Page 101 – The GitHub Blog
Updates, ideas, and inspiration from GitHub to help developers build and design software.
30 free and open source Linux games – part 3
27 Aug 2021, 4:00 pm
With Linux celebrating it’s 30 year anniversary, I thought I’d use that as an excuse to highlight 30 of my favorite free and open source Linux games, their communities, and their stories.
If you’ve haven’t been following along, here’s part 1 and part 2 in the series. Here are the final 10 in no particular order.
OpenRA

![]()
![]()
![]()
![]()
If you ever played Dune 2000, Command and Conquer, or Red Alert then OpenRA is for you. It’s basically those games remade for modern computers with updated gameplay, new campaigns, user-created and curated maps, and online play.
ProTip: Play a practice game or two ten before you play online. This will save you some embarrassment and/or friendships, as longtime players tend to have high expectations of their teammates.
StepMania
![]()
![]()
![]()
StepMania is a free dance and rhythm game featuring support for dance pads and an editor for creating your own steps. It was originally created as a clone of Konami’s DDR, but has since evolved into something much more that can be used for both home and arcade use.
This is the perfect weekend hack project to turn your garage into a dance studio and work on your cardio. Yes, this is experience talking. 
Did you know: There’s a fork of Stepmania called Project OutFox that aims to “modernize its codebase to improve performance and graphical fidelity, refurbishing aspects of the engine that have been neglected, and to improve and expand its support for other game types and styles.” The latest OutFox Alpha 4.9.9 release is packed with new features and bug fixes
Pioneer
![]()
![]()
![]()
Pioneer is a space trading and combat simulator video game inspired by Frontier: Elite 2. Players can explore millions of star systems, trade, or turn to a life of crime, piracy, smuggling, and more.
Pioneer had a steady stream of new releases last month, introducing improved music selection and new tracks, as well as a remodel of a classic ship, amongst other things. View the model on SketchFab—she’s a beaut!
Fun fact: I blogged about Pioneer nine years ago exactly on the GitHub Game Bytes post. My resemblance to Pedro Ramos remains. (I just need to add a few more gray hairs experience points).
{kind=link}
Shattered Pixel Dungeon
![]()
![]()
![]()
![]()
Shattered Pixel Dungeon, a pixel-perfect roguelike RPG created by @00-Evan, just hit the big 1.0. Congratulations on the release, Evan! 
The game actually started life as mod for Pixel Dungeon and was only supposed to be a project lasting a few months back in 2014. Thanks to the overwhelmingly positive reaction from the community, it has since evolved into its own game but still shares some code and other assets with its predecessor.
This game offers lots of variety, lots of playability (and difficulty!), and will keep you coming back for just more game.
Fun fact: I installed this on my iPhone last week and have sunk so many hours into it, I haven’t had time to complete this third blog post in this series. Don’t tell my editor! 
C-Dogs SDL
![]()
C-Dogs SDL is a 4-player run and gun game where you …well, run and gun with or against the other players. The release notes are always chock full of pixely goodness. The latest update shipped with AI updates, and weapon sprites to see what your enemies are holding.
Did you know: C-Dogs was a freeware DOS game made in the nineties by Ronny Wester. In 2002, the game was open sourced and then ported to SDL by Jeremy Chin and Lucas Martin-King. Today, the project is maintained by @cxong, who with the help of the community, has introduced amazing new features like 4-player multiplayer, co-op AI, moddability plus new campaigns/maps.
AssaultCube
![]()
AssaultCube is a multiplayer first-person shooter game that packs a punch in a lightweight 50MB package. Play some Deathmatch, Survivor, Capture the Flag, Hunt the Flag, Keep the Flag, Pistol Frenzy, Last Swiss Standing, and One-Shot One-Kill with your office mates or friends.
Did you know: The game has a built-in map editor and enables co-operative editing in real time with others. No more back and forths over your favorite version control system!
Minetest
![]()
![]()
![]()
Minetest‘s may be a bit blocky, but the gameplay that this open source voxel game engine provides is fantastic. Choose from one of many games, or create your own games and mods. Play by yourself, locally with friends, or online in worlds that measure 62,000 x 62,000, 62,0000 blocks. That’s right, you dig a mine 31,000 blocks down.
If you’d like to get involved, this guide will tell you how you can join the community and report issues, review code, work on code, etc.
Zero-K

![]()
![]()
![]()
![]()
Zero-K is an RTS game fought over land, air, and sea with hundreds of maps and units at your disposal. Play in single-player campaign mode, multiplayer with friends, or powerful AI.
It’s built on top of the open source Spring game engine, and the team welcomes new contributors. Check out the guide to getting started.
Wyrmsun
![]()
![]()
![]()
![]()
Wyrmsun is a real-time strategy game based on history, mythology, and the lore of other open source games, like Battle for Wesnoth (featured in the first blog post in this series). There’s even an in-game encyclopedia, describing the units, buildings, as well as their historical and mythological sources of inspiration.
If you liked Warcraft II, you’ll love this.
Mindustry

![]()
![]()
![]()
What happens when you cross a tower defense game with a factory game? You get Mindustry—a beautiful hybrid of both created by game developer @Anuken. Create elaborate supply chains of conveyor belts, feed ammo into your turrets, and produce materials to use for building to help stop wave upon wave upon wave upon wave of enemies.
Words and pixels don’t do this justice. You’ll definitely want to check this out for yourself.
SuperTux

![]()
![]()
![]()
We started this series with a penguin. We’ll end it with one. Tux makes another appearance in SuperTux—a classic platformer similar in style to that game with the Italian plumber brothers—I forget the name. In addition to the story mode, you’ll find a large number of community-created levels available as add-ons.
Would you like to contribute? See the open issues and of course CONTRIBUTING.md.
Well, that’s a wrap. That’s just my take on the best free and open source Linux games. There are definitely more out there and it was hard deciding which ones to cut.
Editors note: That makes 31 games by my count. This wouldn’t be the first time Lee’s been involved in an off-by-one error 
The post 30 free and open source Linux games – part 3 appeared first on The GitHub Blog.
30 free and open source Linux games – part 2
26 Aug 2021, 4:00 pm
Linux is celebrating its 30-year anniversary, so I’m taking the opportunity to highlight 30 of my favorite free and open source Linux games, their communities, and their stories. I shared the first 10 yesterday. Now it’s time for, that’s right, 11 – 20!
FreeOrion
![]()
![]()
![]()
FreeOrion is a 4X (that’s Xplore, eXpand, eXploit, and eXterminate) turn-based, space empire and galactic conquest strategy game. It’s inspired by the Master of Orion games but is neither a clone nor a remake of the original game. Explore the randomly-generated galaxy, colonize planets, research new technologies, and prepare to battle with diverse and formidable species.
With the game’s support for scripting with FOCS (FreeOrion Content Script) files, the community has an easy way to customize mechanics, presentation, and pretty much everything in the universe. Here’s an example for a small Krill space monster:
MonsterFleet
name = "SM_KRILL_1"
ships = [
"SM_KRILL_1"
]
spawnrate = 0.5
spawnlimit = 9999
location = And [
Not Contains Monster
Not WithinStarlaneJumps jumps = 2 condition = Contains And [
Planet
OwnedBy affiliation = AnyEmpire
]
]Maybe I’ll craft a huge Octocat monster this weekend.

Help wanted: Whether it’s programming, design, content scripting, bug reporting, playtesting, translation work, or something else, FreeOrion welcomes new volunteers with a wide variety of skills. See the project wiki for ideas and areas where you could help.
NetHack

![]()
![]()
NetHack is a roguelike game—a fork of the 1982 game Hack.
Choose from one of the character classes, and fight your way through the usual procedurally-generated dungeon foes in search of the elusive Amulet of Vendor. It’s not a trivial game to get into, but it is very rewarding.
As the code is open source, fixing bugs, adding features, or just figuring out how stuff works is achievable. For example, wondering how a boomerang will travel when you toss it at an opponent? This wonderful code comment illustrates that perfectly:
register int i, ct;
int boom; /* showsym[] index */
struct monst *mtmp;
boolean counterclockwise = TRUE; /* right-handed throw */
/* counterclockwise traversal patterns:
* ..........................54.................................
* ..................43.....6..3....765.........................
* ..........32.....5..2...7...2...8...4....87..................
* .........4..1....6..1...8..1....9...3...9..6.....98..........
* ..21@....5...@...7..@....9@......@12....@...5...@..7.....@9..
* .3...9....6..9....89.....................1..4...1..6....1..8.
* .4...8.....78.............................23....2..5...2...7.
* ..567............................................34....3..6..
* ........................................................45...
* (invert rows for corresponding clockwise patterns)
*/
bhitpos.x = u.ux;
bhitpos.y = u.uy;
boom = counterclockwise ? S_boomleft : S_boomright;Fun fact: Back when IRL events were a thing, we hosted the annual Roguelike Celebration at GitHub HQ and managed to record Mikko Joula (aka Adeon), who holds the record for fastest real-time ascension, doing a live speedrun of NetHack. 
Stunt Rally
![]()
There might not have been an official release in five years, but the creator of Stunt Rally, @cryham, put a solid five years of work into it, and it still shines today. Choose from over 20 cars, 172 race tracks across multiple terrains (and planets), and race a friend on your network …or splitscreen. It also ships with a track editor.
Red Eclipse 2
![]()
![]()
![]()
Red Eclipse 2 is an FPS focusing on fast-paced gameplay like parkour, dashing, and impulse boosts that’s been in development for more than a decade. It also has a built-in editor allowing you to create maps cooperatively online in realtime.
This game is built on the Tesseract game engine, which is a fork of the Cube 2: Sauerbraten game engine written by one of the developers, @lsalzman.
Freeciv
![]()
![]()
![]()
Freeciv is a free and open source, turn-based, empire-building strategy game supporting up to 126 players (or 500 on the web version). With over 500 nations and 50 playable units, you’re bound to find something that interests you as you lead your empire out of the stone age and into the space age.
Did you know: Freeciv is maintained by an international team of developers and enthusiasts and has been localized into 36 different languages—including my mother tongue, Scots Gaelic! Sgoinneil!
Endless Sky
![]()
![]()
Explore the galaxy, and follow your dreams of becoming an intergalactic space trader, dreaded space pirate, gun for hire, etc. In Endless Sky, you’ll need to make quite a bit of coin to pay off your loan (for your starter spacecraft), and later purchase new spacecrafts, upgrade weapons, and tweak your engines …you get the idea.
Help wanted: See yourself as a storyteller or content creator? One of the game’s goals is to collect stories and content from as diverse a group of people as possible, so there are always new places to explore, each with its own unique characteristics. There are lots of non-programming tasks available too: create new missions, ships, weapons, aliens, add or enhance audio and visuals, and more. See the Help Wanted section for more information.
Pixel Wheels
![]()
![]()
Ready. Set. Go, and check out Pixel Wheels, a delightful little work-in-progress, top-down racer game from @gateau that you can play on your Android or Linux devices. There are tons of tracks, a variety of vehicles, and some power-ups that pack a punch. 
Follow along with updates here.
Did you know: GitHub Pages is a free and easy way to quickly and easily publish your release notes. Here is the Markdown source for the 0.20.0 release announcement for example.
Unknown Horizons
![]()
![]()
Expand your small settlement and build a healthy colony in Unknown Horizons, a real-time economy simulation game based on the Anno game series. Expand your settlement beyond the horizon, collect taxes, and keep your inhabitants happy and healthy.
Did you know: The current version of Unknown Horizons is built on top of FIFE. No, not the place in Scotland; a multi-platform isometric game engine written in C++ that stands for “Flexible Isometric Free Engine.” The team is currently porting the game to Godot—another free and open source game engine.
Vega Strike

![]()
![]()
Vega Strike is a 3D space flight simulator putting you in the cockpit to explore, fight, and trade throughout the galaxy. It is similar to Freelancer, but free!
If you like the game and would like to help with coding, art work, documentation, or testing, then view the CONTRIBUTING.rst for details.
Dungeon Crawl Stone Soup
![]()
![]()
![]()
Dungeon Crawl Stone Soup (let’s call it DCSS for short) is another roguelike game. Download it, build it from source, or telnet/SSH to a server, and play it that way. You can actually watch players around the world exploring the dungeons live via the website. Magic. Speaking of magic, the latest release has lots of new spells and spell books, plus a few new maps too.
Fun fact: An interesting bug was introduced a few years ago and went unnoticed for almost two weeks. It turns out that this commit accidentally caused melee damage dealt by players to be doubled. It was only discovered when it was noticed that there were significantly more people winning the game.
Tune in tomorrow for the final 10 games. You won’t believe number 29!
Editor’s note: That confirms it. I’m not sure what #29 is going to be, but this definitely smells clickbaity.
The post 30 free and open source Linux games – part 2 appeared first on The GitHub Blog.
30 free and open source Linux games – part 1
25 Aug 2021, 4:00 pm
Linux is celebrating its 30-year anniversary today, so I’m taking the opportunity to highlight 30 of my favorite free and open source Linux games, their communities, and their stories!
If you like RTS, FPS, space trading, roguelike, racing, strategy, or platform games then you’re bound to find something you like below. Oh, and some of the games work on Windows and macOS too, so there should be something for (almost) everyone.
In no particular order…
SuperTuxKart
![]()
![]()
![]()
It’s impossible to start a list of Linux games without paying homage to Tux, the logo brand character for the Linux kernel.
Tux is the star of SuperTuxKart, a fun arcade racing game that includes a variety of characters, tracks, and modes. You can race against the kernel, on your LAN with friends, or with complete strangers from all over the world online. If you like Mario Kart or Sonic All Stars Racing, you’ll love this!
Fun fact: You might recognize some of the other characters in the game like Wilber, Pidgin, and Konki from the open source projects they represent. I wonder if we’ll ever see Mona?
Oolite

![]()
![]()
![]()
Billed as an open-word space opera, Oolite is inspired by David Braben’s classic game Elite—a game I spent many an hour playing on my school’s BBC Micro.
Forge your own path in the galaxy by becoming a feared pirate, a dodgy trader, a gun for hire, or a washed-up software engineer searching the galaxy for coin.
Did you know: There are over 500 expansion packs created by the community that introduce new ships, missions, weapons, and more. Maybe I’ll nerd-snipe myself into building some sort of GitHub Universe this weekend.

Cataclysm: Dark Days Ahead

![]()
![]()
Cataclysm: DDA is a roguelike game set in a procedurally generated, post-apocalyptic world. Think zombies, nuclear waste grounds, that sorta thing. Like most roguelikes games, it’s primarily text-based, but there are tilesets available.
Did you know: The game has over 1300 contributors who are introducing new crouching mechanics, fixing in-game computer terminals, adding lakes and flyable helicopters, and more.
If you catch the Cataclysm: DDA bug and would like to contribute, check out the Contributing Guide. You can add some documentation, translate content, or get your code on and add some new NPCs, monsters, missions and more! For the most part, that’s as simple as adding/editing some JSON.
The Battle for Wesnoth
![]()
![]()
![]()
![]()
Battle for Wesnoth is a turn-based strategy game with a variety of campaigns involving elves, dwarves, orcs, trolls, humans, and more. Speaking of humans, hundreds of them have contributed maps, campaigns, features, and bug-fixes to the project.
If you’re looking for an excuse to get some extra green squares on your contribution graph, you can create new maps, campaigns, and units, introduce new art or music, help with translations, or even update the AI. Check out this getting started guide.
Warning: As the thousands of very positive reviews on Steam might suggest, this game is addicting. So much so, if you’re on your laptop and lose track of time you might run out of battery. Thankfully, someone submitted a fix for that!
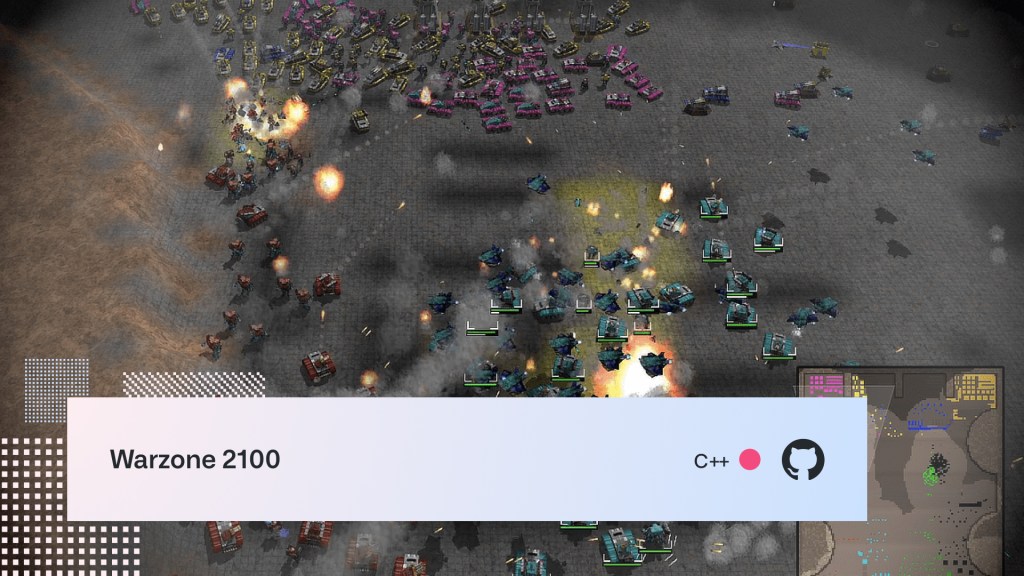
Warzone 2100
![]()
![]()
![]()
![]()
A malfunction in Earth’s new strategic defense system causes a series of nuclear strikes that take out almost every inhabitant on Earth. Your job is to help rebuild civilization, but as you can imagine, there are a few barriers to overcome first.
Originally developed by Pumpkin Studios and released in 1999, Warzone 2100 was open sourced in 2004 under a GNU GPL v2.0 or later license. Now the project is entirely community-driven and still sees plenty of updates from hundreds of contributors. If you like real time strategy games, you’ll like this. 
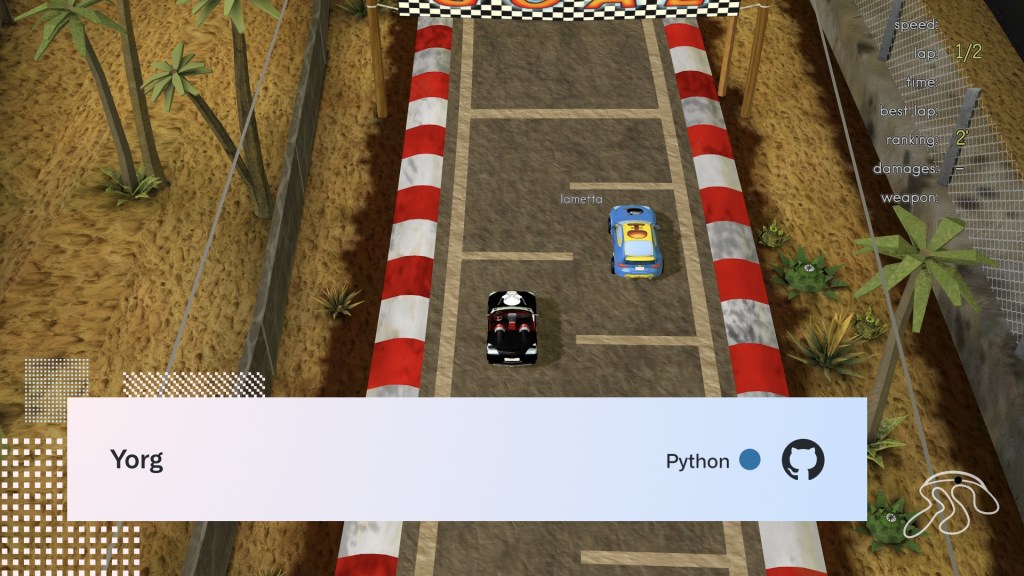
Yorg
![]()
Yorg (no, not that one) is an arcade-style racing game with lots of cars, tracks, powerups, and weapons. Race against AI or take on your friends in local/online multiplayer! I’m probably a little biased as I grew up loving games like Micro Machines and Ivan “Ironman” Stewart’s Super Off Road.
Yorg was created by Ya2, a small indie game development team established in Rome, and created using Panda 3D—an open-source, cross-platform game engine designed for Python and C++.
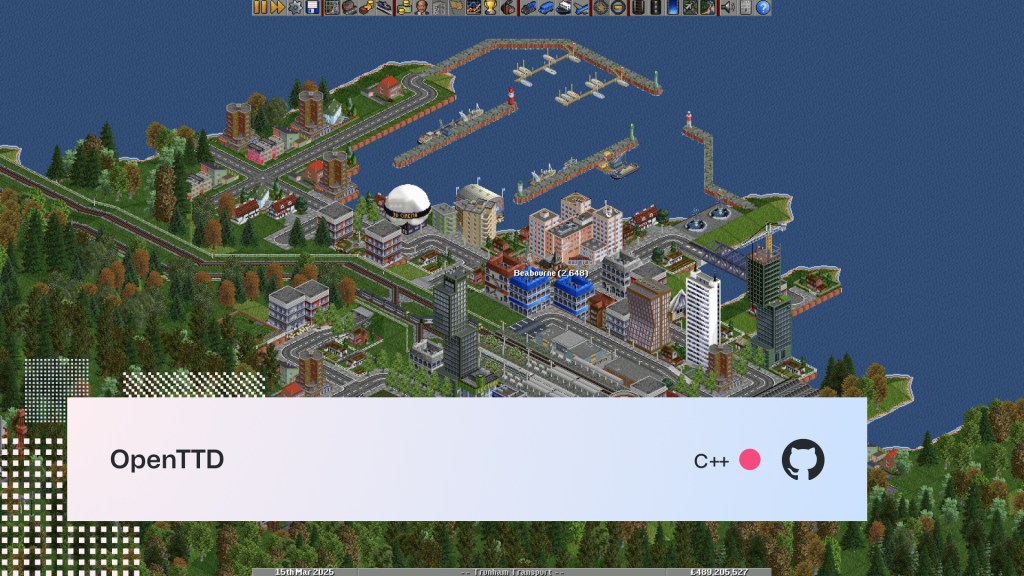
OpenTTD
![]()
![]()
![]()
![]()
Did you ever play Transport Tycoon Deluxe back in the day? OpenTTD, as the name suggests, is an open source game based on it. In addition to mimicking the original game, it offers significant new features, like multiplayer mode for up to 255 players, waaay bigger maps, and the ability to build on slopes and coasts!
If you have a little time and are familiar with C++, consider contributing to the project. Check out the CONTRIBUTING.md for details about the goals of the project and the kinds of things you could work on.
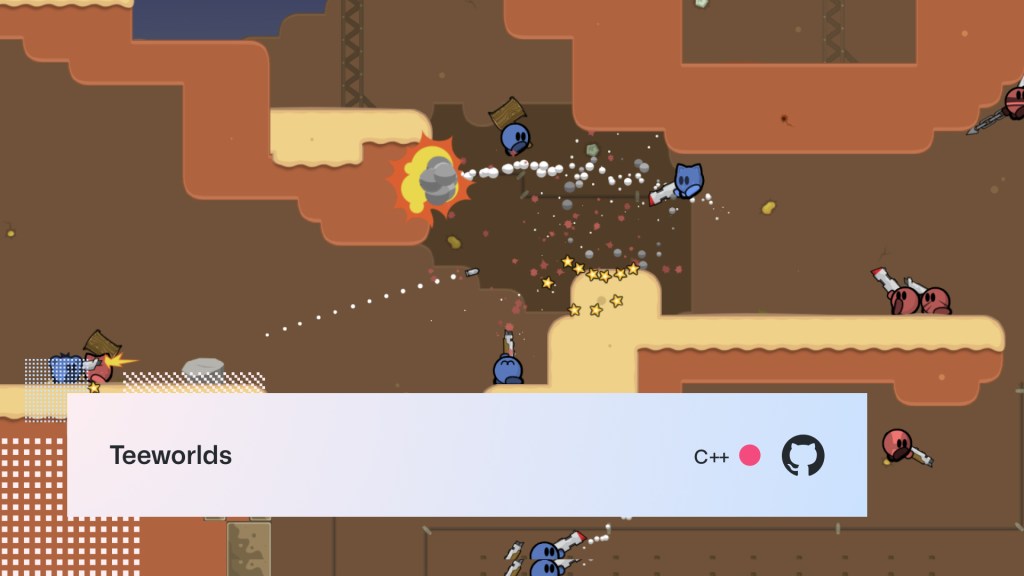
Teeworlds
![]()
![]()
Easy to learn, but hard to master, Teeworlds is a nice little MMO that’s a mashup of retro platform and shooting games. Customize your character, battle with up to 16 players, create your own maps, or check out some of the amazing community-created maps.
Originally created by Magnus Auvinen, it’s now open source and maintained by the community.
Unvanquished
![]()
![]()
![]()
![]()
Unvanquished is an FPS strategy game pitting superhuman soldiers against devious aliens. Take shots destroying the enemy bases – either as a human with long range firepower, or as an alien in close combat who prefers stealth.
Unvanquished has been in development for 10 years, with the first release in February 2012. Since then, the game has had monthly releases – the latest being the 0.52.1 beta release – chock full of enhancements, bug fixes, and a new flatpak making it easier to install across almost every Linux distro.
AstroMenace
![]()
If you grew up on games like Gallaga or 1942 R-Type, or if you just like blowing stuff up in space, then this game is for you. AstroMenace is a shoot-em-up developed and published by Russian indie game developer @viewizard.
Translators wanted: If you’d like to help make the game more friendly and welcoming for everyone, they are currently looking for help translating the game to other languages. I don’t see any requests for Klingon translation. Yet. Qapla’.
Wait, what? That’s only 10! That’s right, tune in tomorrow for the next 10!
Editor’s note: Not sure if Lee is only giving us the first 10 because he’s trying to master clickbait… or if he hasn’t actually written the rest of the post. Let’s find out tomorrow!
The post 30 free and open source Linux games – part 1 appeared first on The GitHub Blog.
2021 Transparency Report: January to June
25 Aug 2021, 4:00 pm
At GitHub, we put developers first, and we work hard to provide a safe, open, and inclusive platform for code collaboration. This means we are committed to minimizing the disruption of software projects, protecting developer privacy, and being transparent with developers about content moderation and disclosure of user information. This kind of transparency is vital because of the potential impacts to people’s privacy, access to information, and the ability to dispute decisions that affect their content. With that in mind, we’ve published transparency reports going back seven years (2020, 2019, 2018, 2017, 2016, 2015, and 2014) to inform the developer community about GitHub’s content moderation and disclosure of user information.
A United Nations report on content moderation recommends that online platforms promote freedom of expression and access to information by (1) being transparent about content removal policies and (2) restricting content as narrowly as possible. At GitHub, we do both. Check out our contribution to the UN expert’s report for more details.
We promote transparency by:
- Developing our policies in public by open sourcing them so that our users can provide input and track changes
- Explaining our reasons for making policy decisions
- Notifying users when we need to restrict content, along with our reasons, whenever possible
- Allowing users to appeal removal of their content
- Publicly posting all Digital Millennium Copyright Act (DMCA) and government takedown requests we process in a public repository in real time
We limit content removal, in line with lawful limitations, as much as possible by:
- Aligning our Acceptable Use Policies with restrictions on free expression, for example, on hate speech, under international human rights law
- Providing users an opportunity to remediate or remove specific content rather than blocking entire repositories, when we see that is possible
- Restricting access to content only in those jurisdictions where it is illegal (geoblocking), rather than removing it for all users worldwide
- Before removing content based on alleged circumvention of copyright controls (under Section 1201 of the US DMCA or similar laws in other countries), we carefully review both the legal and technical claims and give users the option to seek independent legal advice funded by GitHub.
What’s included in this report
This time we’re reporting on a six-month period rather than annually to increase our level of transparency. In previous reports, we’ve drawn some comparisons to past years’ numbers. Because this report covers a six-month period in 2021, we’ve also added more granularity to our 2020 stats to make some comparisons to the first half of 2020 (January to June) and the second half of 2020 (July to December).
In this reporting period, we continue to focus on areas of strong interest from developers and the general public, such as requests we receive from governments—whether for information about our users or to take down content posted by our users—and copyright-related takedowns. Copyright-related takedowns (which we often refer to as DMCA takedowns) are particularly relevant to GitHub because so much of our users’ content is software code and can be eligible for copyright protection. That said, only a tiny fraction of content on GitHub is the subject of a DMCA notice (under four in 100,000 repositories). Appeals of content takedowns is another area of interest to both developers and the general public.
Putting that all together, in this Transparency Report, we will review stats from January to June 2021 for the following:
- Requests to disclose user information
- Subpoenas
- Court orders
- Search warrants
- National security letters and orders
- Cross-border data requests
- Government requests to remove or block user content
- Under a local law
- Under our Terms of Service
- Takedown notices under the DMCA
- Notices to take down content that allegedly infringes copyright
- Notices to take down content that allegedly circumvents a technical protection measure
- Appeals
- Appeals and other account or content reinstatement related to violations of our Acceptable Use Policies, which are part of our Terms of Service (not counting DMCA since we report on those appeals in the form of counter notices)
- Appeals of account restrictions due to trade sanctions laws
Continue reading for more details. If you’re unfamiliar with any of the GitHub terminology we use in this report, please refer to the GitHub Glossary.
Requests to disclose user information
GitHub’s Guidelines for Legal Requests of User Data explain how we handle legally authorized requests, including law enforcement requests, subpoenas, court orders, and search warrants, as well as national security letters and orders. We follow the law, and also require adherence to the highest legal standards for user requests for data.
Some kinds of legally authorized requests for user data, typically limited in scope, do not require review by a judge or a magistrate. For example, both subpoenas and national security letters are written orders to compel someone to produce documents or testify on a particular subject, and neither requires judicial review. National security letters are further limited in that they can only be used for matters of national security.
By contrast, search warrants and court orders both require judicial review. A national security order is a type of court order that can be put in place, for example, to produce information or authorize surveillance. National security orders are issued by the Foreign Intelligence Surveillance Court, which is a specialized US court for national security matters.
As we note in our guidelines:
- We only release information to third parties when the appropriate legal requirements have been satisfied, where we believe it’s necessary to comply with our legal requirements, or in exigent circumstances where we believe the disclosure is necessary to prevent an emergency involving danger of death or serious physical injury to a person.
- We require a subpoena to disclose certain kinds of user information, like a name, an email address, or an IP address associated with an account, unless in very rare cases where we determine that disclosure (as limited as possible) is necessary to prevent an emergency involving danger of death or serious physical injury to a person.
- We require a court order or search warrant for all other kinds of user information, like user access logs or the contents of a private repository.
- We notify all affected users about any requests for their account information, except where we are prohibited from doing so by law or court order.
From January to June 2021, GitHub received 172 requests to disclose user information, as compared to 172 in January to June 2020, and 131 in July to December 2020. Of those 172 requests, we processed 102 subpoenas (96 criminal and six civil), 47 court orders, 13 search warrants, and three requests based on exigent circumstances (related to kidnapping, child exploitation, and a bomb threat). These requests also include seven cross-border data requests, which we’ll share more about later in this report. The large majority (96.4%) of these requests came from law enforcement. The remaining 3.49% were civil requests, all of which came from civil litigants wanting information about another party.
These numbers represent every request we received for user information, regardless of whether we disclosed information or not, with one exception: we are prohibited from even stating whether or how many national security letters or orders we received. More information on that is below. We’ll cover additional information about disclosure and notification in the next sections.
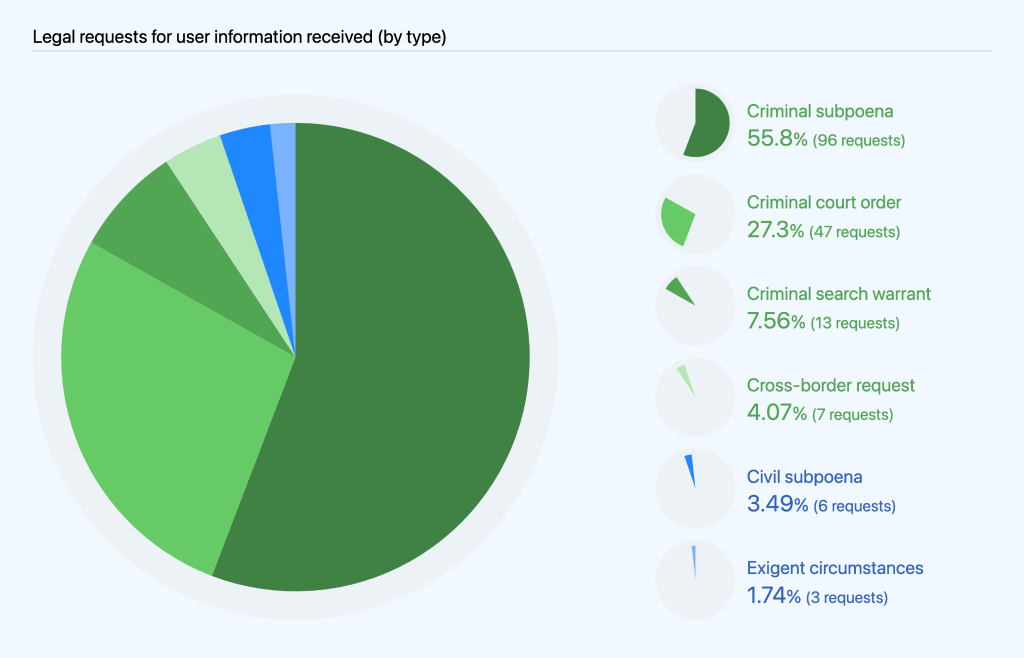
Disclosure and notification
We carefully vet all requests to disclose user data to ensure they adhere to our policies and satisfy all appropriate legal requirements, and push back where they do not. As a result, we didn’t disclose user information in response to every request we received. In some cases, the request was not specific enough, and the requesting party withdrew the request after we asked for clarification. In other cases, we received very broad requests, and we were able to limit the scope of the information we provided.
When we do disclose information, we never share private content data, except in response to a search warrant. Content data includes, for example, content hosted in private repositories. With all other requests, we only share non-content data, which includes basic account information, such as username and email address, metadata such as information about account usage or permissions, and log data regarding account activity or access history.
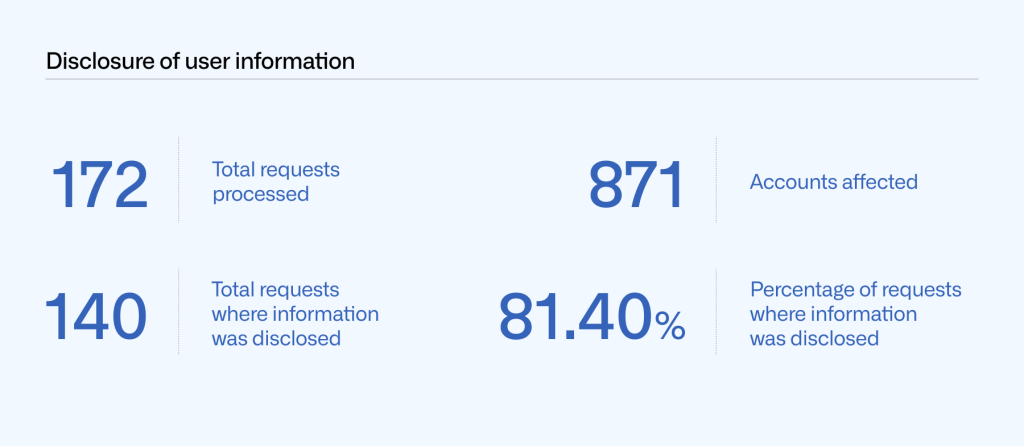
Of the 172 requests we processed from January to June 2021, we disclosed information in response to 140 of those. Specifically, we disclosed information in response to 94 subpoenas (89 criminal and 5 civil), 30 court orders, 13 search warrants, and three under exigent circumstances.
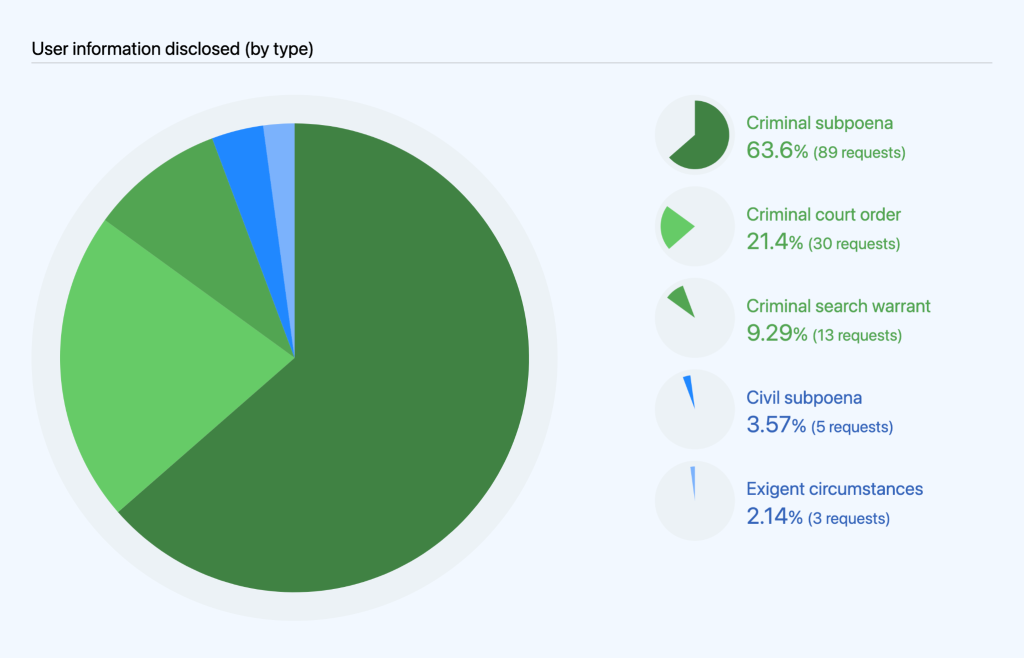
Those 140 disclosures affected 871 accounts.
We notify users when we disclose their information in response to a legal request, unless a law or court order prevents us from doing so. In many cases, legal requests are accompanied by a court order that prevents us from notifying users, commonly referred to as a gag order. In (rare) exigent circumstances, we may disclose information and delay notification if we determine delay is necessary to prevent death or serious harm or due to an ongoing investigation.
Of the 140 times we disclosed information in the first half of 2021, we were only able to notify users five times because the other 135 requests were either accompanied by gag orders or received under exigent circumstances. This is an increase compared to similar time periods in 2020, where we were only able to notify users six times from January to June and seven times in July to December because gag orders accompanied the other 97 and 84 requests, respectively.
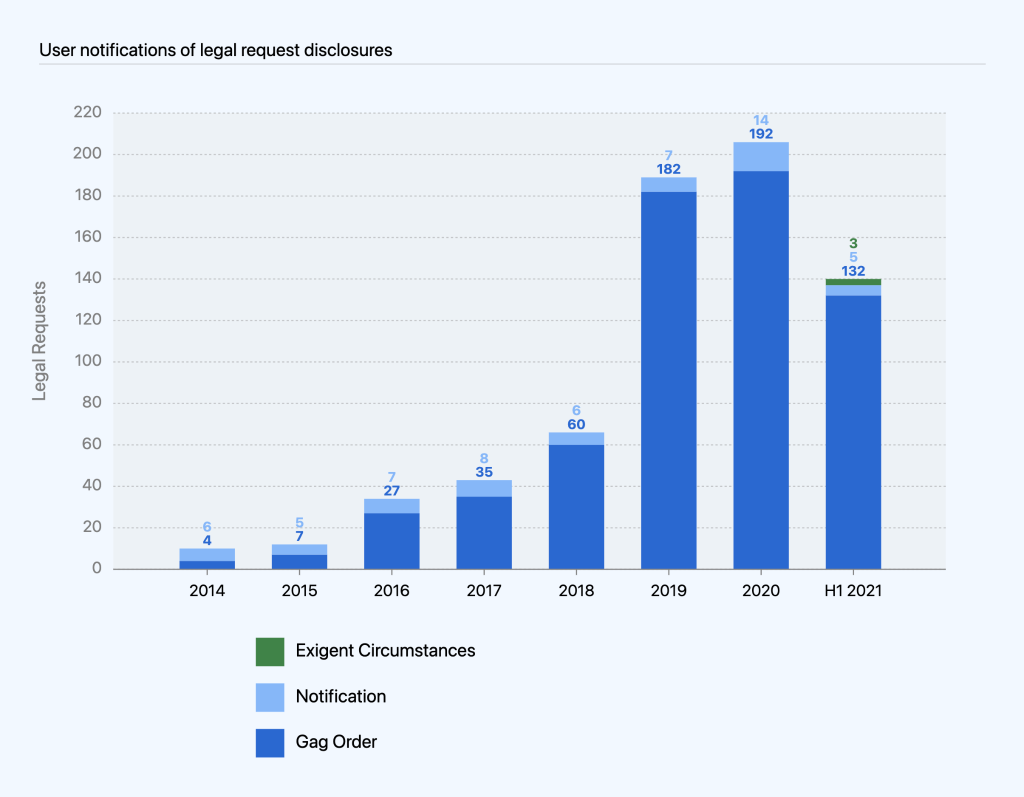
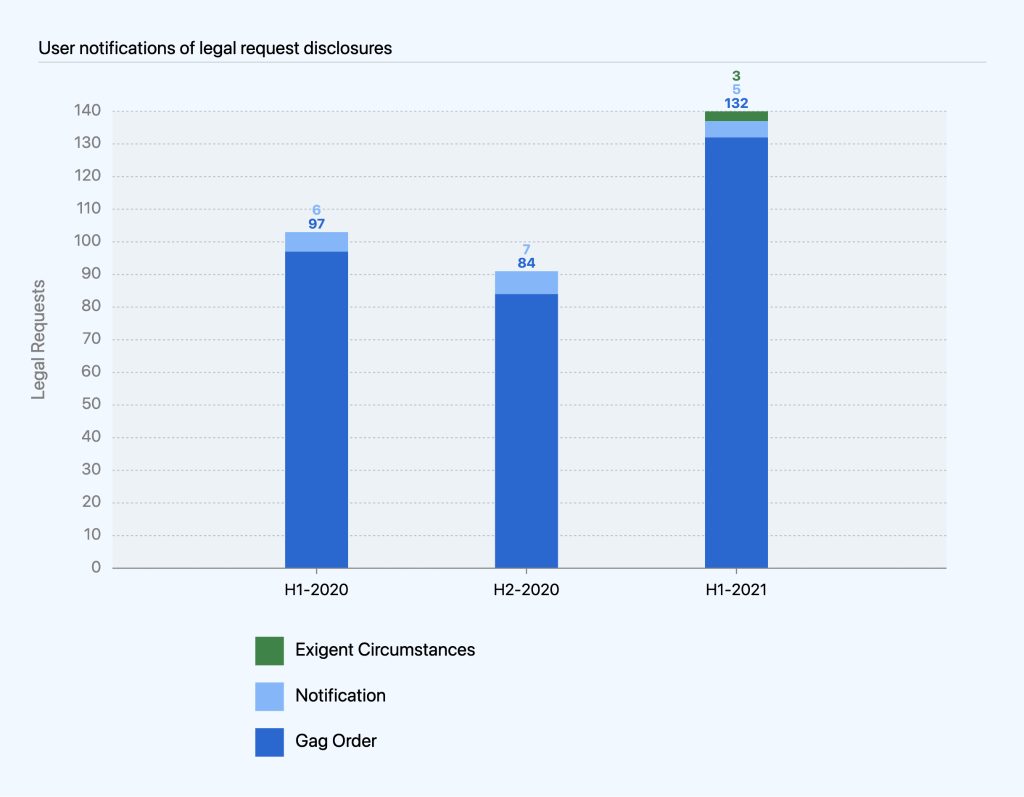
While the number of requests with gag orders continues to be a rising trend as a percentage of overall requests, it correlates with the number of criminal requests we processed. Legal requests in criminal matters often come with a gag order, since law enforcement authorities often assert that notification would interfere with the investigation. The same is true for requests received under exigent circumstances. On the other hand, civil matters are typically public record, and the target of the legal process is often a party to the litigation, obviating the need for any secrecy. None of the civil requests we processed this reporting period came with a gag order, which means we notified each of the affected users.
From January to June 2021, we continued to see a correlation between civil requests we processed (3.6%) and our ability to notify users during the reporting period (3.6.%). Our data from the past years also reflects this trend of notification percentages correlating with the percentage of civil requests:
- 6.8% notified and 6.9% civil requests in 2020
- 3.7% notified and 3.1% civil requests in 2019
- 9.1% notified and 11.6% civil requests in 2018
- 18.6% notified and 23.5% civil requests in 2017
- 20.6% notified and 8.8% civil requests in 2016
- 41.7% notified and 41.7% civil requests in 2015
- 40% notified and 43% civil requests in 2014
National security letters and orders
We’re very limited in what we can legally disclose about national security letters and Foreign Intelligence Surveillance Act (FISA) orders. The US Department of Justice (DOJ) has issued guidelines that only allow us to report information about these types of requests in ranges of 250, starting with zero. As shown below, we received 0–249 notices from January to June 2021, affecting 0–249 accounts.

Cross-border data requests
Governments outside the US can make cross-border data requests for user information through the DOJ via a mutual legal assistance treaty (MLAT) or similar form of international legal process. Our Guidelines for Legal Requests of User Data explain how we handle user information requests from foreign law enforcement. Essentially, when a foreign government seeks user information from GitHub, we direct the government to the DOJ so that the DOJ can determine whether the request complies with US legal protections.
If it does, the DOJ would send us a subpoena, court order, or search warrant, which we would then process like any other requests we receive from the US government. When we receive these requests from the DOJ, they don’t necessarily come with enough context for us to know whether they’re originating from another country. However, when they do indicate that, we capture that information in our statistics for subpoenas, court orders, and search warrants.
From January to June 2021, we received seven requests directly from foreign governments. Those requests came from four countries: Brazil, Germany, India, and Japan. Consistent with our guidelines above, in each of those cases we referred those governments to the DOJ to use the MLAT process.
In the next sections, we describe two main categories of requests we receive to remove or block user content: government takedown requests and DMCA takedown notices.
Government takedowns
From time to time, GitHub receives requests from governments to remove content that they judge to be unlawful in their local jurisdiction. When we remove content at the request of a government, we limit it to the jurisdiction(s) where the content is illegal—not everywhere—whenever possible. In addition, we always post the official request that led to the block in a public government takedowns repository, creating a public record where people can see that a government asked GitHub to take down content.
When we receive a request, we confirm whether:
- The request came from an official government agency
- An official sent an actual notice identifying the content
- An official specified the source of illegality in that country
If we believe the answer is “yes” to all three, we block the content in the narrowest way we see possible, for example by geoblocking content only in a local jurisdiction.
From January to June 2021, GitHub received and processed four government takedown requests based on local laws—two from Russia and two from China. These takedowns resulted in 39 projects (two gists and 37 repositories) being blocked in Russia and China, respectively. In comparison, in 2020, we processed 21 takedowns in the first half of the year and 23 in the second half of the year, all from Russia. We processed a significantly lower number of government takedown requests in the first half of 2021 as compared to similar time frames in 2020.
In addition to requests based on violations of local law, GitHub processed four requests from governments to take down content as a Terms of Service violation, affecting four accounts and 13 projects from January to June 2021. These requests concerned phishing (US), malware (US), and copyright, processed under our DMCA takedown policy (China).
DMCA takedowns
Consistent with our approach to content moderation across the board, GitHub handles DMCA claims to maximize protections for developers, and we designed our DMCA Takedown Policy with developers in mind. Most content removal requests we receive are submitted under the DMCA, which allows copyright holders to ask GitHub to take down content they believe infringes on their copyright. If the user who posted the allegedly infringing content believes the takedown was a mistake or misidentification, they can then send a counter notice asking GitHub to reinstate the content.
Additionally, before processing a valid takedown notice that alleges that only part of a repository is infringing, or if we see that’s the case, we give users a chance to address the claims identified in the notice first. We also now do this with all valid notices alleging circumvention of a technical protection measure. That way, if the user removes or remediates the specific content identified in the notice, we avoid having to disable any content at all. This is an important element of our DMCA policy, given how much users rely on each other’s code for their projects.
Each time we receive a valid DMCA takedown notice, we redact personal information, as well as any reported URLs where we were unable to determine there was a violation. We then post the notice to a public DMCA repository.
Our DMCA Takedown Policy explains more about the DMCA process, as well as the differences between takedown notices and counter notices. It also sets out the requirements for making a valid request, which include that the person submitting the notice takes into account fair use.
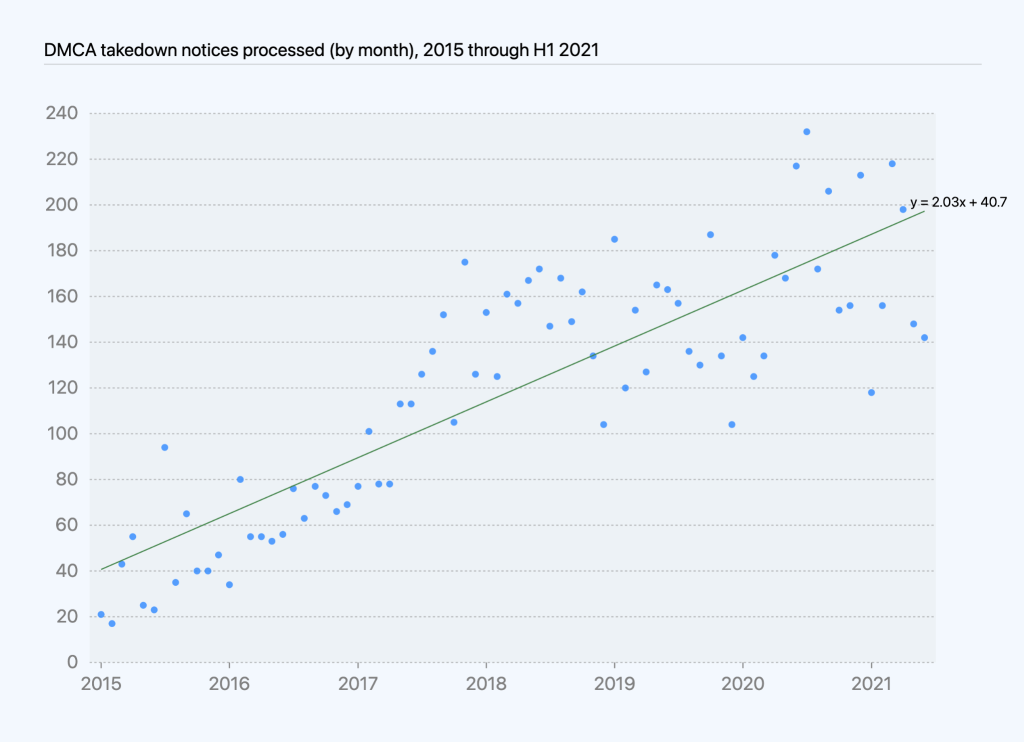
Takedown notices received and processed
From January to June 2021, GitHub received and processed 980 valid DMCA takedown notices. This is the number of separate notices where we took down content or asked our users to remove content. In addition, we received and processed 20 valid counter notices, four retractions, one reversal, and one counter notice reversal, for a total of 1,006 notices in January to June 2021. We did not receive any notice of legal action filed related to a DMCA takedown request this reporting period.

While content can be taken down, it can also be restored. In some cases, we reinstate content that was taken down if we receive one of the following:
- Counter notice: the person whose content was removed sends us sufficient information to allege that the takedown was the result of a mistake or misidentification.
- Retraction: the person who filed the takedown changes their mind and requests to withdraw it.
- Reversal: after receiving a seemingly complete takedown request, GitHub later receives information that invalidates it, and we reverse our original decision to honor the takedown notice.
These definitions of “retraction” and “reversal” each refer to a takedown request. However, the same can happen with respect to a counter notice. From January to June 2021, we processed one counter notice reversal.
In the same time period, the total number of takedown notices ranged from 118 to 218 per month. The monthly totals for counter notices, retractions, and reversals combined ranged from one to eight.

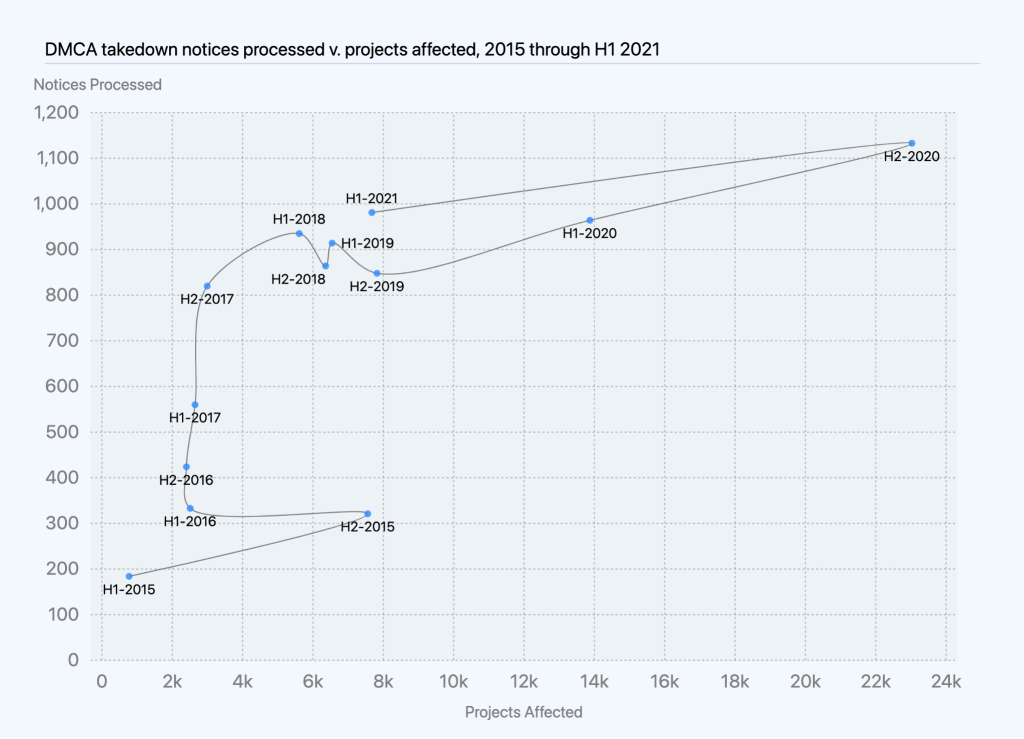
Projects affected by DMCA takedown requests
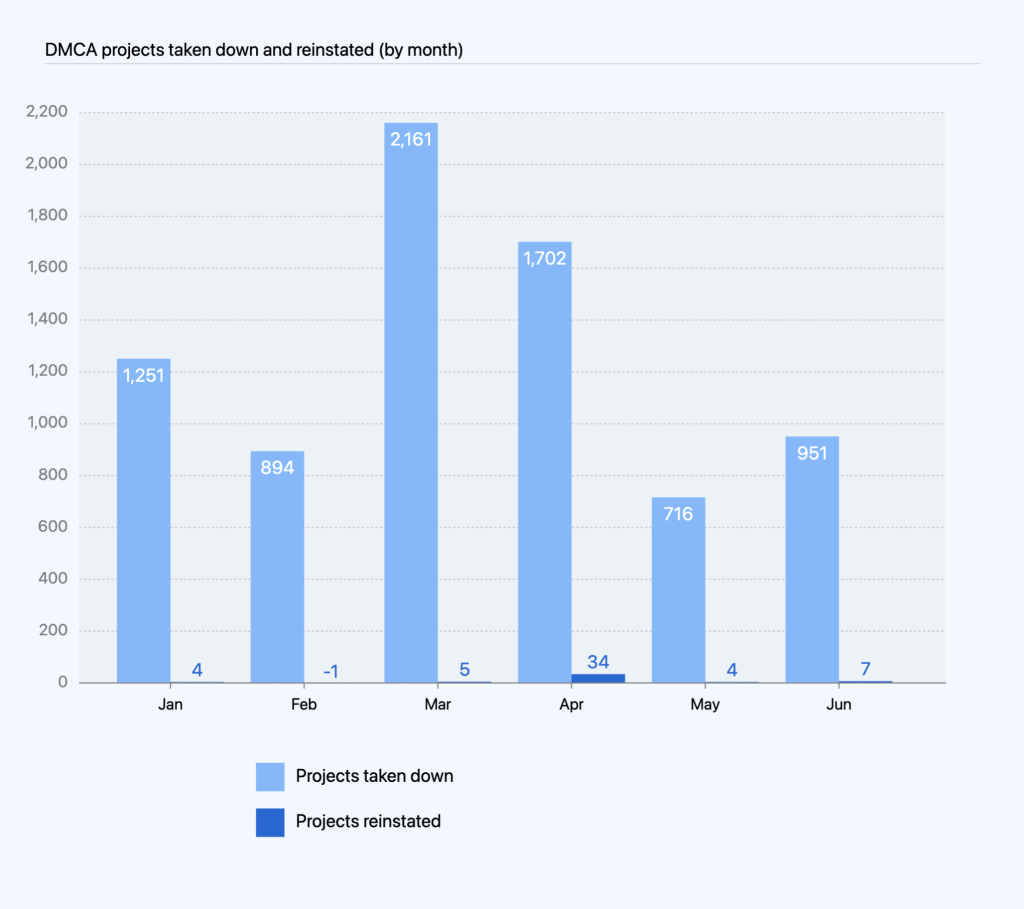
Often, a single takedown notice can encompass more than one project. For these instances, we looked at the total number of projects, including repositories, gists, and GitHub Pages sites that we had taken down due to DMCA takedown requests in January to June 2021. The monthly totals for projects reinstated—based on a counter notice, retraction, or reversal—ranged from negative one to 34. (“Negative one” represents a counter notice that we reversed because it turned out to be invalid.) The number of counter notices, retractions, and reversals we receive amounts to less than one to nearly two percent of the DMCA-related notices we get each month. This means that most of the time when we receive a valid takedown notice, the content comes down and stays down. In total from January to June 2021, we took down 7,675 projects and reinstated 53, which means that 7,622 projects stayed down.
Though 7,622 may sound like a lot of projects, it’s less than four one-thousandths of a percent of the repositories on GitHub.
It’s also counting many projects that are actually currently up. When a user made changes in response to a takedown notice, we counted that in the “stayed down” number. Because the reported content stayed down, we included it even if the rest of the project is still up. Those are in addition to the number reinstated.
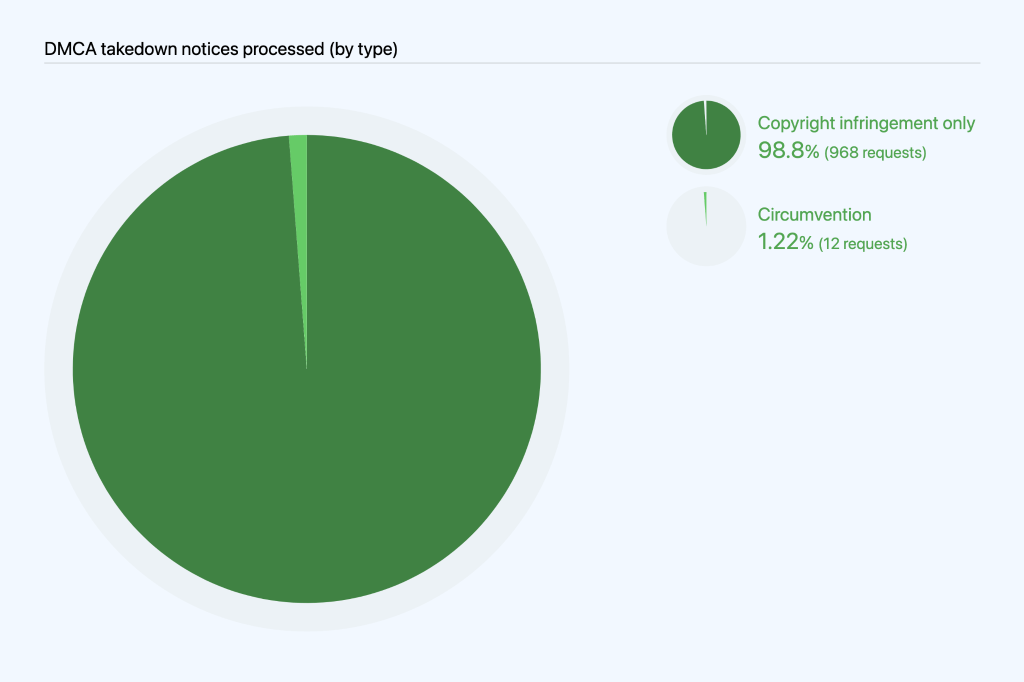
Circumvention claims
Within our DMCA reporting, we also look specifically at takedown notices that allege circumvention of a technical protection measure under section 1201 of the DMCA. GitHub requires additional information for a DMCA takedown notice to be complete and actionable where it alleges circumvention. We are able to estimate the number of DMCA notices we processed that include a circumvention claim by searching the takedown notices we processed for relevant keywords. On that basis, we can estimate that of the 980 notices we processed from January to June 2021, 12 notices, or 1.2%, related to circumvention. Although in recent years that percentage was increasing, it decreased in the first half of 2020:
- 63 or 3.0% of all notices in 2020
- 49 or 2.78% of all notices in 2019
- 33 or 1.83% of notices in 2018
- 25 or 1.81% of notices in 2017
- 36 or 4.74% of notices in 2016
- 18 or 3.56% of notices in 2015
Although takedown notices for circumvention violations have increased in the past few years, they are relatively few, and the proportion of takedown notices related to circumvention has fluctuated between roughly two and five percent of all takedown notices. While our current numbers are based on keyword search of the notices, we recently implemented categorization that will allow us to more closely track and report on this data in future transparency reports.
Incomplete DMCA takedown notices received
All of those numbers were about valid notices we received. We also received a lot of incomplete or insufficient notices regarding copyright infringement. Because these notices do not result in us taking down content, we do not currently keep track of how many incomplete notices we receive, or how often our users are able to work out their issues without sending a takedown notice.
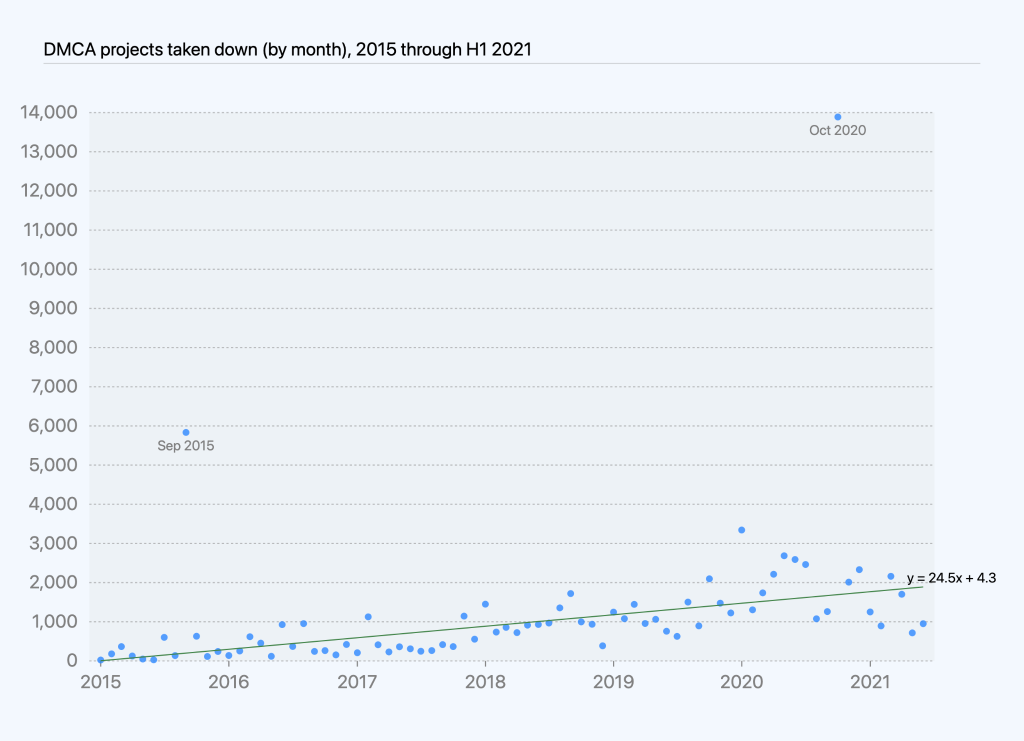
Trends in DMCA data
Based on DMCA data we’ve compiled over the last few years, we have seen an increase in DMCA notices received and processed from 2014 through the end of 2019. This increase is closely correlated with growth in repositories over the same period of time, so the proportion of repositories affected by takedowns has remained relatively consistent over time. Since January 2020, takedowns show a downward trend on average, with the exception of one takedown, youtube-dl, in October 2020 though we later reinstated that project.
Looking at the number of takedowns per month shows an increase of roughly two takedown notices per month, on average, affecting roughly 24 projects per month, on average, excluding youtube-dl and one other outlier.
Appeals and other reinstatements
Reinstatements, including as a result of appeals, are a key component of fairness to our users and respect for their right to a remedy for content removal or account restrictions. Reinstatements can occur when we undo an action we had taken to disable a repository, hide an account, or suspend a user’s access to their account in response to a Terms of Service violation. While sometimes this happens because a user disputes a decision to restrict access to their content (an appeal), in many cases, we reinstate an account or repository after a user removes content that violated our Terms of Service and agrees not to violate them going forward. For the purposes of this report, we looked at reinstatements related to:
- Abuse: violations of our Acceptable Use Policies, except for spam and malware
- Trade controls: violations of trade sanctions restrictions
Abuse-related violations
GitHub’s Terms of Service include content and conduct restrictions, set out in our Acceptable Use Policies and Community Guidelines. These restrictions include discriminatory content, doxxing, harassment, sexually obscene content, inciting violence, disinformation, and impersonation. Note: For the purposes of this report, we do not include appeals related to spam or malware, though our Terms of Service do restrict those kinds of content too.
When we determine a violation of our Terms of Service has occurred, we have a number of enforcement actions we can take. In keeping with our approach of restricting content in the narrowest way possible to address the violation, sometimes we can resolve an issue by disabling one repository (taking down one project) rather than acting on an entire account. Other times, we may need to act at the account level, for example, if the same user is committing the same violation across several repositories.
At the account level, in some cases we will only need to hide a user’s account content—for example, when the violation is based on content being publicly posted—while still giving the user the ability to access their account. In other cases, we will only need to restrict a user’s access to their account—for example, when the violation is based on their interaction with other users—while still giving other users the ability to access their shared content. For a collaborative software development platform like GitHub, we realized we need to provide this option so that other users can still access content that they might want to use for their projects.
We reported on restrictions and reinstatements by type of action taken. From January to June 2021, we hid 1,785 accounts and reinstated 120 hidden accounts. We restricted an account owner’s access to 33 accounts and reinstated it for 12 accounts. For 1,479 accounts, we both hid and restricted the account owner’s access, lifting both of those restrictions to fully reinstate 18 accounts and lifting one but not the other to partially reinstate five accounts. As for abuse-related restrictions at the project level, we disabled 877 projects and reinstated only 49 from January to June 2021. These do not count DMCA related takedowns or reinstatements (for example due to counter notices), which are reported on in the DMCA section, above).

Trade controls compliance
We’re dedicated to empowering as many developers around the world as possible to collaborate on GitHub. The US government has imposed sanctions on several countries and regions (including Crimea, Cuba, Iran, North Korea, and Syria), which means GitHub isn’t fully available in all of those places. However, GitHub will continue advocating with US regulators for the greatest possible access to code collaboration services to developers in sanctioned regions. For example, we secured a license from the US government to make all GitHub services fully available to developers in Iran. We are continuing to work toward a similar outcome for developers in Crimea and Syria, as well as other sanctioned regions. Our services are also generally available to developers located in Cuba, aside from specially designated nationals, including certain government officials.
Although trade control laws require GitHub to restrict account access from certain regions, we enable users to appeal these restrictions, and we work with them to restore as many accounts as we legally can. In many cases, we can reinstate a user’s account (grant an appeal), for example, after they returned from temporarily traveling to a restricted region or if their account was flagged in error. More information on GitHub and trade controls can be found here.
We started tracking sanctions-related appeals in July 2019. Unlike abuse-related violations, we must always act at the account level (as opposed to being able to disable a repository) because trade controls laws require us to restrict a user’s access to GitHub. From January to June 2021, 591 users appealed trade-control related account restrictions, as compared to 1,099 from January to June 2020 and 1,437 from July to December 2020. Of the 591 appeals we received from January to June 2021, we approved 531 and denied 56, and required further information to process in four cases. We also received 29 appeals that were mistakenly filed by users who were not subject to trade controls so we excluded them from our analysis below.
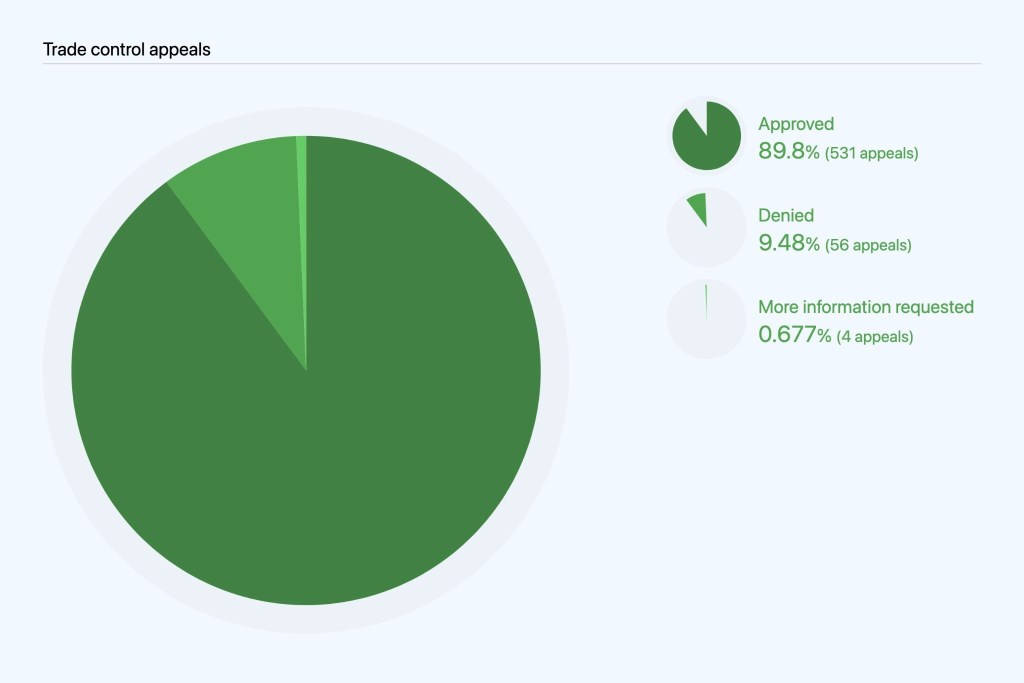
Appeals varied widely by region, with 455 reported from Crimea, 75 from Iran, 57 from Syria, and one from North Korea. In the vast majority of the cases, we were able to approve the appeals. While we received some appeals from Iran before our license to make GitHub fully available in the region was granted, ultimately we were able to grant all of them. In 10 cases, we were unable to assign an appeal to a region in our data. We marked them as “Unknown” in the table below and excluded them from regional totals in the chart below it.

Conclusion
GitHub remains committed to maintaining transparency and promoting free expression as an essential part of our commitment to developers. We aim to lead by example in our approach to transparency by providing in-depth explanation of the areas of content removal that are most relevant to developers and software development platforms. This time, we increased the frequency of our transparency reporting to cover a six-month (January to June 2021) period rather than a year. We’ve also shipped some tooling improvements that should enable us to cover some additional areas of interest to developers in future reports. Key to our commitment is ensuring we minimize the amount of data we disclose or the amount of content we take down as much as legally possible. Through our transparency reports, we’re continuing to shed light on our own practices, while also hoping to contribute to broader discourse on platform governance.
We hope you found this year’s report to be helpful and encourage you to let us know if you have suggestions for additions to future reports. For more on how we develop GitHub’s policies and procedures, check out our site policy repository.
Follow GitHub Policy on Twitter for updates about the laws and regulations that impact developers.
The post 2021 Transparency Report: January to June appeared first on The GitHub Blog.
GitHub CLI 2.0 includes extensions!
24 Aug 2021, 4:08 pm
GitHub CLI 2.0 supports extensions, allowing anyone to make custom commands that build on the core functionality of GitHub CLI.
Our goal with GitHub CLI 1.0 was to build amazing tooling that allows you to more seamlessly complete the most common developer workflows end-to-end in the terminal. We continued to build on that foundation with far better support for scripting and for working with GitHub Actions. But we knew that a one-size-fits-all tool would never meet every developer’s needs.
Today, we’re excited to release GitHub CLI 2.0, making it easy to create extensions to extend the tool in whatever ways you choose, and install extensions that others have created.
Creating extensions
Creating extensions is simple. Each extension is just a repository prefixed with gh-, and you can easily define the extension. We even built tooling into GitHub CLI itself to allow you to get started more quickly with gh extension create, which creates a scaffolded repository for you with some pre-written Bash that will help you get started.
To learn more about creating extensions, check out the documentation and explore the repositories for the example extensions below.
Example extensions
To get you started, our team built a few extensions ranging from GitHub-focused utilities like gh contribute to silly terminal-focused features like gh screensaver:
gh user-status
This extension allows you to quickly set your GitHub user status from your terminal to let others know when you’re unavailable or in focus mode.

gh branch
This extension is a fuzzy finder branch switcher that orders branches by recency and displays information about any associated pull requests.

gh contribute
Quickly find an issue to work on in an open source project using the contribute extension. This finds issues with help wanted or good first issue labels that have been created in the past year and do not yet have an associated pull request.

gh screensaver
Extensions don’t have to be serious—they can also just be fun or silly. We’ve got a few things like that already in GitHub CLI like gh repo garden. This extension invokes a full-screen ASCII screensaver.

gh triage
Our triage extension takes our process to triage issues in our open source repo and makes it more broadly usable. Instead of using this directly, you might take inspiration from it to build your own triage extension more specific to your project’s process.

Let us know what you build
Now that you’ve seen a few examples for inspiration, we’d love to hear about the extensions you create! Join the discussion in the GitHub CLI repository and share what you’ve built. We’re excited to see what great ideas you have to leverage GitHub CLI to improve everyone’s experience.
Install GitHub CLI today.
The post GitHub CLI 2.0 includes extensions! appeared first on The GitHub Blog.
The npm registry is deprecating TLS 1.0 and TLS 1.1
23 Aug 2021, 7:04 pm
Beginning October 4, 2021, all connections to npm websites and the npm registry—including for package installation—must use TLS 1.2 or higher.
GitHub is committed to ensuring the security of our services and the privacy of our users. Previously, we removed support for TLS 1.0 and TLS 1.1 for GitHub services. This year, we will similarly deprecate non-HTTPS access and TLS 1.0 and TLS 1.1 for npmjs.com, the public npm registry.
Fortunately, 99% of traffic to the npm registry is already using TLS 1.2, and we expect that the majority of users will not be affected by this deprecation. All Node.js binary releases beginning with v0.10.0 include support for TLS 1.2, so most users of recent Node.js and npm versions do not need to make any changes. However, some users may be on an unsupported version or may be using a custom-compiled Node.js binary without support.
Detailed timeline
While we will enforce a minimum of TLS 1.2 beginning October 4, 2021, we will also take steps to alert affected users to this change ahead of the deprecation.
- Beginning on August 24, users who are not using TLS 1.2 will see a notification when they run npm commands with a link to this blog post.
-
On September 22, we will enforce TLS 1.2 for one hour starting at 05:00 UTC.
-
On September 27, we will enforce TLS 1.2 for one hour starting at 10:00 UTC and again for one hour at 18:00 UTC.
-
Finally, on September 29, we will enforce TLS 1.2 for six hours beginning at 13:00 UTC.
Ensuring your compatibility
To make sure that your version of npm supports TLS 1.2, you can install a test package from an HTTPS endpoint that already has TLS 1.0 and TLS 1.1 disabled:
npm install -g https://tls-test.npmjs.com/tls-test-1.0.0.tgz
You should see this message:
Hello! The tls-test package was successfully downloaded and installed.
Congratulations! Your package manager appears to support TLS 1.2.
If you see a TLS error message instead, we encourage you to upgrade to a currently supported version of Node.js and the latest version of npm v7.
The post The npm registry is deprecating TLS 1.0 and TLS 1.1 appeared first on The GitHub Blog.
Enhanced support for citations on GitHub
19 Aug 2021, 4:12 pm
Making it easier for others to cite your work
GitHub now has built-in support for CITATION.cff files. This new feature enables academics and researchers to let people know how to correctly cite their work, especially in academic publications/materials. Originally proposed by the research software engineering community, CITATION.cff files are plain text files with human- and machine-readable citation information. When we detect a CITATION.cff file in a repository, we use this information to create convenient APA or BibTeX style citation links that can be referenced by others.
Why we think this matters
From real time dashboards tracking the global impact of COVID-19 to the software used to take the first ever image of a black hole, academics and researchers are responsible for some of the highest-impact work GitHub has the privilege of hosting.
Unfortunately, many researchers who devote significant time and effort producing high-quality open source software often find it hard to receive recognition for their work and suffer a career penalty within academia as a result. Yet the peer reviewed nature of open source makes it an ideal way to share research by providing example implementations, tests and datasets. The ability of researchers to be acknowledged for their open source contributions depends upon the ability of others to easily cite their work when they make use of it. We want to make these experiences easier for researchers and developers alike.
How this works
Under the hood, we’re using the ruby-cff RubyGem to parse the contents of the CITATION.cff file and build a citation string that is then shown in GitHub when someone browses a repository with one of those files1.
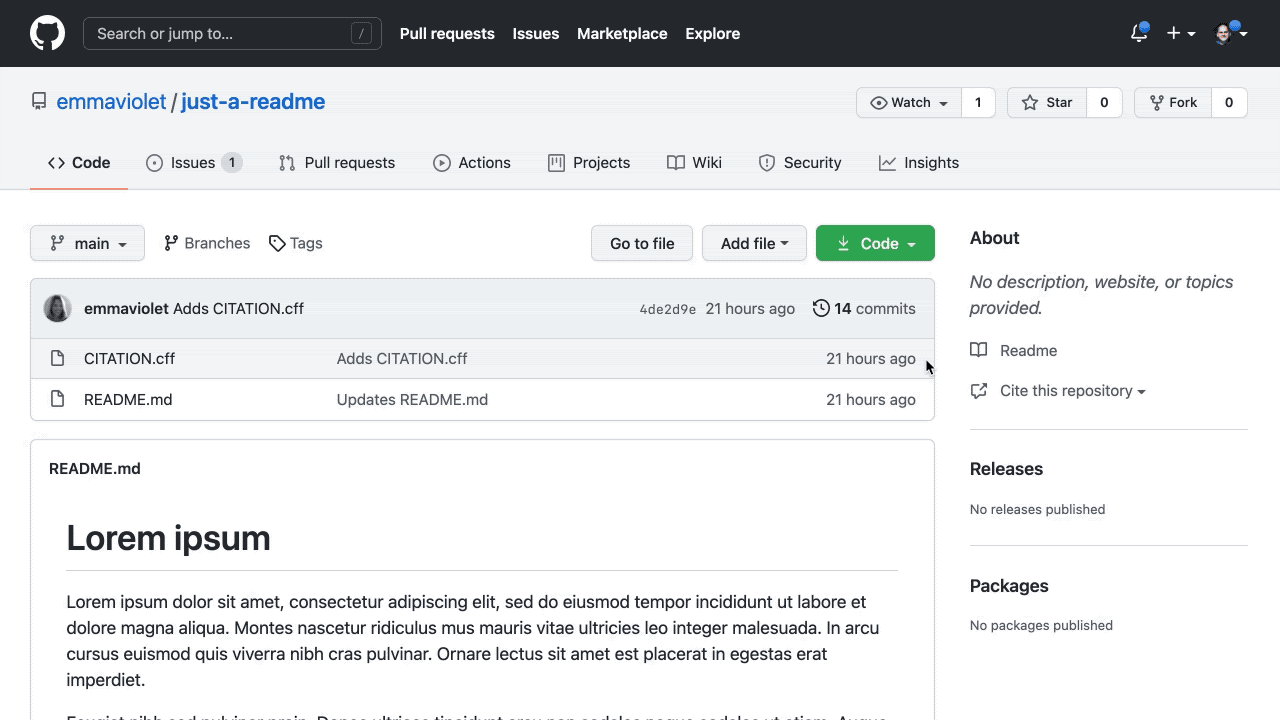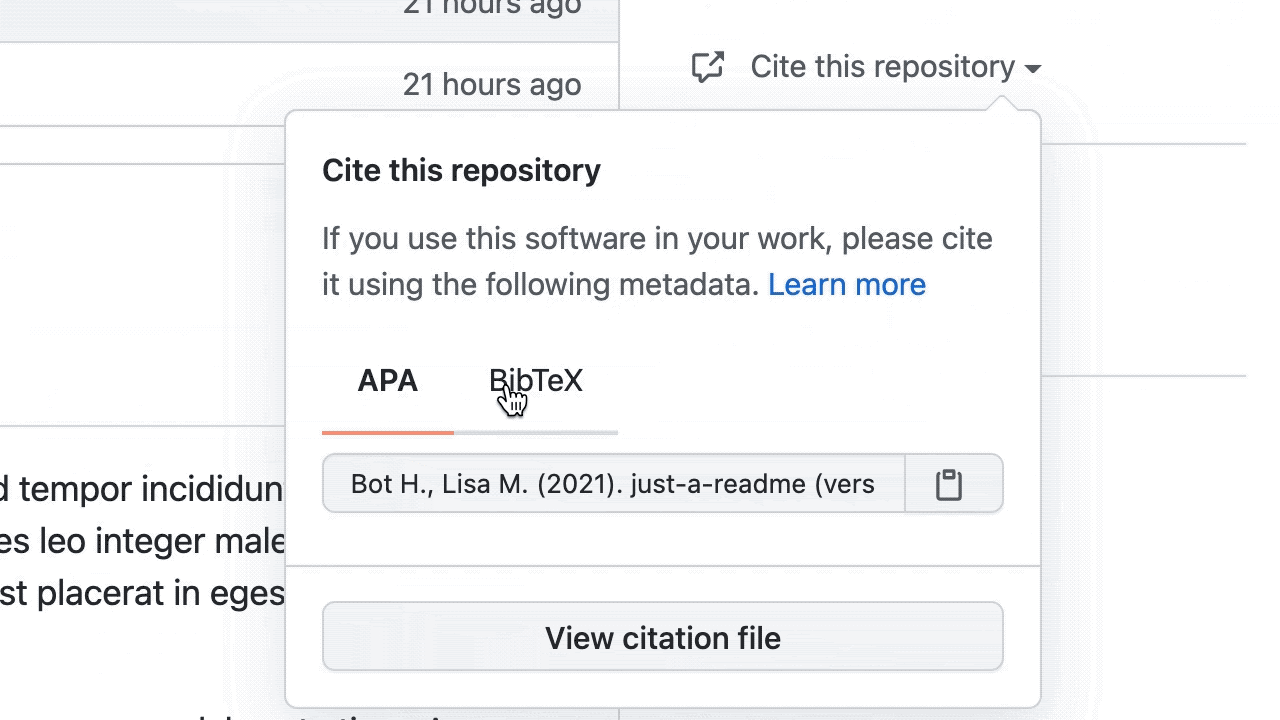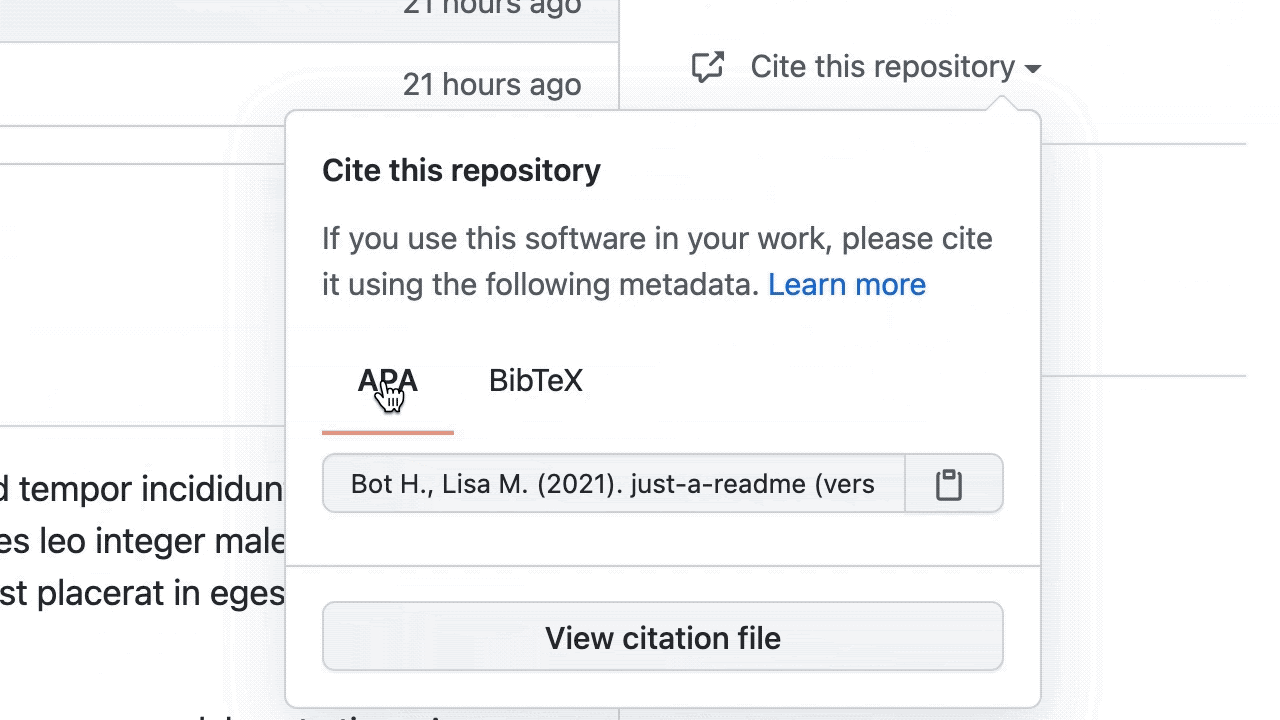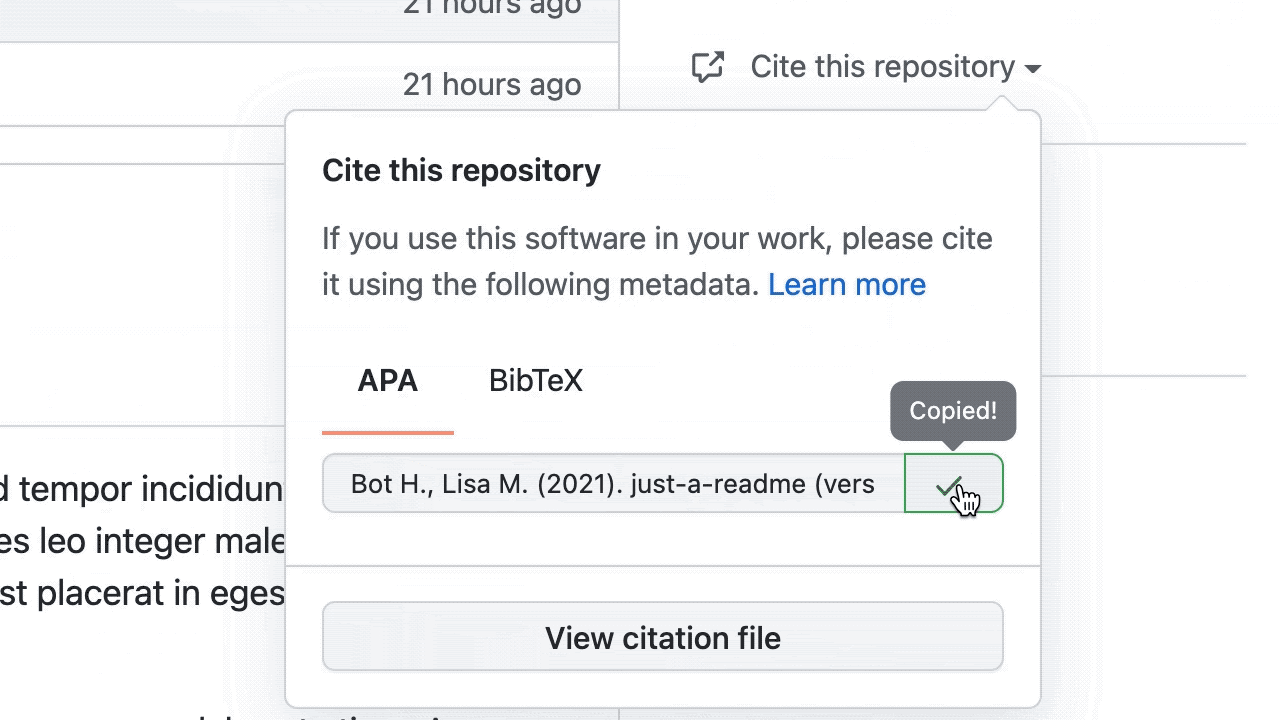
We’d love your feedback and help!
Software citation in academia is still relatively new and, as such, we’re expecting that some modifications and enhancements will be required as we mature this feature with the help and feedback of the research community. We’ve been testing the feature with the CFF (Citation File Format) creators2 and a small number of beta testers. Join us in the ruby-cff repository to discuss updates and improvements or check out the docs to get started adding a CITATION.cff file to your repository today.
1 Note we also detect citation files used by some communities (e.g., inst/CITATION for R packages) and link to them if we find one.
2 Stephan Druskat, German Aerospace Center (DLR), Berlin, Germany; Jurriaan Spaaks, Netherlands eScience Center, Amsterdam, Netherlands, https://orcid.org/0000-0002-7064-4069; Robert Haines, University of Manchester, Manchester, UK
The post Enhanced support for citations on GitHub appeared first on The GitHub Blog.
GitHub Discussions is out of beta
17 Aug 2021, 7:59 pm
Creating open source software today is so much more than the source code. It’s about managing the influx of great ideas, developing the next generation of maintainers, helping new developers learn and grow, and establishing the culture and personality of your community.
Over the past year, thousands of communities of all shapes and sizes have been using the GitHub Discussions beta as the central space for their communities to gather on GitHub in a productive and collaborative manner. We’ve learned a lot from your customer feedback and have shipped many highly requested features along the way, so we’re ready now for Discussions to enter its next chapter.
Today, we’re excited to announce that GitHub Discussions is officially out of beta. Let’s take a look at what you can do with Discussions and how top open source communities are using it.
What can you do with Discussions?
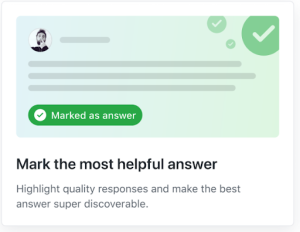
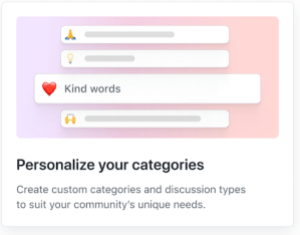
GitHub Discussions equips your community and core team with the tools and processes to make community engagement fun and collaborative. In addition to marking the most helpful answers, upvoting, customizing categories, and pinning big announcements, we’ve added the following features to Discussions to help maintainers stay on top of community management.
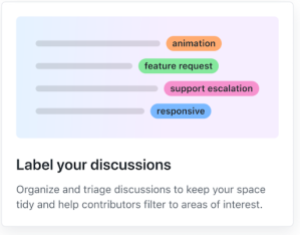
- Label your discussions. Maintainers can now organize and triage discussions with labels to keep the space tidy and help members filter to areas of interest.
- Connect to your apps. Power users can integrate with GitHub Actions or any existing workflows via the new Discussions GraphQL API and Webhooks.
- Respond on-the-go with mobile. Check in and respond to discussions whenever and wherever is most convenient with GitHub Discussions on mobile.
Just because Discussions is now out of beta doesn’t mean we’ll stop shipping your highly requested features. We’re excited to share upcoming features that will help maintainers become more connected to their communities than ever.
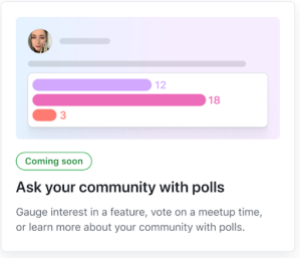
- Ask your community with polls. With the new Polls category, maintainers will be able to gauge interest in a feature, vote on a meetup time, or learn more about their communities.
- Monitor community insights. Soon you’ll be able to track the health and growth of your community with a dashboard full of actionable data.
As a recap, here’s what you can do with Discussions, including a sneak peek at what’s to come.

What are open source communities saying about Discussions?
We’ve been very intentional in partnering closely with vibrant open source communities. Managing an open source community is already burdensome enough, and Discussions has made maintainers’ lives easier, not harder.
“GitHub Discussions has allowed us to grow the Next.js community in the same tool that we use to collaborate. This has allowed us to collaborate and interact with our community that has grown by 900% since moving to GitHub Discussions.”
~ @timneutkens, maintainer of Next.js
“ Discussions have enabled the communities I work with to engage in a space dedicated to them that’s accessible, removing the necessity to set up bespoke solutions or to take on the burden of maintaining additional external services.”
~ @bnb, maintainer of Node
“We had forum software before, but allowing all our contributors to find the forum on one platform has done wonders for the engagement. Being able to easily link between issues and discussions, allowing everyone to keep track of the history, has been one of those delightful experiences that sometimes make tech feel like magic (again).”
~ @SMillerDev, maintainer of Homebrew
“GitHub Discussions enabled us to make feature launches more community-centered as each feature and experiment got its own discussion in a dedicated space outside of the issue tracker. With its threading support, we were able to individually address comments without losing them in the larger discussion. A great side-effect of this is that our issue tracker is now separate from questions, feature requests, and general chit-chat.”
~ @LekoArts, maintainer of Gatsby
How do I get started?
If you are an admin or a maintainer of a repository, you can enable Discussions under “Features” in the repository settings. Happy discussion-ing!
For feedback and questions, visit GitHub Discussions feedback. For more information, visit GitHub Discussions documentation.
The post GitHub Discussions is out of beta appeared first on The GitHub Blog.
Highlights from Git 2.33
16 Aug 2021, 11:15 pm
The open source Git project just released Git 2.33 with features and bug fixes from over 74 contributors, 19 of them new. We last caught up with you on the latest in Git when 2.31 was released. Here’s a look at some of the most interesting features and changes since then.
Geometric repacking
In a previous blog post, we discussed how GitHub was using a new mode of git repack to implement our repository maintenance jobs. In Git 2.32, many of those patches were released in the open-source Git project. So, in case you haven’t read our earlier blog post, or just need a refresher, here are some details on geometric repacking.
Historically, git repack did one of two things: it either repacked all loose objects into a new pack (optionally deleting the loose copies of each of those objects), or it repacked all packs together into a single, new pack (optionally deleting the redundant packs).
Generally speaking, Git has better performance when there are fewer packs, since many operations scale with the number of packs in a repository. So it’s often a good idea to pack everything together into one single pack. But historically speaking, busy repositories often require that all of their contents be packed together into a single, enormous pack. That’s because reachability bitmaps, which are a critical optimization for server-side Git performance, can only describe the objects in a single pack. So if you want to use bitmaps to effectively cover many objects in your repository, those objects have to be stored together in the same pack.
We’re working toward removing that limitation (you can read more about how we’ve done that), but one important step along the way is to implement a new repacking scheme that trades off between having a relatively small number of packs, and packing together recently added objects (in other words, approximating the new objects added since the previous repack).
To do that, Git learned a new “geometric” repacking strategy. The idea is to determine a (small-ish) set of packs which could be combined together so that the remaining packs form a geometric progression based on object size. In other words, if the smallest pack has N objects, then the next-largest pack would have at least 2N objects, and so on, doubling (or growing by an arbitrary constant) at each step along the way.
To better understand how this works, let’s work through an example on seven packs. First, Git orders all packs (represented below by a green or red square) in ascending order based on the number of objects they contain (the numbers inside each square). Then, adjacent packs are compared (starting with the largest packs and working toward the smaller ones) to ensure that a geometric progression exists:
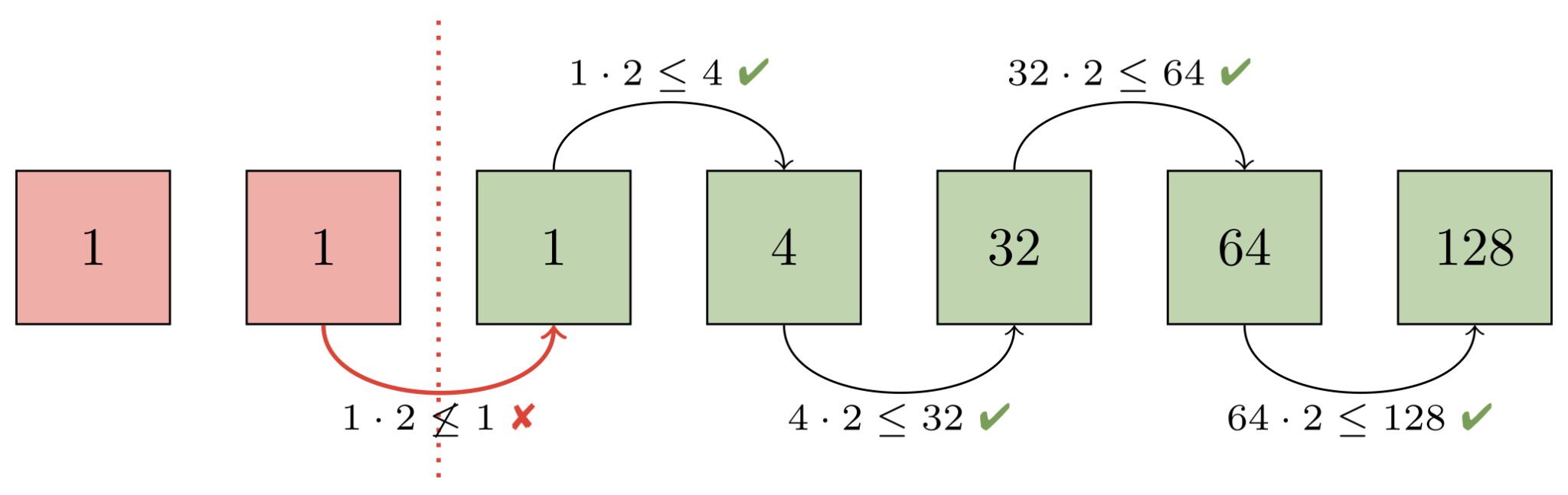
Here, the progression is broken between the second and third pack. That’s because both of those packs each have the same number of objects (in this case, just one). Git then decides that at least the first two packs will be contained in a new pack which is designed to restore the geometric progression. It then needs to figure out how many larger packs must also get rolled up in order to maintain the progression:
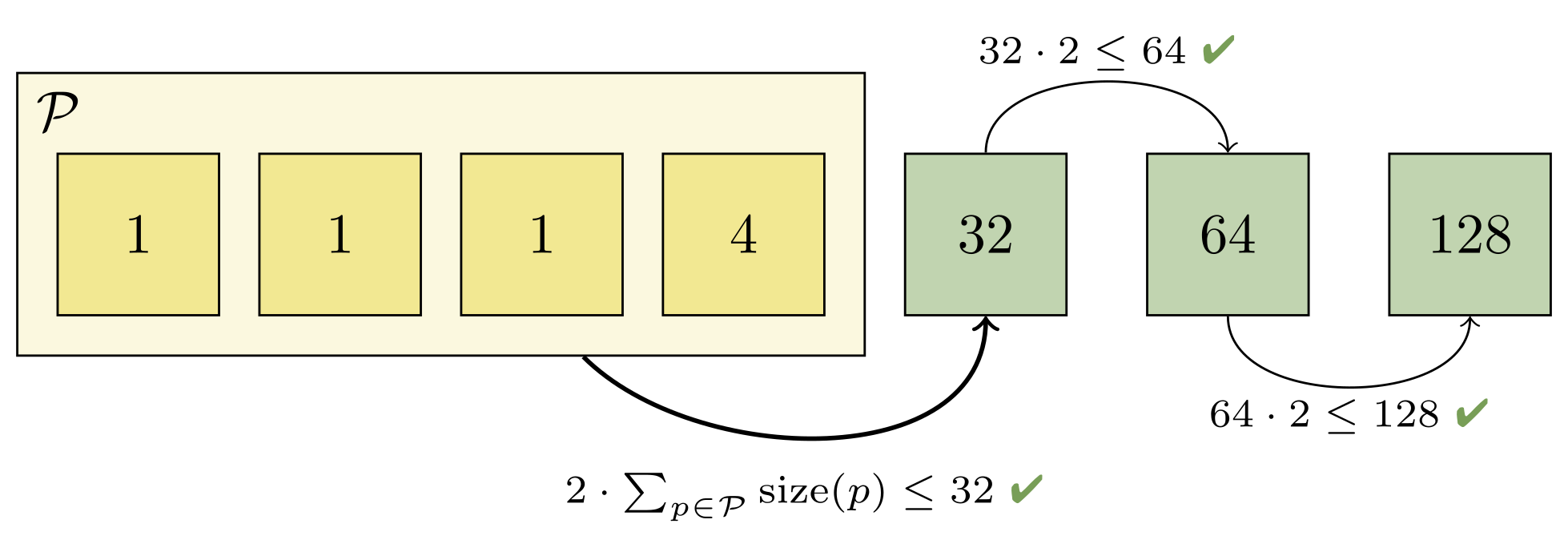
Combining the first two packs would give us two objects, which would still be too large to fit into the progression (since the next largest pack only has one object). But rolling up the first four packs is sufficient, since the fifth pack contains more than twice as many objects as the first four packs combined:
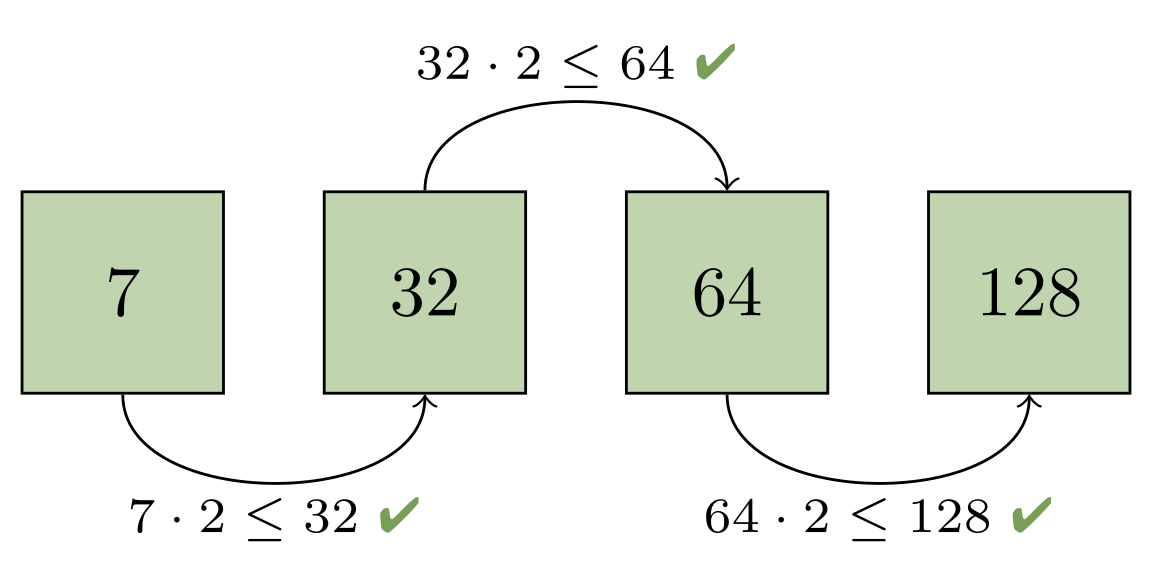
You can try this out yourself by comparing the pack sizes on a repository on your laptop before and after geometric repacking with the following script:
$ packsizes() {
find .git/objects/pack -type f -name '*.pack' |
while read pack; do
printf "%7d %s\n" \
"$(git show-index < ${pack%.pack}.idx | wc -l)" "$pack"
done | sort -rn
}
$ packsizes # before
$ git repack --geometric=2 -d
$ packsizes # after
We have also contributed patches to write the new on-disk reverse index format for multi-pack indexes. This format will ultimately be used to power multi-pack bitmaps by allowing Git to map bit positions back to objects in a multi-pack index.
Together, these two features will make it possible to cover the objects in the resulting packs with a reachability bitmap, even when there’s more than one pack remaining. Those patches are still being polished and reviewed, but expect an update from us when they’re incorporated into a release.
merge-ort: a new merge strategy
When Git performs a merge between two branches, it uses one of several “strategy” backends to resolve the changes. The original strategy is simply called resolve and does a standard three-way merge. But that default was replaced early in Git’s history by merge-recursive, which had two important advantages:
- In the case of “criss-cross” merges (where there is not a single
common point of divergence between two branches), the strategy
performs a series of merges (recursively, hence the name) for each
possible base. This can resolve cases for which theresolve
strategy would produce a conflict. -
It detects file-level renames along each branch. A file that was
modified on one side but renamed on the other will have its
modifications applied to the renamed destination (rather than
producing a very confusing conflict).
merge-recursive served well as Git’s default for many years, but it had a few shortcomings. It was originally written as an external Python script which used Git’s plumbing commands to examine the data. This was later rewritten in C, which provided a speed boost. But its code organization and data structures still reflected its origins: it still operated primarily on Git’s “index” (the on-disk area where changes are collected for new commits) and the working tree.
This resulted in several bugs over the years around tricky corner cases (for example, this one or some of these).
merge-recursive‘s origins also made it harder to optimize and extend the code. Merge time isn’t a bottleneck in most workflows, but there are certainly large cases (especially involving renames) where merge-recursive could be very slow. Likewise, the merge backend is used for many operations that combine two sets of changes. A cherry-pick or rebase operation may perform a series of merges, and speeding them up has a noticeable effect.
The merge-ort strategy is a from-scratch rewrite with the same concepts (recursion and rename-detection), but solving many of the long-standing correctness and performance problems. The result is much faster. For a merge (but a large, tricky one containing many renames), merge-ort gains over a 500x speedup. For a series of similar merges in a rebase operation, the speedup is over 9000x (because merge-ort is able to cache and reuse some computation common to the merges). These cases were selected as particularly bad for the merge-recursive algorithm, but in our testing of typical cases we find that merge-ort is always a bit faster than merge-recursive. The real win is that merge-ort consistently performs at that fast speed while merge-recursive has high variance.
On top of that, the resulting code is cleaner and easier to work with. It fixes some known bugs in merge-recursive. It’s more careful about not accessing unchanged parts of the tree, meaning that people working with partial clones should be able to complete more merges without having to download extra objects. And because it doesn’t rely on the index or working tree while performing the merge, it will open up new opportunities for tools like git log to show merges (for example, a diff between the vanilla merge result and the final committed state, which shows how the author resolved any conflicts).
The new merge-ort is likely to become the default strategy in a future version of Git. In the meantime, you can try it out by running git merge -s ort or setting your pull.twohead config to ort (despite the name, this is used for any merge, not just git pull). You might not see all of the same speedups yet; some of them will require changes to other parts of Git (for example, rebase helping pass the cached data between each individual merge).
Rather than link to the source commits, of which there are over 150 spread across more than a dozen branches, check out this summary from the author on the mailing list. Or if you want to go in-depth, check out his series of blog posts diving into the rationale and the details of various optimizations:
part 1
part 2
part 3
part 4
part 5
All that
Per our usual style, we like to cover two or three items from recent releases in detail, and then a dozen or so smaller topics in lesser detail. Now that we’ve gotten the former out of the way, here’s a selection of interesting changes in Git 2.32 and 2.33:
- You might have used
git rev-listto drive Git’s history traversal machinery.
It can be really useful when scripting, especially if you need to list the
commits/objects between two endpoints of history.git rev-listhas a very handy--prettyflag which allows it to format the
commits it encounters.--prettycan display information about a commit
(such as its author, author date, hash, parts of its message, and so on). But it can be difficult to use when scripting. Say you want the list of days that you wrote commits. You might think to run something like:$ git rev-list --format=%as --author=peff HEAD | head -4 commit 27f45ccf336d70e9078075eb963fb92541da8690 2021-07-26 commit 8231c841ff7f213a86aa1fa890ea213f2dc630be 2021-07-26(Here, we’re just asking
rev-listto show the author date of each commit
written by @peff.) But what are those lines interspersed withcommit?
That’s due to a historical quirk whererev-listfirst writes a line
containingcommit <hash>before displaying a commit with--pretty.
In order to keep backwards compatibility with existing scripts, the
quirk must remain.In Git 2.33, you can specify
--no-commit-headerto opt out of this
historical design decision, which makes scripting the above much easier:
[source]
-
Here’s a piece of Git trivia: say you wanted to list all blobs smaller than 200 bytes. You might consider using
rev-list‘s--filterfeature (the same mechanism that powers partial clones) to accomplish this. But what would you expect the following to print?$ git rev-list --objects --no-object-names \ --filter=blob:limit=200 v2.32.0..v2.33.0 \ | git cat-file --batch-check='%(objecttype)' | sort -u(In this example, we’re asking
rev-listto list all objects introduced
since version 2.32, filtering all blobs which are larger than 200 bytes.
Then, we askcat-fileto print out the types of all of those objects and
list the unique values).If you expected just “blob,” you’d be wrong! The
--filter=blob:limit=200
only filters blobs. It doesn’t stoprev-listfrom printing non-blob objects.In Git 2.32, you can solve this problem by excluding the blobs with a new
--filter=object:type=<type>filter. Since multiple--filters are combined together by taking the union of their results, this does the trick:$ git rev-list --objects --no-object-names \ --filter=object:type=blob \ --filter=blob:limit=200 \ --filter-provided-objects v2.32.0..v2.33.0 \ | git cat-file --batch-check='%(objecttype)' | sort -u blob(Here,
--filter-provided-objectsallowsrev-listto apply the same
filters to the tips of its traversal, which are exempt from filtering by
default).[source]
-
You might be aware of
git log‘s “decorate” feature, which adds output to
certain commits indicating which references point at them. For example:$ git log --oneline --decorate | head -1 2d755dfac9 (HEAD -> master, tag: v2.33.0-rc1, origin/master, origin/HEAD) Git 2.33-rc1By default, Git loads these decorations if the output is going to a terminal or if
--decoratewas given. But loading these decorations can be wasteful in examples like these:$ git log --graph --decorate --format='%h %s' | head -1 2d755dfac9 Git 2.33-rc1Here, Git would have wasted time loading all references since
--decorate
was given but its--formatdoesn’t cause any decoration information to be
written to the output.Git 2.33 learned how to detect if loading reference decorations will be useful (if they will show up in the output at all), and it optimizes the loading process to do as little work as possible even when we are showing decorations, but the decorated object does not appear in the output.
[source]
-
Speaking of
git log --formatplaceholders, Git 2.32 comes with a couple of
new ones. You can now display the author and committer date in the “human” format (which we talked about when it was introduced back in Git 2.21) with%ahand%ch.The new
%(describe)placeholder makes it possible to include the output of
git describealongside commits displayed in the log. You can use%(describe)to get the bare output ofgit describeon each line, or you can write%(describe:match=<foo>,exclude=<bar>)to control the--matchand--excludeoptions. -
Have you ever been working on a series of patches and realized that you
forgot to make a change a couple of commits back? If you have, you might
have been tempted toresetback to that point, make your changes, and then
cherry-pickthe remaining commits back on top.There’s a better way: if you make changes directly in your working copy
(even after you wrote more patches on top), you can make a special “fixup”
commit with thegit commit --fixupoption. This option creates a new
commit with the changes that you meant to apply earlier. Then, when you
rebase, Git automatically sequences the fixup commit in the right place and
squashes its contents back where you originally wanted them.But what if instead of changing the contents of your patch, you wanted to
change the log message itself? In Git 2.32,git commitlearned a new
--fixup=(amend|reword):<commit>option, which allows you to tweak the
behavior of--fixup. With--fixup=amend, Git will replace the log
message and the patch contents with your new one, all without you having to
pause your workflow to rebase.
If you use
--fixup=rewordinstead, you can tell Git to just replace the
log message while leaving the contents of the reworded patch untouched.[source]
-
You might be familiar with Git’s “trailers” mechanism, the structured
information that can sometimes appear at the end of a commit. For example, you might have seen trailers used to indicate the Developer’s Certificate of Origin at the end of a commit withSigned-off-by. Or perhaps you have seen projects indicate who reviewed what withReviewed-by.These trailers are typically written by hand when crafting a commit message
in your editor. But now Git can insert these trailers itself via the new
--trailerflag when runninggit commit. Trailers are automatically
inserted in the right place so that Git can parse them later on. This can be
especially powerful with the new--fixupoptions we just talked about. For
example, to add missing trailers to a commit,foo:$ git commit --no-edit \ --fixup=reword:foo \ --trailer='Signed-off-by=Mona Lisa Octocat <mona@github.com>' $ EDITOR=true git rebase -i --autosquash foo^[source]
-
Here’s the first of two checkout-related tidbits. Git uses the
git checkoutprogram to update your working copy (that is, the actual files on disk that you read/edit/compile) to match a particular state in history. Until very recently,git checkoutworked by creating, modifying, or removing files and directories one-by-one.When spinning-disk drives were more common, any performance improvement that
could be had by parallelizing this process would have been negligible, since
hard-disk drives are more frequently I/O-bound than more modern solid-state
and NVMe-based drives.(Of course, this is a little bit of an over-simplification: sometimes having
more tasks gives the I/O scheduler more items to work with, which actually
can help most on a spinning disks, since requests can be ordered by platter
location. It’s for this reason that Git refreshes the index using parallel
lstat()threads.)In Git 2.32,
git checkoutlearned how to update the working copy in
parallel by dividing the updates it needs to execute into different groups,
then delegating each group to a worker process. There are two knobs to
tweak:checkout.workersconfigures how many workers to use when updating the
tree (and you can use ‘0’ to indicate that it should use as many workers
as there are logical CPU cores).-
checkout.thresholdForParallelismconfigures how many updates are
necessary before Git kicks in the parallel code paths over the
sequential ones.
Together, these can provide substantial speed-ups when checking out repositories in different environments, as demonstrated here.
-
In an earlier blog post, Derrick Stolee talked about sparse checkouts. The goal of sparse checkout is to make it feel like the repository you’re working in is small, no matter how large it actually is.
Even though sparse checkouts shrink your working copy (that is, the number of files and directories which are created on disk), the index–the data structure Git uses to create commits–has historically tracked every file in the repository, not just those in your sparse checkout. This makes operations that require the index slow in sparse checkouts, even when the checkout is small, since Git has to compute and rewrite the entire index for operations which modify the index.
Git 2.32 has updated many of the index internals to only keep track of files in the sparse checkout and any directories at the boundary of the sparse checkout when operating in cone mode.
Different commands that interact with the index each have their own
assumptions about how the index should work, and so they are in the process
of being updated one-by-one. So far,git checkout,git commit, andgithave been updated, and more commands are coming soon.
statusYou can enable the sparse index in your repository by enabling the
index.sparseconfiguration variable. But note, while this feature is still
being developed it’s possible that Git will want to convert the sparse index
to a full one on the fly, which can be slower than the original operation you were performing. In future releases, fewer commands will exhibit this behavior until all index-related commands are converted over. -
Here’s a short and sweet one from 2.32: a new
SECURITY.mddocument was introduced to explain how to securely report vulnerabilities in Git. Most importantly, the email address of the security-focused mailing list (git-security@googlegroups.com) is listed more prominently. (For the extra-curious, the details of how embargoed security releases are coordinated and distributed are covered as well.)[source]
Finally, a number of bitmap-related optimizations were made in the last couple
of releases. Here are just a few:
- When using reachability bitmaps to serve, say, a fetch request, Git marks
objects which the client already has as “uninteresting,” meaning that they
don’t need to be sent again. But until recently, if a tag was marked as
uninteresting, the object being pointed at was not also marked as
uninteresting.Because the haves and wants are combined with an
AND NOT, this bug didn’t
impact correctness. But it can cause Git to waste CPU cycles since it can
cause full-blown object walks when the objects that should have been marked
as uninteresting are outside of the bitmap. Git 2.32 fixes this bug by
propagating the uninteresting status of tags down to their tagged objects.[source]
-
Some internal Git processes have to build their own reachability bitmaps on
the fly (like when an existing bitmap provides complete coverage
up to the most recent branches and tags, so a supplemental bitmap must be
generated and thenOR‘d in). When building these on-the-fly bitmaps, we
can avoid traversing into commits which are already in the bitmap, since we
know all of the objects reachable from that commit will also be in the
bitmap, too.But we don’t do the same thing for trees. Usually this isn’t a big deal.
Root trees are often not shared between multiple commits, so the
walk is often worthwhile. But traversing into shared sub-trees is wasteful
if those sub-trees have already been seen (since we know all of their
reachable objects have also been seen).Git 2.33 implements the same optimization we have for skipping already-seen
commits for trees, too, which has provided some substantial speed-ups,
especially for server-side operations.[source]
-
When generating a pack while using reachability bitmaps, Git will try to
send a region from the beginning of an existing packfile more-or-less
verbatim. But there was a bug in the “Enumerating objects” progress meter
that caused the server to briefly flash the number of reused objects and
then reset the count back to zero before counting the objects it would
actually pack itself.This bug was somewhat difficult to catch or notice because the pack reuse
mechanism only recently became more aggressive, and because you have to see it at exactly the right moment in your terminal to notice.But regardless, this bug has been corrected, so now you’ll see an accurate
progress meter in your terminal, no matter how hard you stare at it.[source]
…And a bag of chips
That’s just a sample of changes from the latest couple of releases. For more, check out the release notes for 2.32 and 2.33, or any previous version in the Git repository.
The post Highlights from Git 2.33 appeared first on The GitHub Blog.
Securing your GitHub account with two-factor authentication
16 Aug 2021, 6:00 pm
We’ve invested a lot in making sure that GitHub’s developer communities have access to the latest technology to protect their accounts from compromise by malicious actors. Some of these investments include verified devices, preventing the use of compromised passwords, WebAuthn support, and supporting security keys for SSH Git operations. These security features make it easier for developers to have strong account authentication on the platform, and today, we’re excited to share a few updates in this area.
No more password-based authentication for Git operations
In December, we announced that beginning August 13, 2021, GitHub will no longer accept account passwords when authenticating Git operations and will require the use of strong authentication factors, such as a personal access token, SSH keys (for developers), or an OAuth or GitHub App installation token (for integrators) for all authenticated Git operations on GitHub.com. With the August 13 sunset date behind us, we no longer accept password authentication for Git operations.
Enabling two-factor authentication (2FA) on your GitHub account
If you have not done so already, please take this moment to enable 2FA for your GitHub account. The benefits of multifactor authentication are widely documented and protect against a wide range of attacks, such as phishing. There are a number of options available for using 2FA on GitHub, including:
- Physical security keys, such as YubiKeys
- Virtual security keys built-in to your personal devices, such as laptops and phones that support WebAuthn-enabled technologies, like Windows Hello or Face ID/Touch ID
- Time-based One-Time Password (TOTP) authenticator apps
- Short Message Service (SMS)
While SMS is available as an option, we strongly recommend the use of security keys or TOTPs wherever possible. SMS-based 2FA does not provide the same level of protection, and it is no longer recommended under NIST 800-63B. The strongest methods widely available are those that support the emerging WebAuthn secure authentication standard. These methods include physical security keys as well as personal devices that support technologies such as Windows Hello or Face ID/Touch ID. We are excited and optimistic about WebAuthn, which is why we have invested early and will continue to invest in it at GitHub.
Commit verification with your security key
After securing your account with a security key, there’s more you can do with them. You can also digitally sign your git commits using a GPG key stored on your security key. Here is a detailed configuration guide for setting up your YubiKey with GitHub for commit verification and for SSH-based authentication. We’ve also partnered with Yubico to create a step-by-step video guide to help you enable your security key for SSH keys and commit verification.
Getting a security key
 Lastly, in 2015, we announced our support of Universal 2 Factor Authentication and created GitHub branded YubiKeys to mark the occasion. We thought it was fitting for this moment to make another batch with Yubico. As we continue our efforts to secure GitHub and the developer communities that depend on it, we are once again offering branded YubiKey 5 NFC and YubiKey 5C NFC keys! Get yours while supplies last at The GitHub Shop.
Lastly, in 2015, we announced our support of Universal 2 Factor Authentication and created GitHub branded YubiKeys to mark the occasion. We thought it was fitting for this moment to make another batch with Yubico. As we continue our efforts to secure GitHub and the developer communities that depend on it, we are once again offering branded YubiKey 5 NFC and YubiKey 5C NFC keys! Get yours while supplies last at The GitHub Shop.

The post Securing your GitHub account with two-factor authentication appeared first on The GitHub Blog.
Related Posts

github.blog – p.382
2025-01-09

33")