Action or find it in the GitHub “Security” tab.
Big thanks to our own @Moose0621 and @GeekMasher for adding these popular tools for mobile applications! Kotlin and Swift support are forthcoming in CodeQL.
PHP
Psalm is an open source tool for finding security vulnerabilities in PHP supported by @Muglug and Vimeo. Try the Psalm GitHub Action with SARIF upload.
Elixir Phoenix Framework
Soblow is the security-focused static analyzer for the Elixir Phoenix Framework. @GriffinMB gave a helping hand by adding SARIF support and writing a GitHub Action.
Node JS
nodejsscan is a static security code scanner (SAST) for Node.js applications. @Ajinabraham added a GitHub Action and added it to the GitHub UI!
Node JS support is also available natively in CodeQL.
Electron
Electronegativity is a tool to identify misconfigurations and security anti-patterns in Electron-based applications. Check out the GitHub Action written by @jarlob.
Ruby on Rails
Brakeman is a static analysis tool which checks Ruby on Rails applications for security vulnerabilities. GitHub’s @swinton added support for SARIF, which can be configured in the available actions or from the GitHub UI starter workflow in your “Security” tab. Thanks @presidentbeef for the pull request review!
Ruby support is forthcoming in CodeQL, too.
Powershell
PSScriptAnalyzer is a static code checker for PowerShell modules and scripts. A GitHub Action was written by @A-Katopodis and it’s available in the GitHub UI.
Kubernetes YAML
Kubesec, backed by Control Plane, provides security risk analysis for Kubernetes resources and is now available in the GitHub UI or via their GitHub Action.
Terraform
tfsec uses static analysis of your terraform templates to spot potential security issues. Try the GitHub Action or find it in the Security UI. Thanks for the pull request, @OwenRumney!
C/C++
MSVC code analysis is the C/C++ correctness checker behind the Microsoft compiler.
Flawfinder is a C/C++ source code security checker and is available under the GitHub “Security” tab.
These languages are covered by CodeQL natively, but as the old adage goes: measure twice, cut once!
Multiple languages: Java, Go, Ruby, Python and more
Semgrep, sponsored by r2c, supports a variety of languages and added GitHub SARIF upload via workflow file, and is available in the GitHub UI.
Security Code Scan is a vulnerability patterns detector for C# and VB.NET and added a GitHub Action with help from @jarlob.
C# support is also available in CodeQL.
DevSkim supports C, C++, C#, Cobol, Go, Java, Javascript/Typescript, Python, and more.
Contribute to the code scanning ecosystem
If you contribute to a static analysis tool, linter, or container scanning tool, you can easily integrate your project with code scanning by following our step by step guide to list your project directly in the GitHub UI and surface your scan results under the GitHub “Security” tab.
Fuzzers and dynamic application security testing (DAST) tools can also follow a pattern of uploading their results, similar to ForAllSecure’s Mayhem for API action or the StackHawk HawkScan action, which adds a link to DAST output in the SARIF help text metadata field.
Give code scanning a try
If you haven’t tried code scanning, now’s a great time to explore this capability and its many integrations. From the “Security” tab in the GitHub UI, you can configure code scanning on any public repository using CodeQL, or you can try one of our pre-configured Octodemos for Android Kotlin, iOS Swift, JavaScript, Terraform, or PHP. Below is a quick example using MobSF for iOS Swift.
- To try code scanning with MobSF, navigate to: https://github.com/octodemo/advance-security-mobile-ios
- Fork the repository to your GitHub Account. (Note that this demo uses OWASP iGoat Swift – A Damn Vulnerable Swift Application for iOS, a deliberately vulnerable application for code scanning demonstration purposes only!)
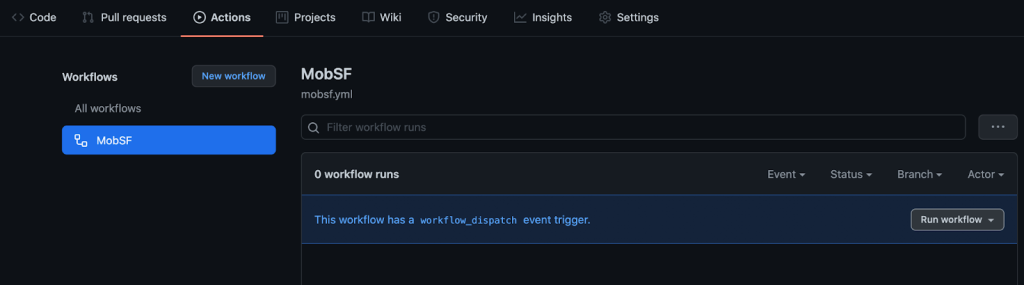
- Click the Actions tab and enable actions if required. 1000 free minutes are included in your GitHub account.
- Click on the MobSF workflow, then click Run workflow and run the workflow manually.
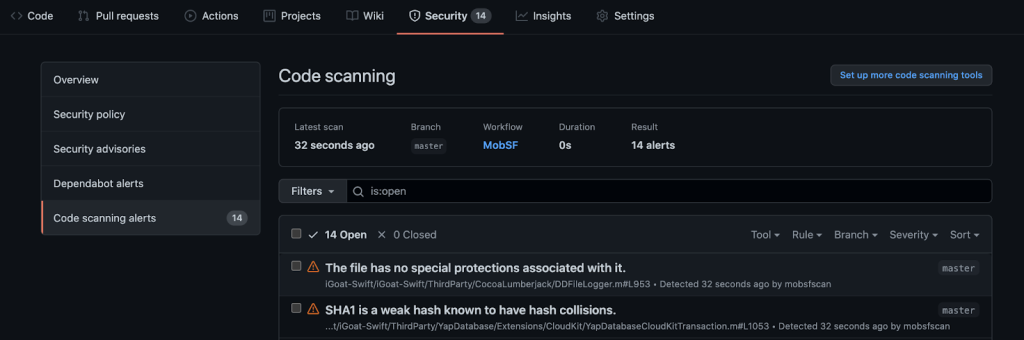
- In about a minute, you’ll see results populate in the “Security” tab under “Code scanning alerts.”
With GitHub Advanced Security, configuring a static analysis tool and delivering the results in context on every pull request is that simple! If you’d like a hands on demo for your organization don’t hesitate to contact us.
The post 15+ new code scanning integrations with open source security tools appeared first on The GitHub Blog.



33")
