13 Jul 2025, 3:32 am
Model Quantization and Optimization: Making LLMs Efficient and Accessible

Model Quantization and Optimization: Making LLMs Efficient and Accessible
As Large Language Models (LLMs) continue to grow in size and capability, the computational demands for deploying them have become a significant challenge. A 175-billion parameter model like GPT-3 requires hundreds of gigabytes of memory and substantial computational resources, making deployment expensive and often impractical for many applications. This is where model quantization and optimization techniques become game-changers, enabling efficient deployment without sacrificing too much performance.
Understanding the Challenge
Modern LLMs face several resource constraints that make optimization crucial:
- Memory Requirements: Large models can require 100GB+ of RAM for inference, making them inaccessible for many deployment scenarios
- Computational Overhead: Processing billions of parameters for each inference creates significant latency and energy consumption
- Cost Implications: Running large models on high-end hardware translates to substantial operational costs
- Edge Deployment: Mobile devices, embedded systems, and edge computing environments have strict resource limitations
What is Model Quantization?
Model quantization is the process of reducing the precision of model weights and activations, typically from 32-bit floating point (FP32) to lower precision formats like 16-bit (FP16), 8-bit (INT8), or even 4-bit representations.
The Mathematics Behind Quantization
In standard neural networks, weights are stored as 32-bit floating point numbers, providing high precision but consuming significant memory. Quantization maps these high-precision values to a smaller set of discrete values.
Linear Quantization Formula:
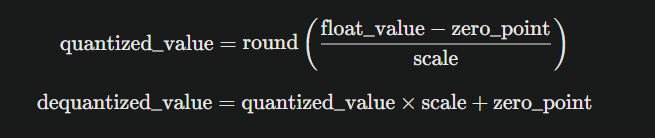
Where:
- scale determines the step size between quantized values
- zero_point handles asymmetric distributions
- round() maps to the nearest integer
Types of Quantization
Post-Training Quantization (PTQ)
Applied after model training is complete, PTQ is faster to implement but may have more accuracy loss. PTQ is good for quick deployment optimization and doesn’t require access to training data.
Quantization-Aware Training (QAT)
Quantization effects are simulated during training, providing better accuracy preservation but requiring retraining. QAT is more complex but yields superior results by allowing the model to adapt to quantization effects during training.
Dynamic vs. Static Quantization
- Dynamic: Quantization parameters computed during inference
- Static: Parameters pre-computed using calibration data
Quantization Strategies for LLMs
Weight-Only Quantization
The simplest approach focuses on quantizing model weights while keeping activations in higher precision.
Advantages:
- Reduces memory footprint by 2–4x
- Relatively simple to implement
- Minimal accuracy degradation
Full Integer Quantization
Quantizes both weights and activations to integers, maximizing efficiency gains.
Benefits:
- Maximum memory and compute savings
- Enables deployment on integer-only hardware
- Significant speedup potential
Challenges:
- Requires careful calibration
- May need fine-tuning to maintain accuracy
- More complex implementation
Mixed-Precision Approaches
Different layers use different precision levels based on their sensitivity to quantization.
Strategy:
- Keep attention layers in higher precision
- Use lower precision for feed-forward layers
- Maintain embeddings in FP16 or FP32
Advanced Quantization Techniques
GPTQ (Gradient-based Post-training Quantization)
GPTQ is specifically designed for transformer models and has shown excellent results with LLMs.
Key Features:
- Uses second-order information (Hessian) for better weight selection
- Processes one transformer block at a time
- Achieves 4-bit quantization with minimal accuracy loss
Process:
- Compute Hessian matrix for each layer
- Use optimal brain surgeon algorithm to select weights for quantization
- Apply quantization while minimizing error propagation
GPTQ can quantize GPT models with 175 billion parameters in approximately four GPU hours, reducing the bitwidth down to 3 or 4 bits per weight, with negligible accuracy degradation.
AWQ (Activation-aware Weight Quantization)
AWQ protects salient weights that correspond to important activations.
Innovation:
- Analyzes activation patterns to identify critical weights
- Keeps important weights in higher precision
- Quantizes less critical weights more aggressively
Results:
- Better accuracy preservation than uniform quantization
- Maintains model performance even at 4-bit precision
- Protecting only 1% salient weights can greatly reduce quantization error
SmoothQuant
Addresses the challenge of quantizing activations in transformer models.
Problem: Transformer activations have outliers that are difficult to quantize
Solution: Smooth activation distributions by migrating difficulty to weights
Process:
- Identify activation outliers in attention and feed-forward layers
- Apply smoothing transformations to reduce outlier magnitude
- Quantize both weights and activations effectively
SmoothQuant enables an INT8 quantization of both weights and activations for all the matrix multiplications in LLMs, demonstrating up to 1.56x speedup and 2x memory reduction with negligible loss in accuracy.
KV Cache Quantization
Recent advances focus on quantizing the key-value cache, which becomes a major memory bottleneck for long sequences.
Key Insights:
- Key cache should be quantized per-channel
- Value cache should be quantized per-token
- Different treatment for keys and values achieves better compression
FP8 Quantization
FP8 offers an alternative to INT8 with higher dynamic range, suitable for quantizing more components including activations.
Advantages:
- Better performance improvements with less degradation for smaller models
- Higher dynamic range compared to INT8
- Supported on modern hardware like H100 GPUs
Model Optimization Beyond Quantization
Pruning Techniques
Structured Pruning:
- Removes entire neurons, layers, or attention heads
- Maintains regular computation patterns
- Easier to implement on standard hardware
Unstructured Pruning:
- Removes individual weights based on magnitude
- Higher compression ratios possible
- Requires specialized hardware for efficiency gains
Knowledge Distillation
Training smaller “student” models to mimic larger “teacher” models.
Process:
- Use large model as teacher to generate soft targets
- Train smaller student model to match teacher outputs
- Combine original task loss with distillation loss
Benefits:
- Significant model size reduction
- Maintains much of the original performance
- Can be combined with quantization
Architectural Optimizations
Attention Optimization:
- Flash Attention: Memory-efficient attention computation
- Sparse Attention: Reduce quadratic complexity
- Multi-Query Attention: Share key/value across heads
Flash Attention uses tiling to reduce the number of memory reads/writes between GPU high bandwidth memory (HBM) and GPU on-chip SRAM, achieving up to 3x speedup on GPT-2.
Practical Implementation Guide
Choosing the Right Quantization Method
For Quick Deployment:
- Start with weight-only quantization
- Use post-training quantization for simplicity
- Target INT8 for good balance of speed and accuracy
For Maximum Efficiency:
- Implement full integer quantization
- Use calibration datasets for better accuracy
- Consider 4-bit quantization for memory-constrained environments
For Production Systems:
- Benchmark multiple approaches
- Use quantization-aware training for critical applications
- Implement mixed-precision strategies
Evaluation and Validation
Accuracy Metrics:
- Compare perplexity on validation sets
- Measure task-specific performance degradation
- Test on diverse benchmarks (GLUE, HellaSwag, etc.)
Efficiency Metrics:
- Memory usage reduction
- Inference latency improvement
- Energy consumption analysis
- Cost savings calculation
Recent comprehensive evaluations show that LLMs with 4-bit quantization can retain performance comparable to their non-quantized counterparts, with quantization achieving up to 99% accuracy recovery.
Tools and Frameworks
PyTorch Quantization
Native support includes the torch.quantization module with dynamic and static quantization capabilities.
import torch.quantization as quant
# Prepare model for quantization
model.qconfig = quant.get_default_qconfig('fbgemm')
model_prepared = quant.prepare(model)
# Calibrate with sample data
model_prepared.eval()
with torch.no_grad():
for data in calibration_data:
model_prepared(data)
# Convert to quantized model
quantized_model = quant.convert(model_prepared)
Hugging Face Optimum
Features integration with popular transformer models and support for various quantization backends.
from optimum.onnxruntime import ORTModelForCausalLM
# Load and quantize model
model = ORTModelForCausalLM.from_pretrained(
"microsoft/DialoGPT-medium",
from_transformers=True,
provider="CPUExecutionProvider"
)
# Apply quantization
quantized_model = model.quantize()
BitsAndBytes
Provides 4-bit and 8-bit quantization with minimal setup required.
from transformers import BitsAndBytesConfig, AutoModelForCausalLM
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b-hf",
quantization_config=quantization_config
)
Real-World Performance Results
Speed Improvements
Quantization can significantly speed up inference times, with AWQ and GPTQ techniques delivering similar performance improvements. Recent benchmarks show:
- 3x faster inference with 4-bit quantization compared to FP16
- Up to 3.4x throughput improvement with mixed 4-bit quantization
- 2x speedup with 4x memory reduction for CNN deployments
Memory Reduction
Quantization achieves substantial memory savings:
- 75% less memory with INT8 quantization from FP32
- 87% reduction with 4-bit quantization
- 2.6x less peak memory usage with KV cache quantization
Accuracy Preservation
Modern quantization techniques maintain high accuracy:
- 99% accuracy recovery with 8-bit quantization
- Minimal performance degradation (< 5%) with proper calibration
- 95.87% accuracy maintained with structured pruning and distillation
Best Practices and Recommendations
Development Workflow
- Baseline Establishment: Measure original model performance thoroughly
- Gradual Optimization: Apply techniques incrementally to understand impact
- Validation Testing: Use diverse datasets for comprehensive evaluation
- Production Monitoring: Continuously monitor quantized model performance
Common Pitfalls to Avoid
- Over-quantization: Pushing precision too low without proper validation
- Ignoring Outliers: Not accounting for activation distribution characteristics
- Insufficient Calibration: Using too little or unrepresentative calibration data
- Hardware Mismatch: Optimizing for wrong target hardware characteristics
Optimization Strategy
Phase 1: Weight-only quantization for quick wins
Phase 2: Full quantization with proper calibration
Phase 3: Advanced techniques (pruning, distillation, architectural changes)
Phase 4: Hardware-specific optimization and deployment
Future Directions
Emerging Techniques
- Adaptive Quantization: Dynamic adjustment of precision based on input complexity
- Neural Architecture Search: Automated optimization of model architectures
- Hardware-Software Co-design: Optimization tailored to specific hardware platforms
Industry Trends
- Standardization: Development of common quantization standards and benchmarks
- Automated Tools: AI-assisted optimization and quantization selection
- Specialized Hardware: Chips designed specifically for quantized model inference
Conclusion
Model quantization and optimization represent critical technologies for making LLMs accessible and practical for real-world deployment. As models continue to grow in size and capability, these techniques become increasingly important for democratizing AI access and reducing computational costs.
The field is rapidly evolving, with new techniques like GPTQ, AWQ, and SmoothQuant showing that significant efficiency gains are possible without substantial accuracy loss. The key is understanding the trade-offs and choosing the right combination of techniques for your specific use case.
Success in model optimization requires careful attention to the entire pipeline — from quantization method selection to hardware considerations to thorough validation. By following best practices and staying current with emerging techniques, developers can deploy efficient LLM solutions that deliver powerful AI capabilities within practical resource constraints.
The future of LLM deployment lies not just in making models larger and more capable, but in making them more efficient and accessible through sophisticated optimization techniques. As these methods mature, we can expect to see powerful AI capabilities available in an increasingly wide range of applications and deployment scenarios.
Ready to optimize your LLM deployment? Start with simple weight quantization, measure the impact carefully, and gradually explore more advanced techniques as your requirements and expertise grow.
Model Quantization and Optimization: Making LLMs Efficient and Accessible was originally published in Google Cloud - Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
13 Jul 2025, 3:31 am
Elevate Your Cloud Networking: Announcing v3.0.0 of Cloud Networking Config Solutions
We’re thrilled to announce the release of v3.0.0 of the Cloud Networking Config Solutions on GitHub, packed with new features and enhancements designed to supercharge your cloud infrastructure. This release focuses on expanding connectivity options, bolstering security, and improving traffic management for your Google Cloud deployments.
You can find the full release notes for v3.0.0 in our GitHub repository: v3.0.0 Release Notes
What’s New in v3.0.0?
This release introduces support for several key services, providing you with more robust and flexible networking capabilities:
Networking Constructs :
- Network Connectivity Center (NCC) NCC continues to be a cornerstone for hybrid and multi-cloud connectivity. In v3.0.0, we’ve expanded its capabilities to provide even more versatile solutions:
- Producer VPC Support: Integrate Producer VPC networks with NCC, enabling seamless connectivity and resource sharing across different service producers and consumers. For more details, refer to the Producer VPC documentation.
- Hybrid Spoke Enhancements: Boost your hybrid connectivity with enhanced support for:
- HA VPN as a hybrid spoke: Achieve highly available and resilient VPN connections between your on-premises network and Google Cloud. For more details, refer to the Hybrid Spoke HA VPN documentation.
- Cloud Interconnect as a hybrid spoke: Leverage dedicated and highly performant connections with Cloud Interconnect through NCC. Explore the specifics in the Hybrid Spoke Interconnect documentation.
2. Load Balancers We’ve extended our support for advanced load balancing configurations, ensuring your applications are highly available and performant:
- Network Passthrough Load Balancers: Seamlessly distribute internal & external traffic , enhancing the resilience and scalability of your services. For more details refer to user journey guide for load balancers.
- Google-Managed SSL: Simplify your SSL certificate management with built-in support for Google-managed SSL certificates, ensuring secure communication without the operational overhead.
Security
3. Next-Generation Firewall (NGFW) Security is paramount, and this release brings significant advancements to your network defense:
- Network Firewall Policy: Implement granular and centralized firewall policies to secure your network traffic more effectively across your Google Cloud projects.
- Enterprise — Firewall Endpoints for Centralized Traffic Inspection: Gain greater control and visibility over your network by directing traffic through centralized inspection points, crucial for meeting compliance and security requirements. For more details, refer to user journey guide.
Consumers
4. UMIG as a Consumer: Utilize Unmanaged Instance Groups (UMIGs) as consumers within your NCC setup and also as a backends to your Load balancers, offering greater flexibility for your application deployments.
Platform Stability and User Experience
Beyond the new features, v3.0.0 also includes important updates to platform stability and user experience, such as enhanced test connectivity tools and general improvements for Managed Instance Groups (MIGs). We’re committed to making your experience with Cloud Networking Config Solutions as smooth and efficient as possible.
We’re excited for you to explore these new capabilities and see how they can further empower your cloud networking strategies. Head over to our GitHub repository to get started!
Elevate Your Cloud Networking: Announcing v3.0.0 of Cloud Networking Config Solutions was originally published in Google Cloud - Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
13 Jul 2025, 3:31 am
Next-Level Data Automation: Gemini CLI, Google Sheets, and MCP
Abstract
This article explores the integration of the Gemini Command-Line Interface (CLI) with Google Sheets using the Model Context Protocol (MCP). It demonstrates how to leverage the open-source projects MCPApp and ToolsForMCPServer to create a bridge between the Gemini CLI and Google Workspace. This enables users to perform powerful data automation tasks, such as creating, reading, and modifying tables in Google Sheets directly from the command line, using natural language prompts. The article provides practical examples and sample prompts to illustrate the seamless workflow and potential for building sophisticated, AI-powered applications within the Google Cloud ecosystem.
Introduction
In a recent article, “Gemini CLI Tutorial Series — Part 4: Built-in Tools,” Romin Irani explores the powerful capabilities of the Gemini Command-Line Interface (CLI), an open-source tool that brings Google’s Gemini models directly to your terminal. Ref These built-in tools allow the CLI to interact with the local file system and the internet, enabling it to perform tasks such as reading folders, creating files, and performing Google searches. One particularly impressive demonstration in the article is how Gemini CLI can process a collection of image-based invoices and extract key information into a structured table, showcasing its powerful data extraction capabilities.
The potential of Gemini CLI can be further extended by using the Model Context Protocol (MCP), a standard that allows AI applications to securely connect with external systems and data sources. This is where the MCP server, built using Google Apps Script Web Apps, comes into play. It acts as a middleware, creating a bridge between the Gemini CLI and Google Workspace services like Google Sheets, Google Docs, and Gmail.
To achieve this synchronization, two key open-source projects, MCPApp and ToolsForMCPServer, can be utilized. Ref and Ref MCPApp is a library that simplifies the creation of an MCP server using Google Apps Script, while ToolsForMCPServer provides a suite of pre-built tools for interacting with various Google Workspace services. By leveraging these tools, you can create a powerful, self-contained network that operates exclusively within the Google Cloud ecosystem, which simplifies credential management.
The synchronization of a table between the Gemini CLI and Google Sheets opens up a world of automated workflows. For example, you could extract data from local files or websites and have it automatically populate a Google Sheet, or you could use natural language commands in your terminal to manipulate and analyze data stored in a Sheet. This integration of the command line with the collaborative features of Google Sheets creates a seamless and powerful environment for developers and data analysts alike, enabling them to build sophisticated, AI-powered applications that are deeply integrated with their personal or organizational Google data.
Usage and Sample Prompts
You can see how to use this at my repository https://github.com/tanaikech/ToolsForMCPServer?tab=readme-ov-file#usage
This section introduces sample prompts and answers using the Gemini CLI and the MCP server built with Google Apps Script Web Apps.
Create a table in Gemini CLI and copy the table to Google Sheets
The actual flow can be seen in the following image.
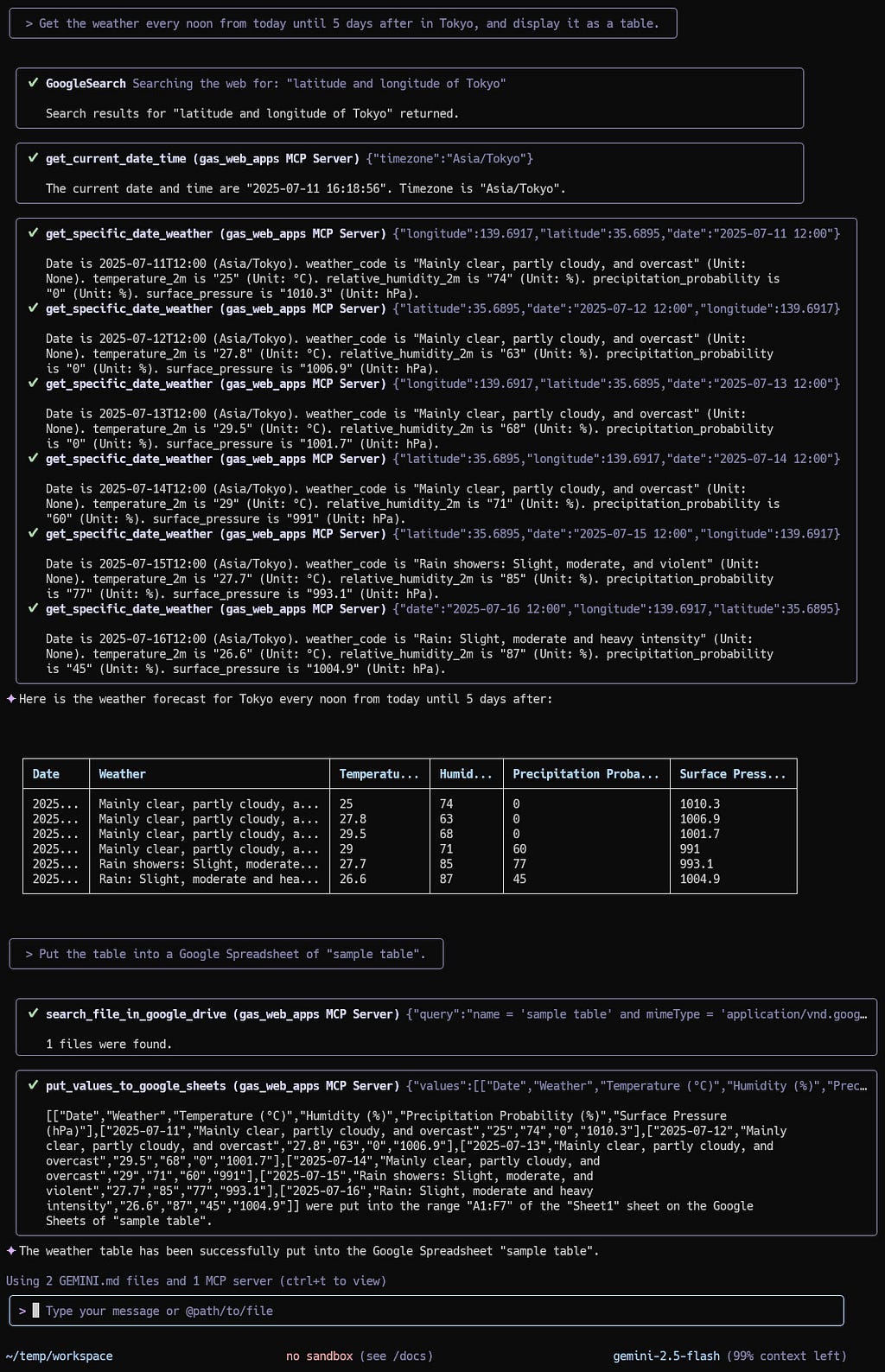
Prompt 1
Get the weather every noon from today until 5 days after in Tokyo, and display it as a table.
By “Prompt 1”, the data is retrieved using GoogleSearch, get_current_date_time, and get_specific_date_weather. And, show the data as a table on Gemini CLI.
Prompt 2
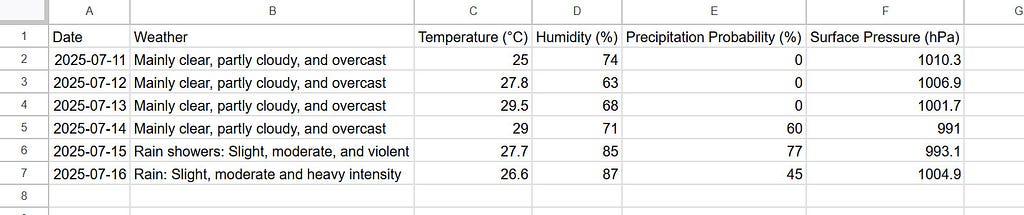
Put the table into a Google Spreadsheet of "sample table".
By “Prompt 2”, the showing table is put into Google Sheets using search_file_in_google_drive and put_values_to_google_sheets. By this, the table was correctly put into the spreadsheet “sample table” as follows.
Read a table from Google Sheets to Gemini CLI
The actual flow can be seen in the following image.
Prompt 1
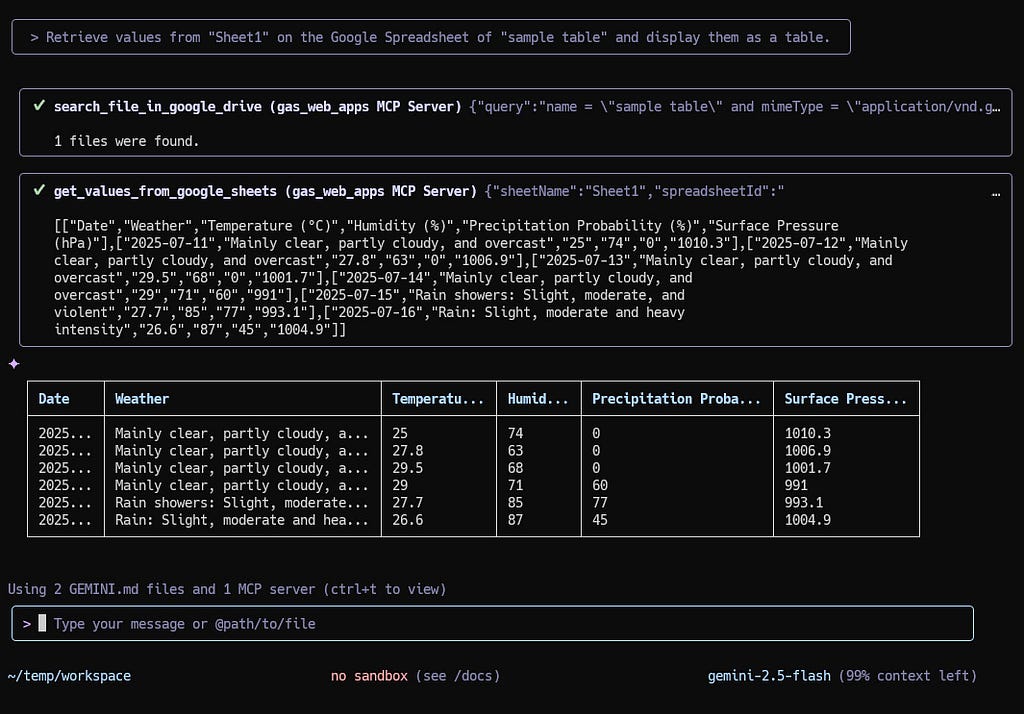
Retrieve values from "Sheet1" on the Google Spreadsheet of "sample table" and display them as a table.
By “Prompt 1”, the table values are retrieved from Google Sheets using search_file_in_google_drive and get_values_to_google_sheets. And, show the data as a table on Gemini CLI.
Modify a table on Gemini CLI and synchronize it to Google Sheets
The actual flow can be seen in the following image.
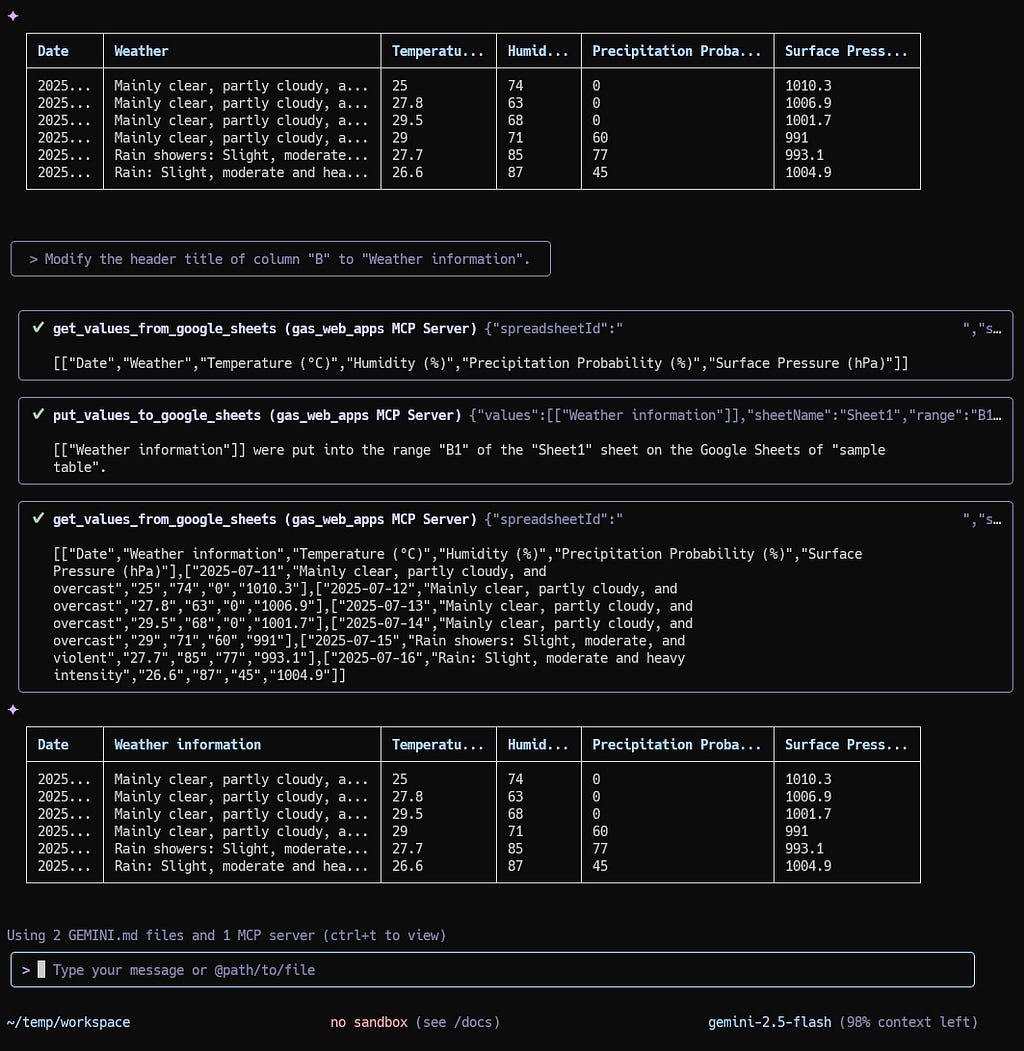
Here, I tried to modify the header title of column “B” as follows.
Prompt 1
Modify the header title of column "B" to "Weather information".
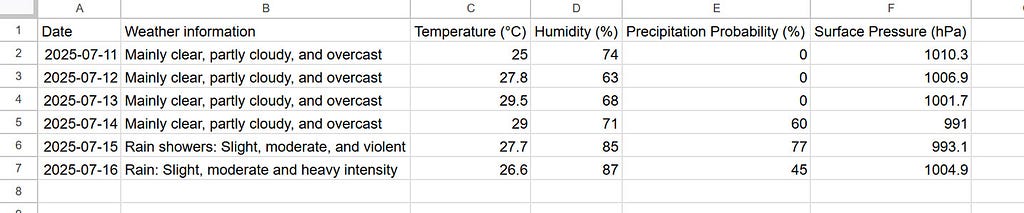
It is found that when the above prompt is run, the Gemini CLI automatically changes the table values and shows the table on the terminal, and also updates the Google Spreadsheet, simultaneously. And, the header title of the column “B” was changed successfully on Google Spreadsheet as follows.
Note
The management of Google Sheets, Google Docs, Google Slides, and so on can be advanced by updating the scripts of the tools at the MCP server. By this, more complicated operations between Gemini CLI and the MCP server will be able to be achieved.
Summary
- Seamless Integration: The Gemini CLI can be integrated with Google Sheets and other Google Workspace services through the Model Context Protocol (MCP).
- Open-Source Tools: The MCPApp and ToolsForMCPServer open-source projects provide the necessary tools and libraries to build an MCP server with Google Apps Script.
- Natural Language Commands: Users can interact with Google Sheets using natural language prompts in the command line, simplifying data manipulation tasks.
- Automated Workflows: This integration enables powerful automated workflows, such as extracting data from local files or websites and populating it into a Google Sheet.
- Enhanced Data Management: The ability to create, read, and modify tables in Google Sheets from the Gemini CLI provides a flexible and powerful environment for developers and data analysts.
Next-Level Data Automation: Gemini CLI, Google Sheets, and MCP was originally published in Google Cloud - Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
13 Jul 2025, 3:30 am
New era in Med with GenAI — Google MedGemma Revolution
New era in Med with GenAI — Google MedGemma Revolution
Google released MedGemma a open medical vision-language model for Healthcare! Built on Google DeepMind Gemma 3 it advances medical understanding across images and text, significantly outperforming generalist models of similar size. MedGemma is one of the best open model under 50B!
🩺 New models in the MedGemma collection, our multimodal open models specifically designed for health AI development that can run on a single GPU → https://goo.gle/409ThIV

Full details of MedGemma and MedSigLIP development and evaluation can be found in the MedGemma technical report.
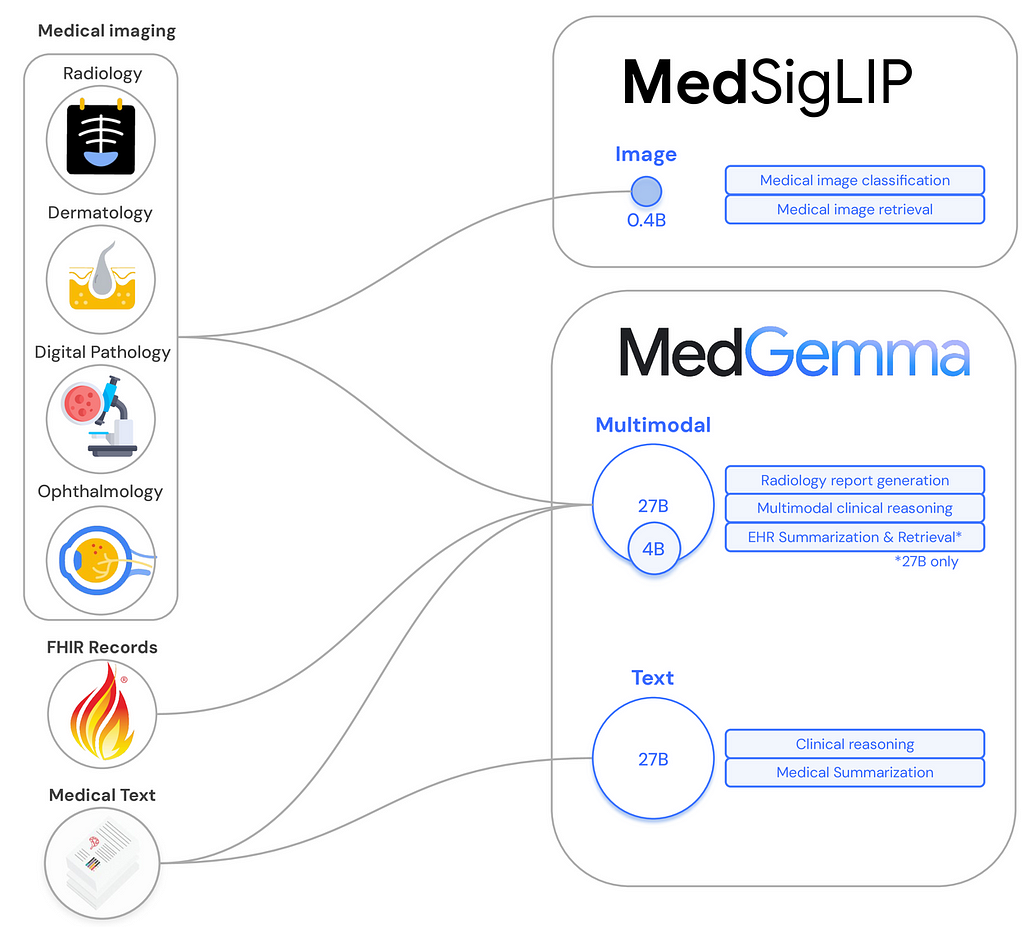
MedGemma: A multimodal generative model for health
The MedGemma collection includes variants in 4B and 27B sizes, both of which now accept image and text inputs and produce text outputs.
- MedGemma 4B Multimodal: MedGemma 4B scores 64.4% on MedQA, which ranks it among the best very small (<8B) open models. In an unblinded study, 81% of MedGemma 4B–generated chest X-ray reports were judged by a US board certified radiologist to be of sufficient accuracy to result in similar patient management compared to the original radiologist reports. It additionally achieves performance on medical image classification tasks that is competitive with task-specific state-of-the-art models.
- MedGemma 27B Text and MedGemma 27B Multimodal: Based on internal and published evaluations, the MedGemma 27B models are among the best performing small open models (<50B) on the MedQA medical knowledge and reasoning benchmark; the text variant scores 87.7%, which is within 3 points of DeepSeek R1, a leading open model, but at approximately one tenth the inference cost. The MedGemma 27B models are competitive with larger models across a variety of benchmarks, including retrieval and interpretation of electronic health record data.
This expansion introduces:
1️⃣ MedGemma 27B Multimodal: Designed for complex multimodal and longitudinal Electronic Health Record (EHR) interpretation, offering top performance on medical knowledge benchmarks.
2️⃣ MedSigLIP: A lightweight image and text encoder ideal for medical image classification, search, and retrieval tasks.
These open models provide flexibility and privacy, allowing you to run them on local hardware. Developers also gain full control over fine-tuning and benefit from the stability and reproducibility crucial for medical applications.
Dive into the technical details and get started with notebooks → https://goo.gle/4lOgkRV
MedGemma Was Trained:
1️⃣ Fine-tuned Gemma 3 vision-encoder (SigLIP) on over 33 million medical image-text pairs (radiology, dermatology, pathology, etc.) to create the specialized MedSigLIP, including some general data to prevent catastrophic forgetting.
2️⃣ Further pre-trained Gemma 3 Base by mixing in the medical image data (using the new MedSigLIP encoder) to ensure the text and vision components could work together effectively.
3️⃣ Distilling knowledge from a larger “teacher” model, using a mix of general and medical text-based question-answering datasets.
4️⃣ Reinforcement Learning similar to Gemma 3 on medical imaging and text data, RL led to better generalization than standard supervised fine-tuning for these multimodal tasks.
Insights:
- 💡 Outperforms Gemma 3 on medical tasks by 15–18% improvements in chest X-ray classification.
- 🏆 Competes with, and sometimes surpasses, much larger models like GPT-4o.
- 🥇 Sets a new state-of-the-art for MIMIC-CXR report generation.
- 🩺 Reduces errors in EHR information retrieval by 50% after fine-tuning.
- 🧠 The 27B model outperforms human physicians in a simulated agent task.
- 🤗 Openly released to accelerate development in healthcare AI.
- 🔬 Reinforcement Learning was found to be better for multimodal generalization.
The power of open models
Because the MedGemma collection is open, the models can be downloaded, built upon, and fine-tuned to support developers’ specific needs. Particularly in the medical space, this open approach offers several distinct advantages over API-based models:
- Flexibility and privacy: Models can be run on proprietary hardware in the developer’s preferred environment, including on Google Cloud Platform or locally, which can address privacy concerns or institutional policies.
- Customization for high performance: Models can be fine-tuned and modified to achieve optimal performance on target tasks and datasets.
- Reproducibility and stability: Because the models are distributed as snapshots, their parameters are frozen and unlike an API, will not change unexpectedly over time. This stability is particularly crucial for medical applications where consistency and reproducibility are paramount.
- Google’s MedGemma AI model shows a significant capacity for understanding complex topics in women’s health, including the uterus and menstrual cycle. The model’s training on “medical text” and “radiology images” would include a wide array of content relevant to gynecology, to clinical case notes and radiological images such as ultrasounds. This diverse dataset provides MedGemma with a robust foundation to understand the complexities of the uterus, the hormonal fluctuations of the menstrual cycle, and various associated conditions.
Trained on vast medical datasets that encompass gynecology, it can process and interpret intricate information. A key feature is its ability to provide tailored suggestions based on the specific details of each case presented to it. it serves as a powerful foundational tool for developers creating specialized healthcare applications. This capability opens new avenues for personalized support in gynecological research and patient information systems.
Refer to the following table to understand which model from the MedGemma family is ideal for your use case.

MedGemma provides multiple ways to get started, whether you’re looking to:
🔹 Run models locally
🔹 Deploy scalable endpoints via Vertex AI
🔹 Fine-tune on domain-specific data
🔹 Launch batch prediction jobs for large datasets
The possibilities for applying this to medical imaging, diagnostics, or healthcare automation are incredible, and it’s great to see such advanced tools being made openly available.
If you’re working in healthcare AI, computer vision, or data science, I’d love to hear how you’re exploring or planning to use models like this.
Let’s connect, share ideas, and build something meaningful.
🔗 More info here: https://lnkd.in/dt8tJyP5
🔗 Hugging Face: https://lnkd.in/db2SwSi5
Read the full announcement: https://lnkd.in/dTRJpgng
MedGemma technical report: https://lnkd.in/diBR3QTd
Explore Health AI Developer Foundations: goo.gle/hai-def
Access detailed notebooks on GitHub for inference & fine-tuning;
MedGemma: https://lnkd.in/dFFeMK3g
MedSigLIP: https://lnkd.in/dPpU6kCQ
Some of Resources here from Google Documentations and Blogs.
New era in Med with GenAI — Google MedGemma Revolution was originally published in Google Cloud - Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
13 Jul 2025, 3:30 am
Fresh from the GCP DBverse 12/07/25: Cloud SQL Failover Just Got Invisible, Stop Rewriting Your App!
The latest GCP database updates and what they mean for your production systems, dev workflows, and architecture
Fresh from the GCP Dataverse[Jul 12th 25] Cloud SQL Failovers Just Got Invisible: Stop Rewriting Your App!

In the mid-1950s, booking a flight with American Airlines was a monumental exercise in patience. A team of eight operators huddled around a massive, rotating file of index cards, one for every flight. When a seat was sold, someone would physically make a mark on the card; the whole process could take up to three hours and was riddled with errors that led to under-booked or over-sold flights. This complex, error-prone manual system was the catalyst for the first-ever automated, centralized airline reservation system: SABRE, a joint project with IBM that forever changed not just travel, but the very concept of real-time, distributed systems. It’s a powerful reminder that the most impactful innovations are often born from the drive to abstract away gnarly, real-world complexity and make systems more resilient and productive. 🚀
Looking at what folks are building and writing about this week, it feels like we’ve hit a real inflection point. We’re moving past the “what is it” phase of GenAI and squarely into the “how do I build with it” phase. I saw this fantastic, no-nonsense guide on building a complete customer service agent using Vertex AI Search and Conversation, which is one of those perfect blueprints for a real-world problem. It pairs really well with another piece I saw on the fundamentals of building a RAG pipeline from the ground up with Gemini — it’s all about getting your hands dirty and understanding the mechanics instead of just calling a magic API. It’s just cool to see the community sharing these practical playbooks for things that businesses are actually asking for. There’s a lot of other great stuff on performance and security in the full list, definitely worth a scan.
But the really big story this week is all about making database failovers way less painful, basically moving the problem from the app layer into the infrastructure where it belongs. 🔧 You know how when a primary Cloud SQL instance fails over, your application connection strings break because the IP changes? It’s a huge headache. Well, the team just made the write endpoint feature generally available for MySQL and Postgres Enterprise Plus instances. It’s essentially a stable, global DNS name that always points to the current primary, so your app just connects to that one endpoint and doesn’t even know a failover happened. It makes your whole setup way more resilient without you having to write a bunch of complex reconnection logic.
They’ve also added Active Directory support for these write endpoints. This is a big deal because for any real enterprise using SQL Server, just pointing to a new IP isn’t enough; the AD authentication has to work seamlessly, even across different forests. It shows we’re thinking about the gnarly, real-world enterprise problems, not just the simple redirect.💡
And the Bigtable team also added a nice safety feature: when you undelete a table, it now automatically gets deletion protection enabled, which is a smart way to prevent you from accidentally deleting something you just went to the trouble of recovering. 📈
Upcoming Events & Learning Opportunities
- Unlocking Your Knowledge: Architecting for RAG, Application & Agent Access (15 July 2025)
In this session, you’ll get all of the newest insights to help you transform your business.
Register to Unlocking Your Knowledge: Architecting for RAG, Application & Agent Access - Build Smart Apps with Ease: GenAI, Cloud SQL, and Observability for Faster Development (15 July 2025)
Master the essentials of building powerful gen AI applications. We’ll explore the complete Gen AI application development lifecycle and demonstrate the new Application Design Center (ADC) for rapid app idea-to-deployment, alongside rich ecosystem integrations with frameworks like LangChain, LlamaIndex, and LangGraph, and the new MCP Toolbox for Databases for enhanced manageability and security of Gen AI agents. We’ll also cover critical operational considerations, showcasing Cloud SQL Enterprise Plus features for performance, sub-second scalability, high availability, and disaster recovery.
Register to Build Smart Apps with Ease: GenAI, Cloud SQL, and Observability for Faster Development - TechByte: The intelligent enterprise: Reshaping business with modern applications and generative AI (22 July 2025)
Transform Your Business with AI: Google Cloud & Oracle Webinar.This session is ideal for business and IT leaders interested in leveraging generative AI and cloud technology to modernize applications, infrastructure, and security for enterprise transformation.
Register to TechByte: The intelligent enterprise: Reshaping business with modern applications and generative AI - Powering Agents with Vertex Vector Search 2.0 (29 July 2025)
AI Agents, RAG systems, and advanced search thrive on data. Vertex Vector Search provides the foundation, and Vector Search 2.0 is making these solutions more powerful and accessible. Developers can easily onboard with an intuitive SDK, leverage a serverless architecture, and query indexes in minutes with only a few lines of code. Vector Search 2.0 also integrates smoothly with popular frameworks like Langchain, fitting naturally into your existing MLOps.This session covers how to use Vector Search 2.0 to build AI agents, RAG solutions, and enterprise search solutions.
Register to Powering Agents with Vertex Vector Search 2.0
Fresh Off the Press: Google Cloud News
- SQL reimagined: How pipe syntax is powering real-world use cases Cloud Blog
- Faceted Filtering Meets Vector Search: Building a Dynamic Hybrid Retail Experience with AlloyDB &… Medium
- AI Expense Tracker using Gemini 2.5 Flash, Google ADK, and Firestore Medium
- Query your database using natural language using the MCP Toolbox from GCP Medium
- From news to insights: Glance leverages Google Cloud to build a Gemini-powered Content Knowledge Graph (CKG) Cloud Blog
- Announcing Vertex AI Agent Engine Memory Bank available for everyone in preview Cloud Blog
- Building AI Fashion House: A Multi-Agent System Medium
- Advanced RAG — Hypothetical Question Embedding Medium
- From Open Model to Agent: Deploying Qwen3 ADK agent on Vertex AI Agent Engine Medium
- Adding an AI Agent to your Discord Server with Agent Development Kit Medium
Latest Release Notes
Bigtable
NON_BREAKING_CHANGE
- When you undelete a table, Bigtable automatically enables deletion protection for that table.
Cloud SQL for MySQL
FEATURE
- The write endpoint feature for Cloud SQL Enterprise Plus edition instances is now generally available (GA). This endpoint is a global domain name service (DNS) name and resolves to the IP address of the current primary Cloud SQL instance that’s enabled with private services access.By using a write endpoint, you can avoid having to make application connection changes after performing a switchover or replica failover operation to test or mitigate a region failure.For more information, see Connect to an instance using a write endpoint.
Cloud SQL for PostgreSQL
FEATURE
- The write endpoint feature for Cloud SQL Enterprise Plus edition instances is now generally available (GA). This endpoint is a global domain name service (DNS) name and resolves to the IP address of the current primary Cloud SQL instance that’s enabled with private services access.By using a write endpoint, you can avoid having to make application connection changes after performing a switchover or replica failover operation to test or mitigate a region failure.For more information, see Connect to an instance using a write endpoint.
Cloud SQL for SQL Server
FEATURE
- Cloud SQL for SQL Server now offers Active Directory support for write endpoints. For more information, see Write endpoints across forests.
That’s a wrap for this week. We’re always interested to hear how these updates apply to real-world projects.
The comments section is open if you have questions or want to share your perspective on the new features released this week.
For more specific or private inquiries, you can reach our team directly at db-eng-uk@google.com.
If you found this post useful, we encourage you to share it in your network. For broader, ongoing conversations, the official Google Cloud Community is an excellent resource.
Stay tuned for next week’s digest!
This digest was brought to you by Andrew Feldman and the Google Cloud Database UK Team.
Fresh from the GCP DBverse 12/07/25: Cloud SQL Failover Just Got Invisible, Stop Rewriting Your App! was originally published in Google Cloud - Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
13 Jul 2025, 3:30 am
Bridging the Divide: Unifying Platform and ML Engineering on Google Cloud for Next-Gen AI

I. Introduction: The Dual Mandate of AI Infrastructure
Generative AI is revolutionizing industries, but it’s also creating a significant challenge for the teams building the infrastructure to support it.[1] This new wave of AI requires a careful balancing act between the rapid innovation demanded by Machine Learning (ML) Engineers and the stability and control prioritized by Platform Engineers.
On one side, Platform Engineers are the guardians of infrastructure, focusing on reliability, security, and performance.[2] They build and manage the foundational systems, ensuring everything runs smoothly and efficiently. On the other side, ML Engineers are the innovators, driven to accelerate model development and experimentation to create cutting-edge Generative AI products.[3]
This clash of priorities can lead to friction, with ML Engineers feeling stifled by infrastructure constraints and Platform teams viewing rapid changes as a threat to stability.[4] The key to success lies in bridging this gap. An effective cloud strategy must provide both the robust control needed by platform teams and the agile, streamlined workflows required by ML engineers. This synergy is crucial for fostering a collaborative and efficient AI development lifecycle.II. Empowering the Platform Team: Control, Reliability, and Automation
Platform teams, as infrastructure custodians, are responsible for its stability, security, and performance. Google Cloud offers services empowering these teams with control and automation for robust AI infrastructure.
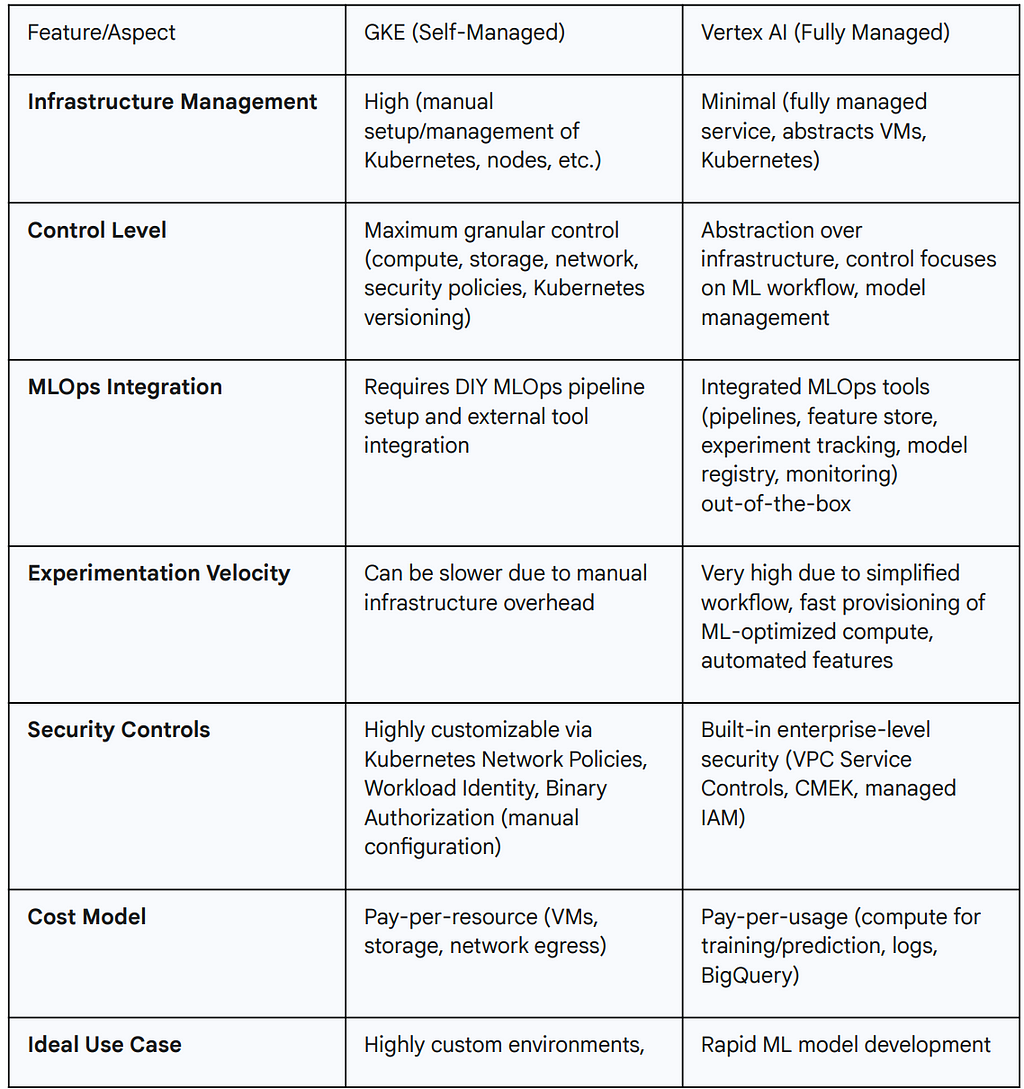
GKE: The Foundation for Customizable Control
Google Kubernetes Engine (GKE) is a managed Kubernetes service providing platform teams with deep, customizable control over AI infrastructure, including compute, storage, network, and security management.
For enterprise AI workloads, GKE Enterprise extends GKE into a powerful AI backbone, addressing complex security, governance, and operational requirements. This suite provides guardrails for platform engineers to confidently offer Kubernetes-based infrastructure to ML teams, ensuring adherence to enterprise security standards and operational best practices, while maintaining flexibility for innovation.
Key control and security features within GKE Enterprise include:
- Workload Identity Federation: Enables least privilege by granting granular IAM permissions to Kubernetes service accounts, ensuring AI workloads access only necessary Google Cloud resources and reducing attack surface.
- Fleet-wide Identity Pool: For multi-cluster organizations, fleets allow consistent IAM bindings across all clusters, simplifying governance and access control at scale.
- Binary Authorization: Ensures only trusted container images run on clusters, blocking unauthorized deployments and enforcing security throughout the software supply chain.
- Cloud Armor (WAF): Filters incoming Layer 7 network traffic to protect AI workloads, offering various rule types and integrating with the GKE Gateway Controller.
- Identity Aware Proxy (IAP): Provides an additional security layer for AI applications via load balancers, securely authenticating and authorizing users without a VPN.
- Kubernetes Network Policies: Offers Kubernetes-native traffic control, defining granular ingress and egress rules for pods to ensure secure communication and workload isolation.
GKE’s native Kubernetes support also enables platform teams to build robust automation and CI/CD pipelines using tools like GitHub Actions, Argo Workflows, and Jenkins, ensuring reliable and performant AI application deployment and maintenance.
Vertex AI: The Fully Managed Platform Advantage
Vertex AI offers a fully managed service for the entire ML lifecycle, significantly reducing operational burden on platform teams. This frees them from provisioning and managing physical infrastructure, allowing focus on MLOps pipelines, advanced security, and overall AI platform strategy.
This shift enables a more efficient division of labor: platform teams become strategic enablers, building robust, secure, and cost-optimized managed environments, while ML teams become agile innovators, leveraging these environments without infrastructure complexities. This fosters collaboration and accelerates the AI development lifecycle.
Vertex AI provides a unified workbench and comprehensive MLOps environment, including tools for end-to-end ML workflows, feature engineering, experiment tracking, model management, and quality monitoring. This aligns with platform goals of operationalizing ML at scale and ensuring model reliability.
Built-in security features like VPC peering, VPC Service Controls, customer-managed encryption keys (CMEK), and fine-grained Identity and Access Management (IAM) are critical for platform teams, ensuring data protection and access control with minimal manual configuration.
Vertex AI training jobs are optimized for ML. It also supports distributed training with features like Reduction Server and automated hyperparameter optimization. Vertex AI Pipelines often run on GKE clusters , and Vertex AI itself leverages AI Hypercompute , assuring platform teams that workloads run on Google Cloud’s optimized and secure foundation.
Table 1: GKE vs. Vertex AI for AI Workloads (Platform vs. ML Engineer Perspective)

Infrastructure as Code (IaC) and Curated Cluster Management
IaC is paramount for platform teams to achieve reliability, consistency, and scalability. Google Cloud offers specialized tools combining IaC with high-performance AI infrastructure.
AI Hypercompute (Cluster Director): Powering High-Performance AI
AI Hypercompute, with Cluster Director, is Google Cloud’s specialized infrastructure for deploying and managing accelerators (TPUs, GPUs) as a single, high-performance unit. This is critical for large-scale Generative AI training and inference.
Key features of AI Hypercompute for AI workloads include:
- Dense Colocation of Accelerator Resources: Physically close host machines, provisioned as resource blocks, interconnected with a dynamic ML network fabric, minimizing network hops and optimizing for low latency in distributed training.
- Topology-Aware Scheduling: Provides detailed topology information for efficient job placement and maximized accelerator utilization.
- Advanced Maintenance Scheduling and Controls: Full control over VM maintenance within resource blocks, including synchronized upgrades and alerts for scheduled events, improving “goodput”.
- Enhanced Networking & Rapid Storage: 400G Cloud Interconnect offers 4x more bandwidth. Rapid Storage solutions like Cloud Storage zonal buckets and Anywhere Cache provide up to 20x faster random-read data loading and 70% latency reduction, directly impacting training/inference speed.
- 360° Observability & Job Continuity: Comprehensive monitoring dashboards, AI Health Predictor, Straggler Detection, and multi-tier checkpointing ensure uninterrupted training.
- Open Software Capabilities: Co-designed software supports popular ML frameworks (PyTorch, JAX, vLLM, Keras), facilitating faster delivery and cost-efficient resource utilization.
AI Hypercompute underpins nearly every AI workload on Google Cloud, including Vertex AI. It’s accessible via Compute Engine APIs or natively integrated with GKE, offering flexible deployment.
Cluster Toolkit: Open-Source IaC for AI/ML Clusters
The Google Cloud Cluster Toolkit, an open-source software, simplifies deploying HPC, AI, and ML workloads on Google Cloud, enabling fast creation of turnkey clusters adhering to best practices.
At its core, Cluster Toolkit leverages IaC principles. It uses a cluster blueprint (YAML) to declaratively define configurations. These blueprints utilize modules (Terraform or Packer files) to define infrastructure as code. The gcluster engine combines modules based on the blueprint to produce a deployment folder, which can be customized before deployment.
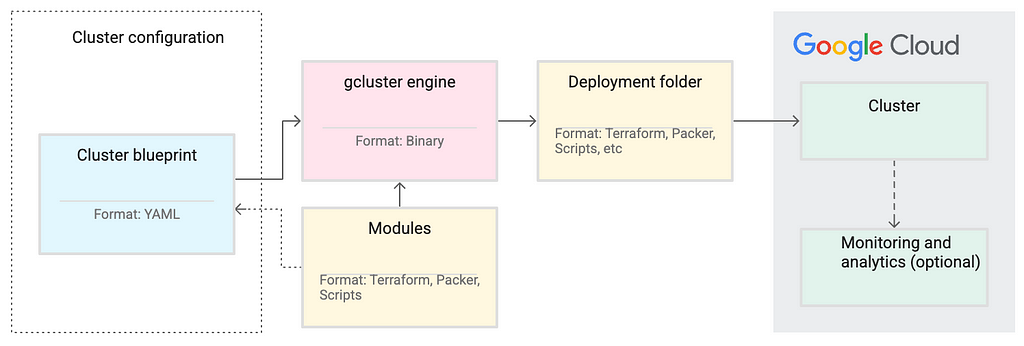
While effective for creation and deletion, modifying active clusters typically involves deleting, updating the blueprint, creating a new deployment folder, and redeploying. This ensures a controlled, IaC-driven change management process. As an open-source solution, it’s highly configurable and extensible, supporting various use cases and integrating with Slurm. It also integrates with Cloud Monitoring for performance visibility.
The synergy of specialized hardware (AI Hypercompute) and robust IaC (Cluster Toolkit) automates and optimizes AI infrastructure provisioning. This benefits both platform and ML teams: platform teams achieve control, reliability, and automation, while ML engineers gain faster, on-demand access to optimally configured compute resources, accelerating development and iteration.
III. Accelerating ML Innovation: Velocity, Experimentation, and Iteration
ML engineers need to rapidly develop models, iterate quickly, and accelerate time-to-market for Generative AI products. Google Cloud can be integrated with specialized tools addressing these needs, allowing ML engineers to focus on core competencies.
Ray on GKE and Vertex AI: Scalable AI and Python Applications
Ray is an open-source framework for scaling AI and Python applications, providing infrastructure for distributed computing and parallel processing in ML workflows. ML engineers can use existing open-source Ray code on Vertex AI with minimal changes, leveraging Vertex AI’s integrations with Google Cloud services like Vertex AI Inference and BigQuery.
Ray’s key benefit is scaling the same Python code seamlessly from a laptop to a large distributed cluster, reducing re-engineering efforts. Ray’s integrated AI libraries (Ray Train, Ray Data, Ray Serve) offer a unified API, allowing easy swapping between ML frameworks (PyTorch, JAX, Hugging Face, XGBoost) on a consistent runtime (Ray, often orchestrated by KubeRay).
Ray’s open-source nature allows direct deployment on GKE, offering a powerful, scalable foundation for ML workloads. Platform engineers provision GKE clusters with high-performance accelerators like NVIDIA H100 and A3 Ultra (H200 GPUs). ML engineers use Ray’s APIs to request generic or specific Ray-supported accelerator types (e.g., NVIDIA_H100, NVIDIA_H200), abstracting Kubernetes manifests, GPU drivers, and network configurations. Platform teams can enable advanced networking like GPUDirect-TCPX on GKE for A3 VMs, which Ray workloads automatically leverage for enhanced GPU communication and data transfer, without ML engineer configuration. This ensures ML engineers achieve high experimentation velocity while platform teams maintain control over optimized infrastructure.
ML engineers connect to Ray clusters on Vertex AI via Ray Client for interactive development (e.g., Colab Enterprise notebooks) or submit Python scripts as batch jobs using the Ray Jobs API. Vertex AI manages Ray clusters, ensuring capacity and lifecycle, freeing ML engineers from operational overhead. Long-running Ray clusters benefit iterative development through data and image caching, reducing startup times for short-lived jobs.
While remote Ray environments use containers for consistency , the ML engineer’s local development is simplified. They write and test Python code locally, then connect to the remote Ray cluster. The burden of local Dockerfile creation, image building, and registry management is abstracted or handled by the Vertex AI platform, accelerating development cycles.
SkyPilot: Unified Abstraction for Any Infrastructure
SkyPilot is an open-source framework providing a unified abstraction layer for running AI and batch workloads across diverse compute resources. It simplifies ML workflows by abstracting underlying infrastructure complexities across cloud providers or on-premises setups.
ML engineers define resource requirements (GPU types, TPUs, CPUs) in a simple YAML file or via CLI. SkyPilot intelligently identifies optimal infrastructure, provisions resources, runs the job, and manages its lifecycle, including reliable provisioning with automated retries and repeatable deployments. It can also be run in common ML development environments such as Colab, Notebook, Workbench etc.
SkyPilot includes features for cost reduction and GPU availability, such as Autostop for idle resource cleanup, robust Spot instance support (3-6x cost savings with auto-recovery), and Intelligent scheduling for selecting the cheapest and most available infrastructure. It also facilitates reproducible data analysis environments, where ML engineers specify resources, data sources (e.g., Google Cloud Storage mounted via GCSFuse), software setup, and run commands in a single YAML file.
For high-performance GPU workloads on Google Cloud, SkyPilot enables GPUDirect-TCPX on A3 VMs (H100) and RDMA on A3Ultra/A4 (H200, B200 GPUs) via a single YAML parameter. This technology allows direct GPU-to-network interface communication, bypassing CPU bottlenecks and significantly enhancing large data transfers. SkyPilot abstracts the complex provisioning of network infrastructure, VM configuration, and GPUDirect-TCPX setup from ML engineers.
SkyPilot abstracts infrastructure: ML engineers define their environment and job as code (YAML) and interact via CLI. SkyPilot handles remote provisioning, environment setup, and workload execution. This frees ML engineers from manual local containerization for development iterations, as the remote execution environment is managed and consistent.
XPK (Accelerated Processing Kit): GKE Orchestration for ML
XPK (Accelerated Processing Kit) is a CLI tool simplifying training job orchestration on accelerators (TPUs, GPUs) within GKE. It’s recommended for quick cluster creation for proofs of concept and testing.
XPK decouples capacity provisioning from job execution. Platform teams provision GKE clusters with reserved ML hardware once. ML engineers then submit training jobs as “workloads” to this shared pool, without re-provisioning for each job, reducing setup overhead. XPK achieves minimal job start times by leveraging Docker containers with pre-installed dependencies and cross-ahead-of-time compilation. Hardware returns to a shared pool upon job completion, maximizing utilization and enabling faster subsequent jobs.
XPK generates preconfigured, training-optimized GKE clusters and allows easy workload scheduling without deep Kubernetes expertise, abstracting Kubernetes manifests and kubectl commands. It supports various TPU (v4, v5e, v5p, Trillium) and GPU (A100, A3-Highgpu, A3-Mega, A3-Ultra, A4) types, and standard CPUs. It integrates with Google Cloud Storage solutions (Cloud Storage FUSE, Filestore, Parallelstore, Block storage) for flexible data access. XPK supports private GKE clusters for enhanced security and integrates with Vertex AI Tensorboard and Experiments for monitoring and tracking training runs.
XPK abstracts the Kubernetes layer, allowing ML engineers to interact with a simple CLI to submit code. XPK handles containerization and deployment to the remote GKE cluster. This enables ML engineers to focus on Python code and models, with the platform and XPK managing remote execution complexities.
Table 2: ML Engineer Tools on Google Cloud (Ray, SkyPilot, XPK) — Capabilities and Benefits for Fast Iteration
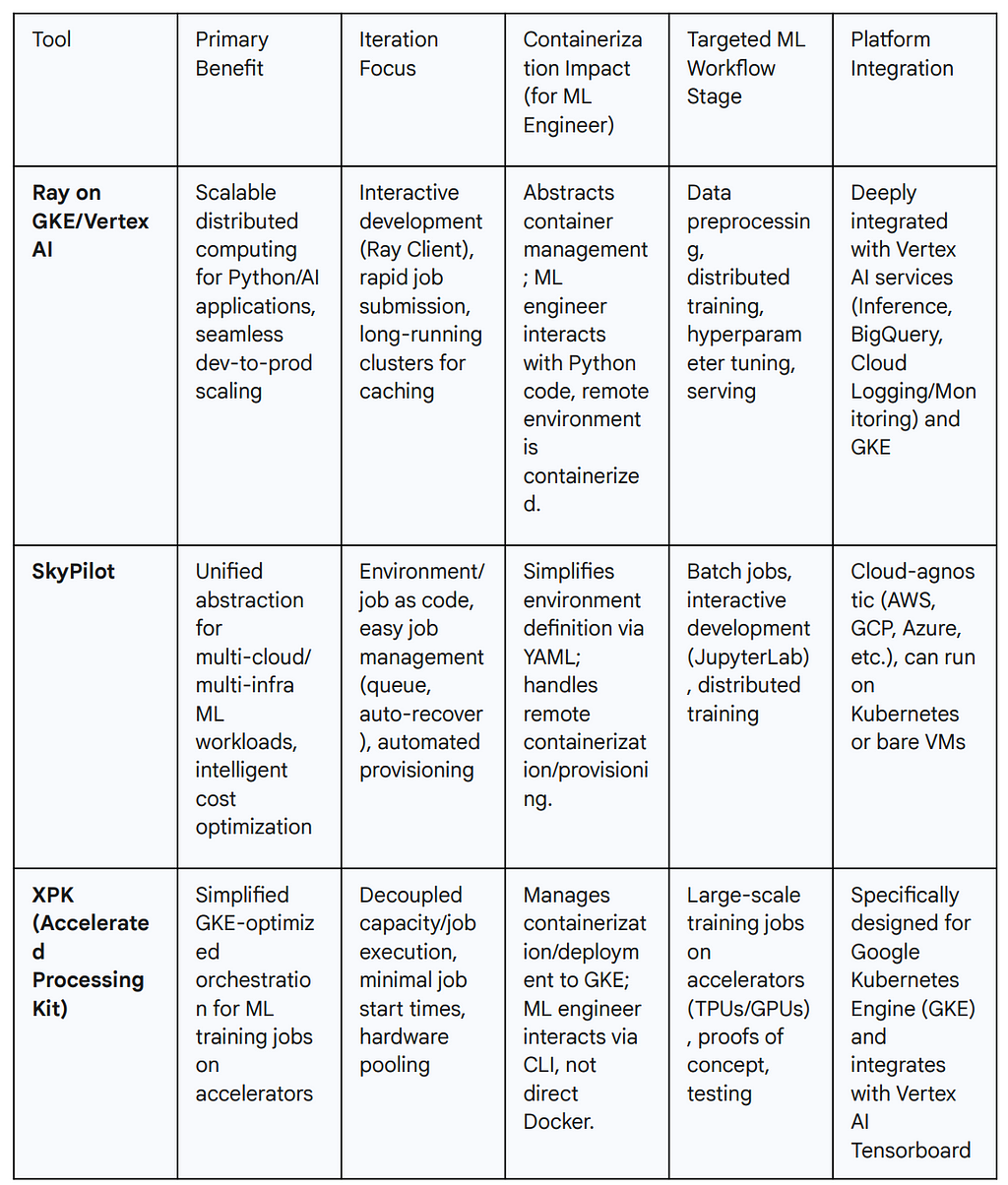
Ray, SkyPilot, and XPK enable rapid iteration and ease of use for ML engineers through robust abstraction. Instead of manual Dockerfile creation or complex Kubernetes manifests, ML engineers interact with higher-level Python APIs, simple YAMLs, or specialized CLIs. These tools translate ML intent into necessary commands for platform-managed infrastructure. This unifies teams: ML engineers gain simplicity and velocity, while platform engineers retain control and visibility over managed, remote environments. This shifts the “containerization burden” from the developer’s local machine to the automated platform, fostering productive collaboration.
IV. The Future of AI Infrastructure: Trends for Optimization and Collaboration
The convergence of platform and ML engineering involves establishing practices and a culture of shared responsibility and continuous optimization. Several key trends shape this future, ensuring optimal balance of performance, reliability, and cost in AI infrastructure.
MLOps as the Unifying Practice
MLOps (Machine Learning Operations) integrates ML, software engineering, and operations to streamline the entire ML model lifecycle, from development to deployment, monitoring, and maintenance. It bridges data scientists/ML engineers (model builders) and operations/platform engineers (reliability enforcers).
Key MLOps components and practices include:
- CI/CD for ML: Automates building, testing, and deploying ML models, ensuring consistent quality and rapid iteration.
- Versioning: Extends version control to datasets, hyperparameters, model configurations, and trained model weights for reproducibility and traceability.
- Model Monitoring and Management: Continuous monitoring of model performance and detection of data/concept drift, with tools to track metrics, detect anomalies, and trigger retraining.
- Infrastructure Management: Efficiently manages computational resources for ML models, leveraging cloud platforms for optimized utilization and cost.
- Collaboration and Reproducibility: Fosters teamwork, breaks down silos, and emphasizes consistent environments and clear documentation.
- Governance and Compliance: Addresses model explainability, bias detection, and audit trails, crucial for regulated industries.
MLOps implementation leads to faster time-to-market, improved collaboration, enhanced model maintainability, and consistent performance. It defines the process and cultivates the culture for scalable enterprise AI, ensuring infrastructure capabilities inform model development and vice versa.
Table 3: Key MLOps Practices for Platform-ML Collaboration
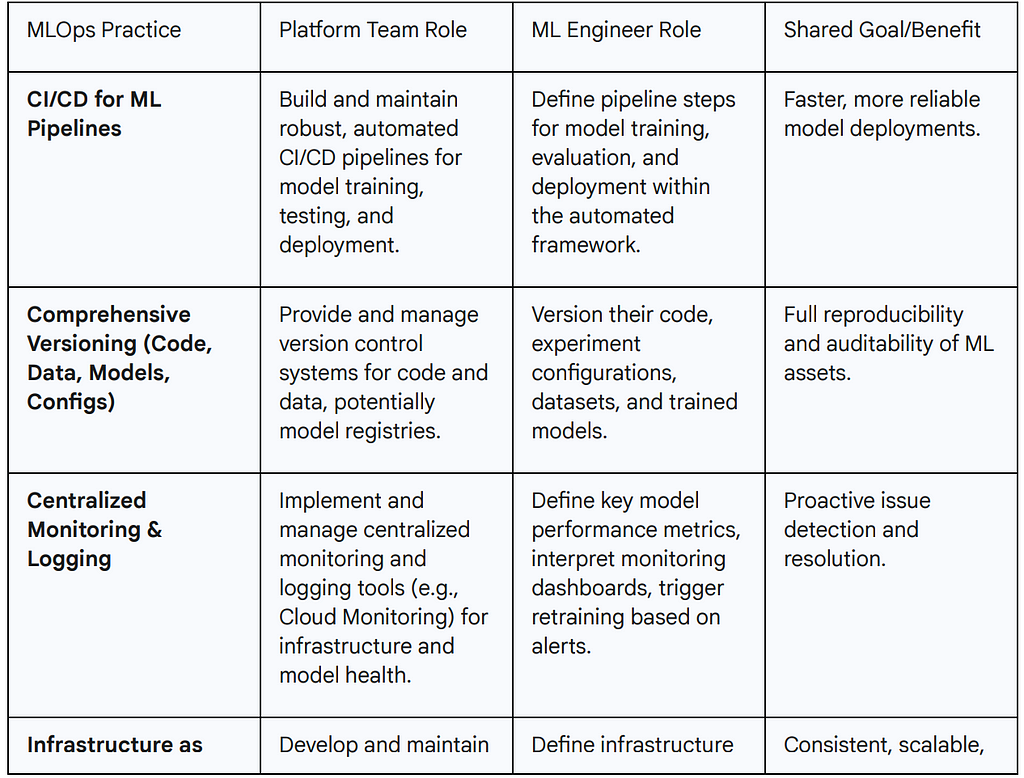
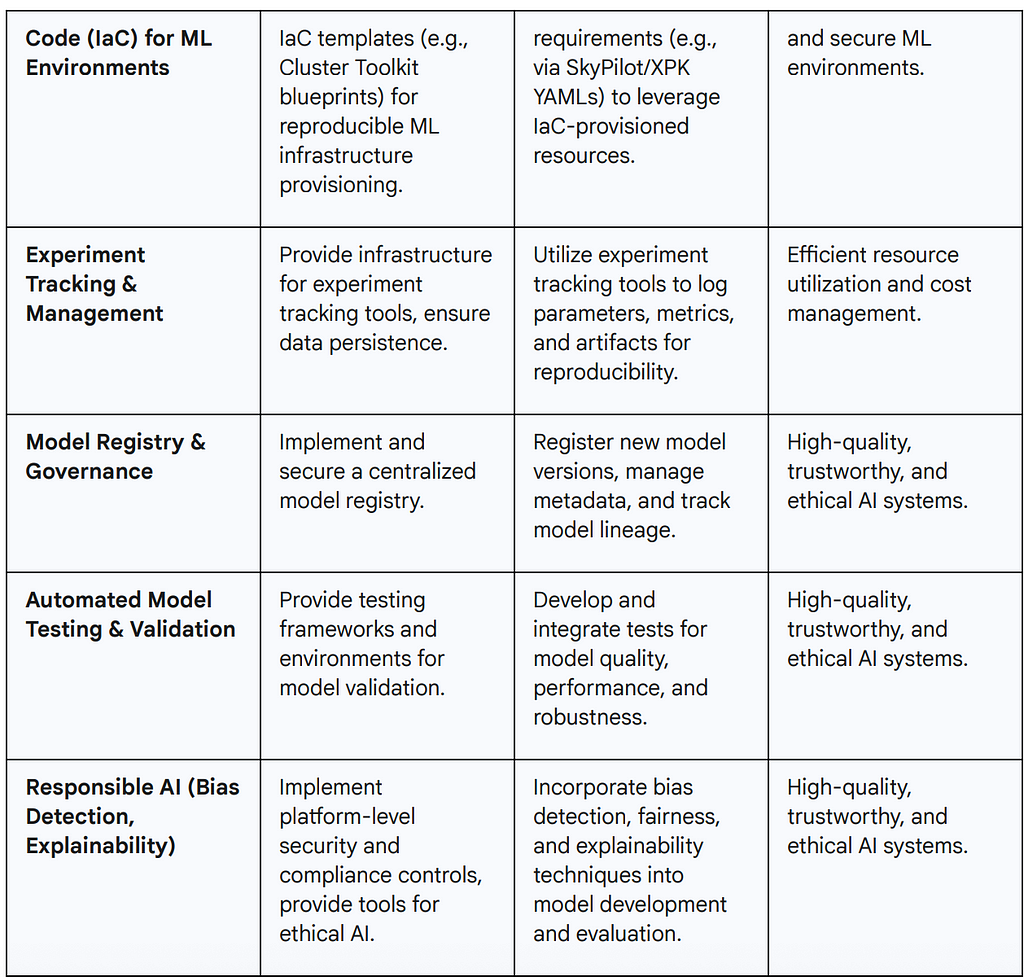
FinOps for AI: Optimizing Cost and Value
As AI workloads scale, cloud costs can become a barrier. FinOps provides a framework to make cost a first-class citizen in AI infrastructure decisions. It’s an operational framework and cultural shift integrating technology, finance, and business to drive financial accountability and accelerate business value from cloud transformation.
Key optimization areas within FinOps for AI include:
- Resource Optimization: Ensures efficient utilization of compute, storage, and network resources for AI workloads, including right-sizing instances, managing idle resources, and optimizing data storage.
- Pricing Optimization: Leverages Google Cloud’s pricing models (committed use discounts, sustained use discounts, preemptible instances, Dynamic Workload Scheduler) to reduce costs for predictable or fault-tolerant AI workloads.
- Architecture Optimization: Designs AI solutions with cost efficiency in mind, e.g., choosing between public foundation models, fine-tuning private models, or standard vs. provisioned capacity for LLMs.
Google Cloud supports FinOps with native cost-management tools for real-time billing analysis, custom reporting dashboards, and automation scripts for guardrails and budget alerts. Mandatory labeling policies for all resources enable precise cost allocation and transparent reporting. FinOps success relies on strong partnership between IT finance, application development, and infrastructure teams.
FinOps for AI provides methodologies for AI cost planning, forecasting, and resource allocation. This empowers financial and engineering teams to understand cost drivers, adapt to innovations, and align financial outlays with business value. It transforms cost from a finance-only concern into a collaborative engineering objective.
Green AI Initiatives: Sustainable AI Infrastructure
The environmental impact of AI is a critical dimension of infrastructure optimization. Large-scale AI and Generative AI are energy-intensive, with data centers consuming significant and growing electricity.
Strategies for sustainable AI include:
- Energy-Efficient AI Models: Optimizing algorithms to use less energy via model pruning, quantization, and knowledge distillation.
- Sustainable Data Centers: Investing in renewable energy-powered facilities and liquid cooling systems for GPUs and AI chips. Google uses AI-optimized energy management to cut data center consumption by 40%.
- Hardware-Software Co-Design: Building AI-specific chips and optimizing software for maximum energy efficiency.
- Edge AI Processing: Moving computations closer to data sources and users to reduce reliance on centralized cloud processing.
- Next-Gen Computing: Future breakthroughs like optical and quantum AI hold potential for dramatic energy reduction.
While platform teams manage physical infrastructure, ML engineers’ choices in model architecture and training efficiency directly impact energy consumption, making Green AI a shared objective. Green AI is transitioning from a niche concern to a fundamental imperative, adding a crucial dimension to platform and ML engineer collaboration.
Balancing Performance, Reliability, and Cost
Optimal AI infrastructure involves a continuous balance between performance, reliability, and cost. High performance often requires significant compute, increasing costs. High reliability necessitates redundancy, monitoring, and automated recovery, adding complexity and potential cost. Aggressive cost-cutting can compromise performance and reliability.
MLOps provides the operational framework for reliability and performance. FinOps introduces financial accountability and optimization strategies for cost management. Green AI adds environmental sustainability, pushing for energy-efficient practices that can also lead to long-term cost savings.
By embracing these trends and leveraging Google Cloud’s comprehensive tools, organizations foster a collaborative environment where platform and ML engineers work in concert. This synergy enables deployment of AI systems that are powerful, innovative, robust, cost-efficient, and environmentally responsible, ultimately accelerating the realization of business value from AI investments.
Don’t forget to check out other GKE related resources on AI ML infrastructure offered by Google Cloud and check the resources included in the AI/ML orchestration on GKE documentation.
Bridging the Divide: Unifying Platform and ML Engineering on Google Cloud for Next-Gen AI was originally published in Google Cloud - Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
11 Jul 2025, 12:22 pm
Gemini CLI Tutorial Series — Part 5 : Github MCP Server
Gemini CLI Tutorial Series — Part 5 : Github MCP Server
Welcome to Part 5 of the Gemini CLI Tutorial series.
Gemini CLI Tutorial Series:
Part 1 : Installation and Getting Started
Part 2 : Gemini CLI Command line options
Part 3 : Configuration settings via settings.json and .env files
Part 4 : Built-in Tools
Part 5: Using Github MCP Server (this post)
Model Context Protocol (MCP) has well established itself over the last year as the standard way for AI Clients to connect to external tools. This is not going to be a tutorial on MCP since there is enough material on the web to understand that. I am assuming that you know the value that MCP brings to the table and it was good to see that Gemini CLI supports MCP since its initial release. This means we can look at integrating MCP Servers to augment the functionality that Gemini CLI already has via its model and built-in tools.
This tutorial will take you through how we configure MCP Servers in Gemini CLI, a few commands then within Gemini CLI to work with them and along the way, we shall we setting up the Github official MCP Server and then doing a little exercise of seeing how Gemini CLI helped me fix a problem in my Github repo by detecting the problem, doing the fix and then pushing the changes back to the remote repository.
Configuring MCP Servers
Before we get to the exact place you will configure MCP Servers, let’s get familiar first with the Gemini CLI and what happens on a system, where you have just installed Gemini CLI and no MCP servers have been setup yet.
I would also like to describe that I am currently in a folder named gemini-cli-projects in my home folder. I have setup Gemini to authenticate via Vertex AI and my GOOGLE_CLOUD_PROJECT and GOOGLE_CLOUD_LOCATION values have been setup in the .gemini/.env folder in the current folder i.e. gemini-cli-projects.
When I launch Gemini CLI, I can check up on the MCP servers configured via the /mcpcommand as shown below:
It also opens up the documentation for the configuration, that is available over here: https://github.com/google-gemini/gemini-cli/blob/main/docs/cli/configuration.md . You will need to go to the mcpServers section for that.
gemini-cli/docs/cli/configuration.md at main · google-gemini/gemini-cli
If you look at my current settings.json file, it has the following content:
{
"selectedAuthType": "vertex-ai",
"theme": "Default",
"preferredEditor": "vscode"
}To add an MCP Server, we need to have the mcpServers property above and inside of that configure our MCP Servers.
It should look something like the following:
{
"selectedAuthType": "vertex-ai",
"theme": "Default",
"preferredEditor": "vscode",
"mcpServers": {
"server_name_1": {},
"server_name_2": {},
"server_name_n": {}
}
}Each of the server objects has a name as you can see and then a list of parameters. The documentation provides a clear description of them:
- command (string, required): The command to execute to start the MCP server.
- args (array of strings, optional): Arguments to pass to the command.
- env (object, optional): Environment variables to set for the server process.
- cwd (string, optional): The working directory in which to start the server.
- timeout (number, optional): Timeout in milliseconds for requests to this MCP server.
- trust (boolean, optional): Trust this server and bypass all tool call confirmations.
Let’s look at configuring a few MCP Servers now to understand how it all comes together.
There is one point to note before we configure a few of these servers. Gemini CLI is able to integrate with your host system, as a result of which, if you already have these utilities configured on your system, chances are good that Gemini CLI will be able to find them and execute them for you. So you will have to make a choice if you need to have the MCP Server or not. For e.g. if you already have git installed and setup on the host system, Gemini CLI should be able to invoke the commands.
Github MCP Server
The Github official MCP Server provides sufficient documentation on the tools that it exposes along with how to configure the same. You can pick your choice in terms of running it locally or remotely, since Gemini CLI supports remote MCP Servers too.
GitHub - github/github-mcp-server: GitHub's official MCP Server
In this tutorial, I have chosen to the Remote MCP Server option in Github. For this, you will need to have a Personal Access Token (PAT) from Github.
Managing your personal access tokens - GitHub Docs
The MCP Server object that we will need to put in the settings.json file is shown below:
"github": {
"httpUrl": "https://api.githubcopilot.com/mcp/",
"headers": {
"Authorization": "<YOUR_GITHUB_PAT>"
},
"timeout": 5000
}My settings.json file in .gemini folder in the home directory looks like this now:
{
"selectedAuthType": "vertex-ai",
"theme": "Default",
"preferredEditor": "vscode",
"mcpServers": {
"github": {
"httpUrl": "https://api.githubcopilot.com/mcp/",
"headers": {
"Authorization": "<MY_GITHUB_PAT>"
},
"timeout": 5000
}
}
}Let me start Gemini CLI with this and I see the following on the home screen at startup (Notice that it says Using 1 MCP Server):
At this point, if you give the /mcp command, you will see the following:
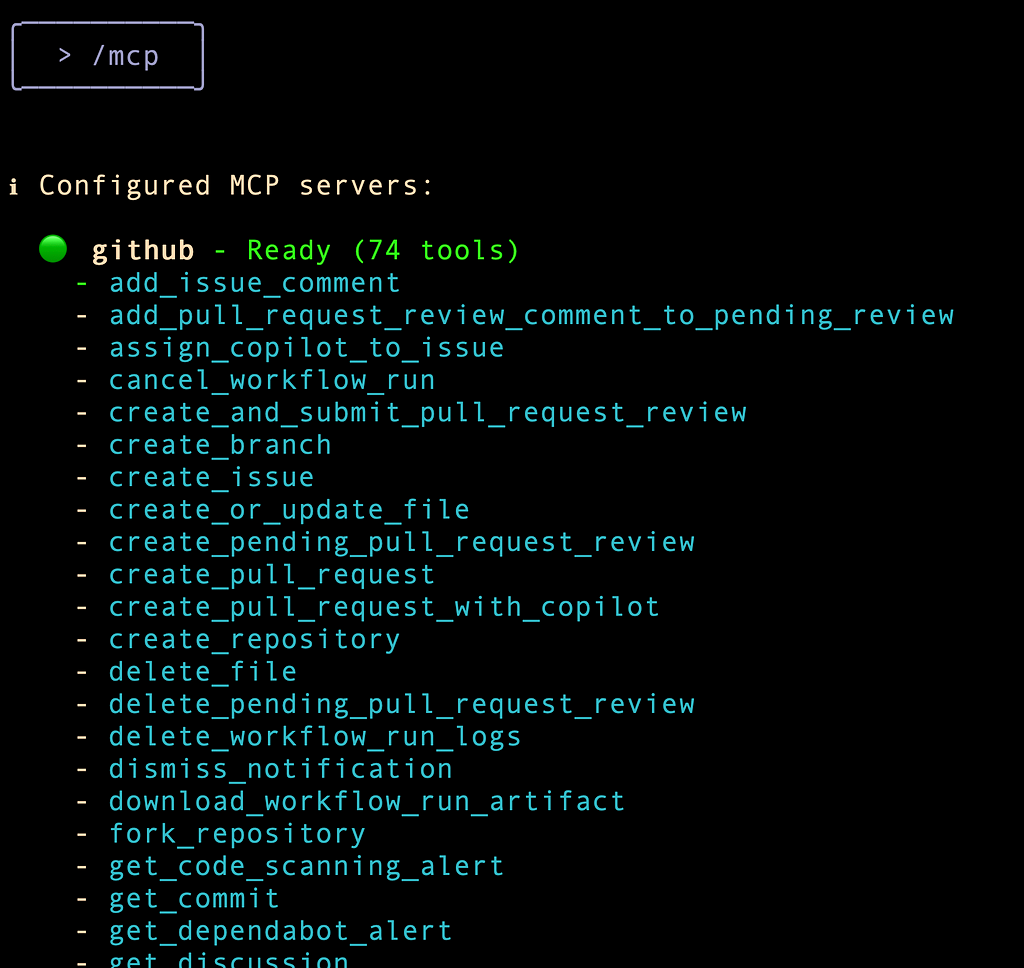
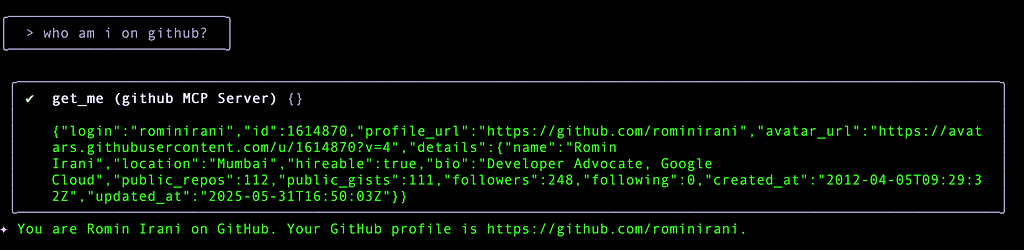
I try out a little exercise to find out if it can use the tool to know who I am. It picks up the right tool get_me from the Github MCP Server and displays the required information, as shown below:
Gemini CLI — Discover an issue automatically
I want to get around to doing something interesting with Gemini CLI and one of my repositories. So while it is not exactly just a MCP server configuration, its a nice little exercise to see the kind of stuff that Gemini can identify and fix for us too.
One of my repository is https://github.com/rominirani/adk-projects and it contains a bunch of Agent Development Kit (ADK) projects that I have created when I was learning the framework. I have a README.md file that has a list of all the folders, each of which contains a sample agent that has been developed using ADK.
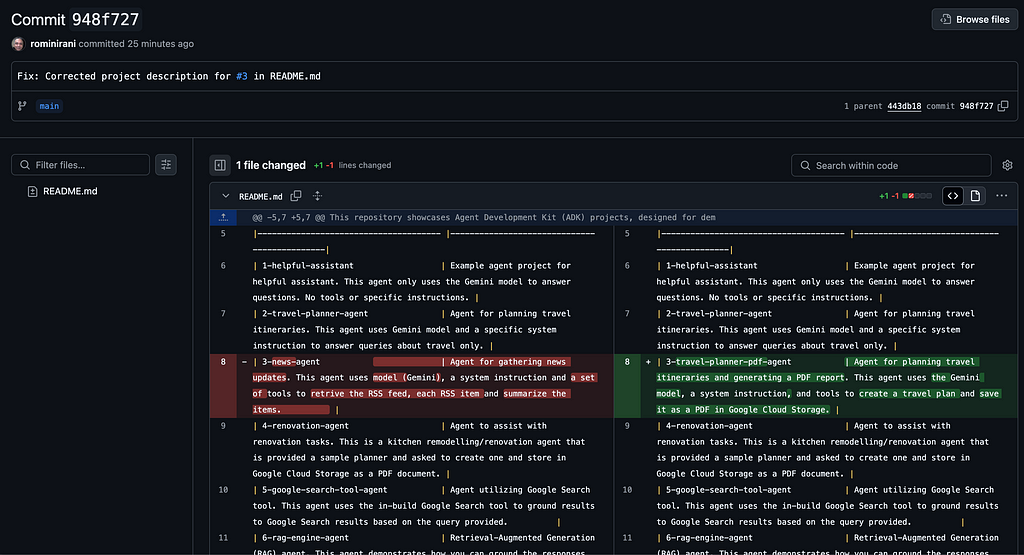
The README.mdfile has a problem in that one of the descriptions / folder is incorrect. The current README.md file is shown here:

The 3rd entry is incorrect. There is no folder like that or description. I want to see if Gemini CLI can figure this out and then make the changes. Then we shall use the MCP Github server configured tool to push back the changes.
So, lets ask what’s there in the adk-projects repository that I own:
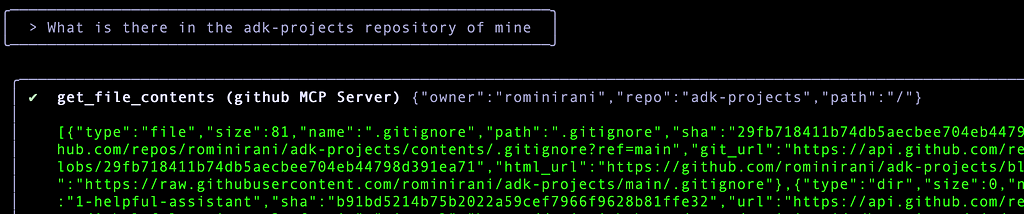
There is a lot of text and then it gives me the following summary:
The adk-projects repository contains a .gitignore file, a README.md file,
and 10 directories, each appearing to be a separate project.
The project directories are numbered 1 through 10 and have descriptive names
like 1-helpful-assistant, 2-travel-planner-agent, and so on.
I get down to the real task now and tell Gemini CLI:
I’d like to fix a problem in the README.md file. How can I do that?
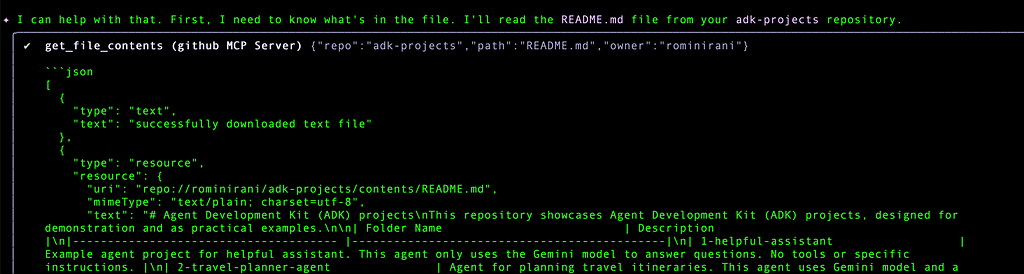
It picks up the right tool from the MCP Server again to get the file contents and reads the content:
But then, when I ask it will you be able to find that out by getting all the files and the folders inside of it?, it mentions the following:
Yes, by listing the files and folders, I can see the structure of your
repository. This helps me understand the context of your projects.
However, to know what to fix in the README.md file, I need you to
tell me what the problem is.
I can't determine that just by looking at the file names.
This is understandable, so the next thing that I ask
Please get clone the repository from github here on my local system
This makes it execute the git clone command successfully and it gets the copy locally.

Fantastic ! Then I pass in the following command, asking it to go through the README.md file, all the folders and figure out the mistake.
Go through the @adk-projects/README.md and the @adk-projects/ and
determine the issue with the README.md file
It does an excellent job in detecting the problem as shown here and to which I ask it to fix it:
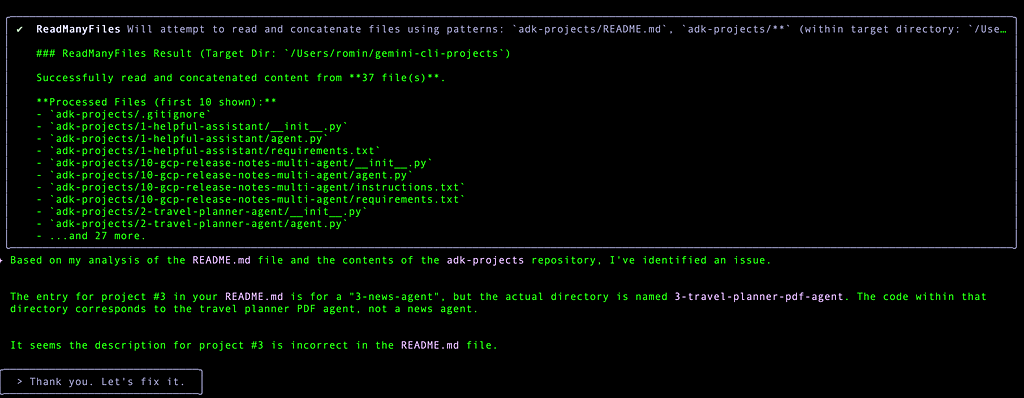
Lovely, its identified the fix and corrected it too.
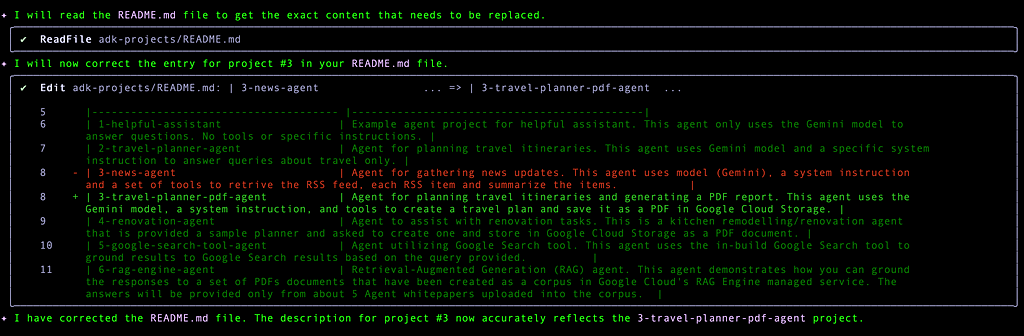
My next step would be to help me out with committing those changes locally, adding a commit message and then pushing the changes back to remote.
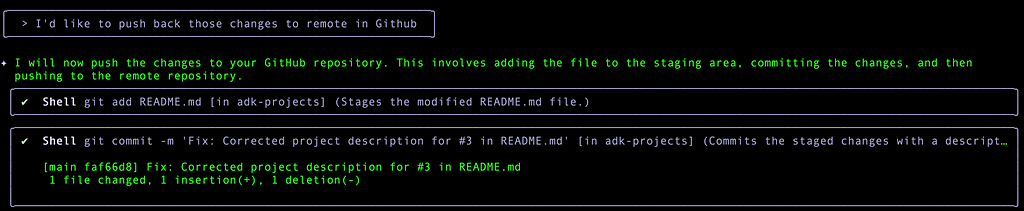
But when it tried to push, it also knows that there is a git utility on my system and it chose to use that instead of the MCP Server that we have setup. Since I did not setup my Personal Access Token on my system, it gave the following error:
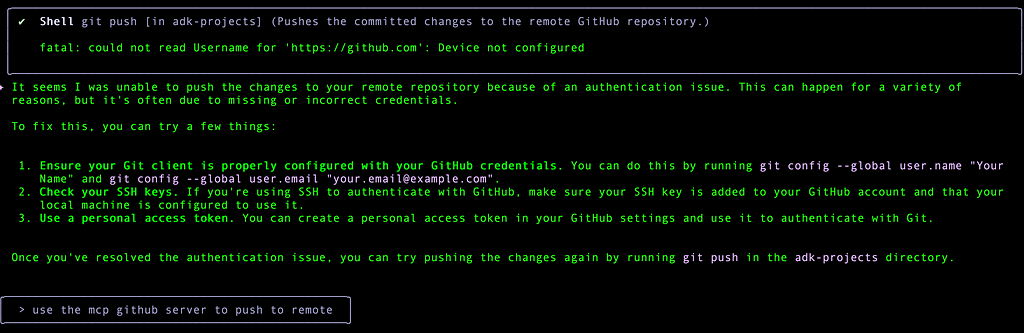
So as you can see in the last statement, I asked it to use the MCP Github Server instead, since the Personal Access Token (PAT) has been configured there.
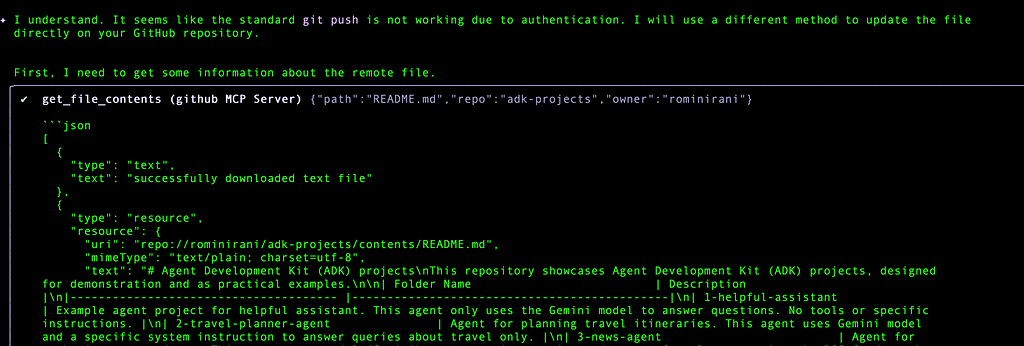
It does it’s work and then reaches the final step to push and completes it successfully.
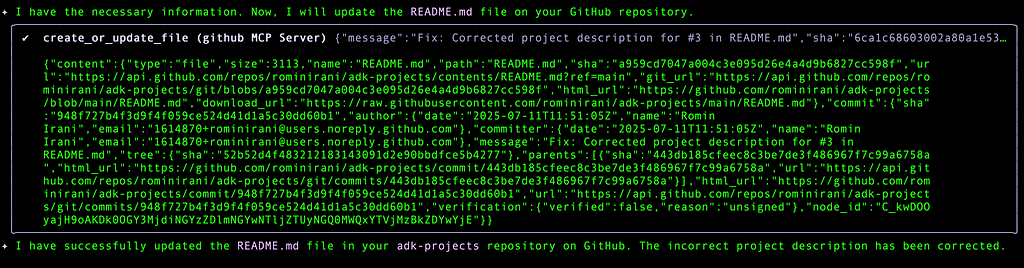
Here’s the commit from the Github repository.
Conclusion
This concludes Part 5 of the series. I decided to keep this part separate to demonstrate both configuring MCP Servers in Gemini CLI and also to do an exercise of how Gemini CLI worked on its own to determine the problem in one of my repositories, suggested a fix and then helped me commit the changes to the Github repository via some of the tools from the Github MCP Server that we configured in Gemini CLI.
In the next part, we will move a bit faster with MCP Server configurations and look at other MCP Servers : Firebase MCP Server, Google Generative AI MCP Servers (Imagen, Veo, Lyria, Chirp, etc) and possibly look at writing our own MCP Server and configuring it inside Gemini CLI. Stay tuned.
Gemini CLI Tutorial Series — Part 5 : Github MCP Server was originally published in Google Cloud - Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
11 Jul 2025, 4:23 am
AI Expense Tracker using Gemini 2.5 Flash, Google ADK, and Firestore
Overview
ExpenseTracker is an AI-powered web app that I built to help users effortlessly track expenses, manage monthly budgets, and gain insights into their spending habits through a conversational interface powered by Gemini AI, Google ADK, and Google Firestore.
Tech Stack
- Google ADK: Google ADK is an open-source framework for building and deploying collaborative AI agents.
- ADK Web UI: The ADK Web UI provides a browser-based interface to interact with and debug your AI agents built with the Google ADK.
- Google Firestore: A scalable, serverless NoSQL database for storing user expenses and budgets.
- Gemini Flash 2.5: An agentic language model for natural language understanding and reasoning.
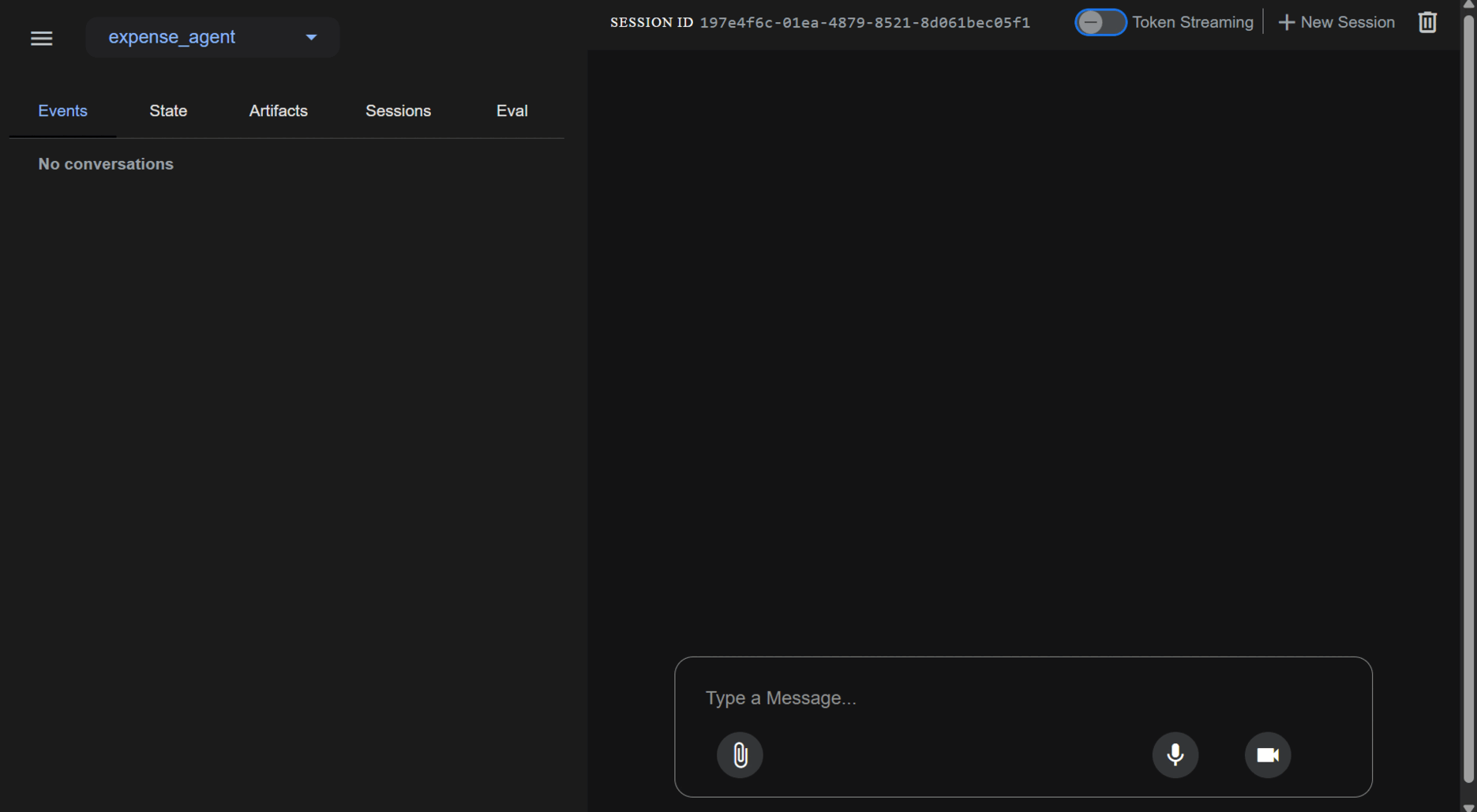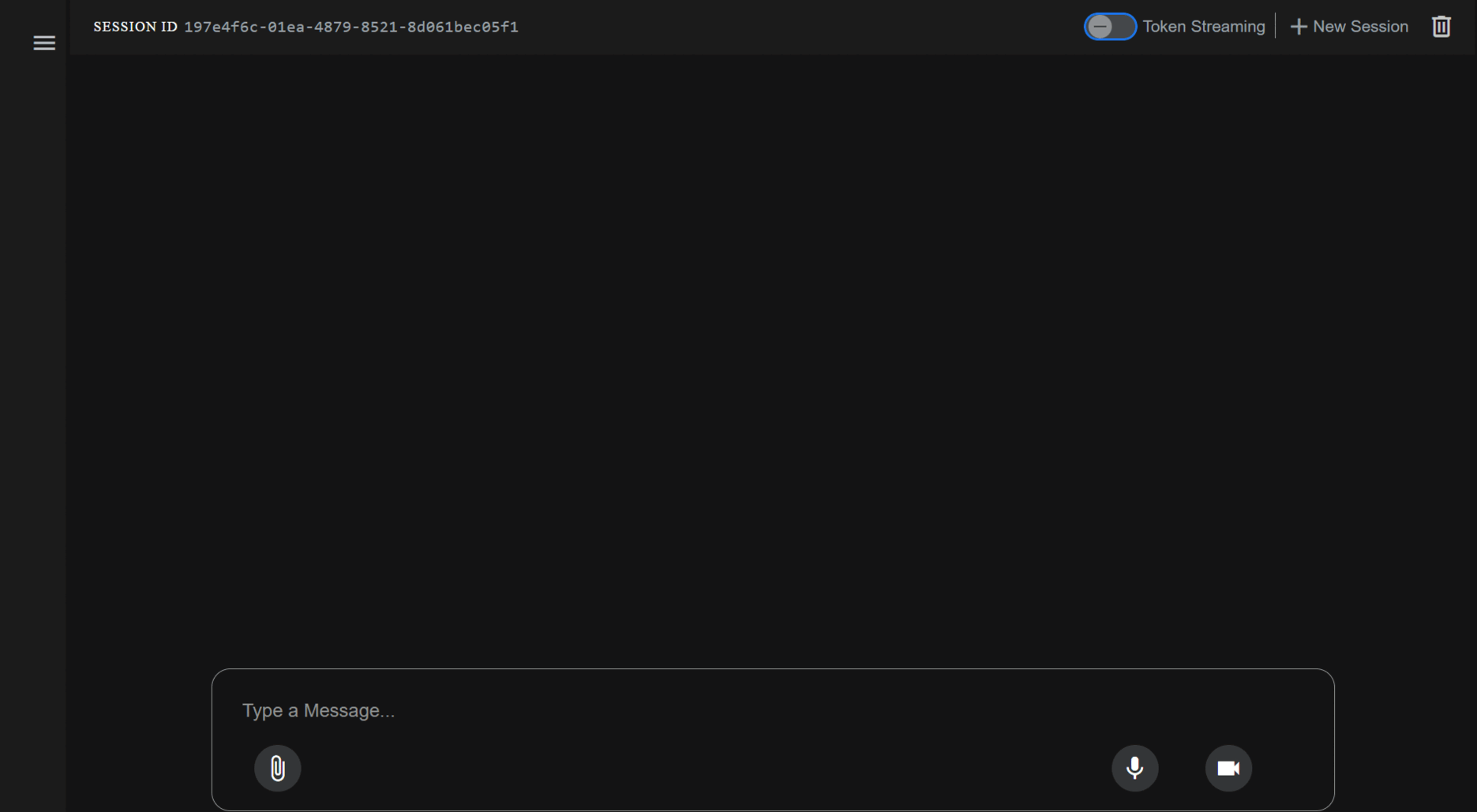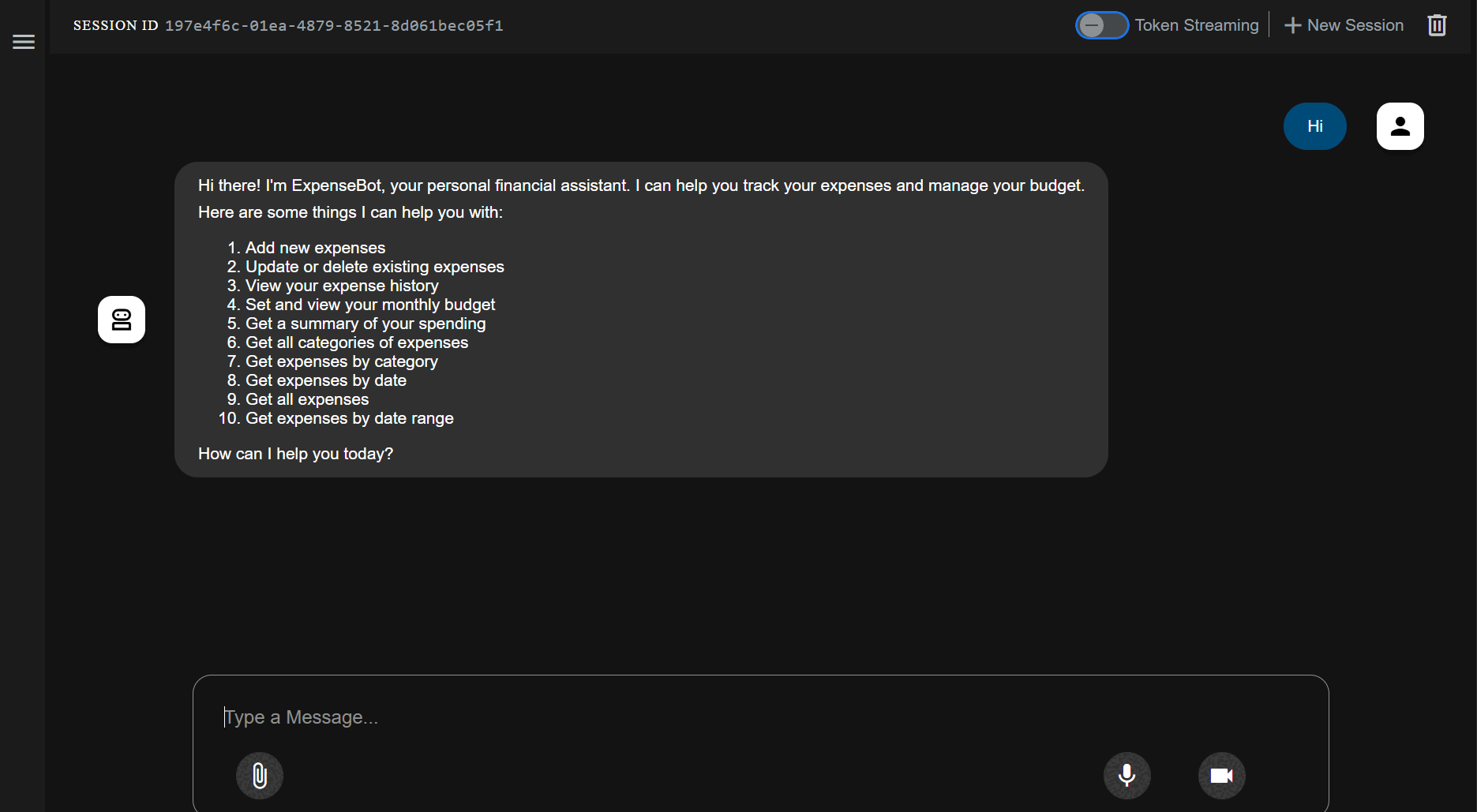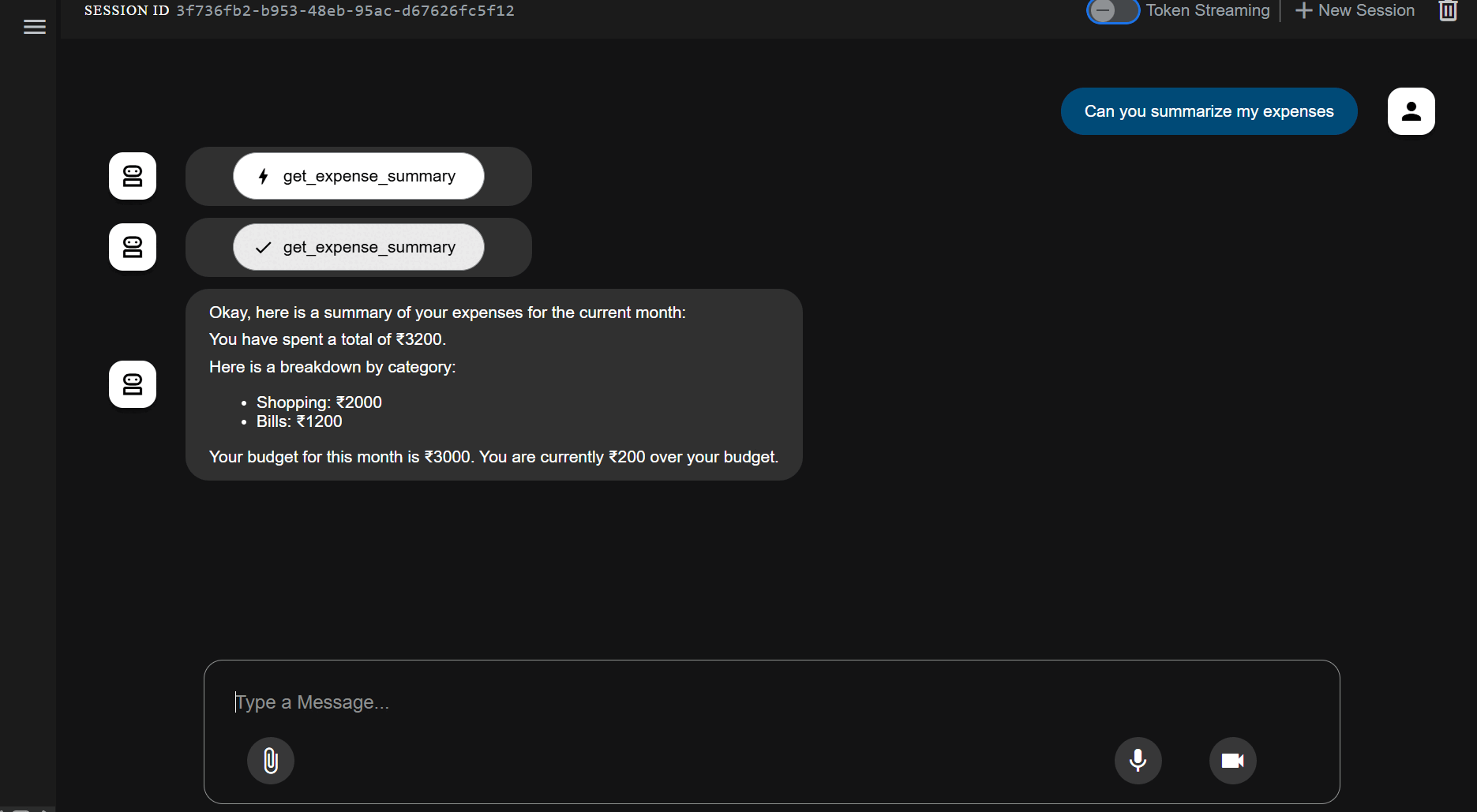
Setup
Create a new Google Cloud Project:
Sign in or sign up for the Google Cloud Console and create a new project. Store the project ID for further use cases.

Start the Google Cloud Shell, a remote shell environment in the cloud.

Create Environment variables for REGION and PROJECT_ID.
export PROJECT_ID=<your project id>
export REGION=us-east1
Enabling APIs.
gcloud services enable artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
run.googleapis.com \
firestore.googleapis.com
Create a Firestore Database
The documentation has more complete steps to set up a Firestore instance. At a high level, to start, I will follow these steps:
- Go to the Firestore Viewer and from the Select a database service screen, choose Firestore in Native mode
- Select a location for your Firestore (Make sure to choose us-central1 and follow this wherever you choose region/location throughout this codelab)
- In the security rules, select the “OPEN” so Security Rules so that the data is accessible.
- Click Create Database (if this is the first time, leave it as “(default)” database)
When you create a Firestore project, it also enables the API in the Cloud API Manager.
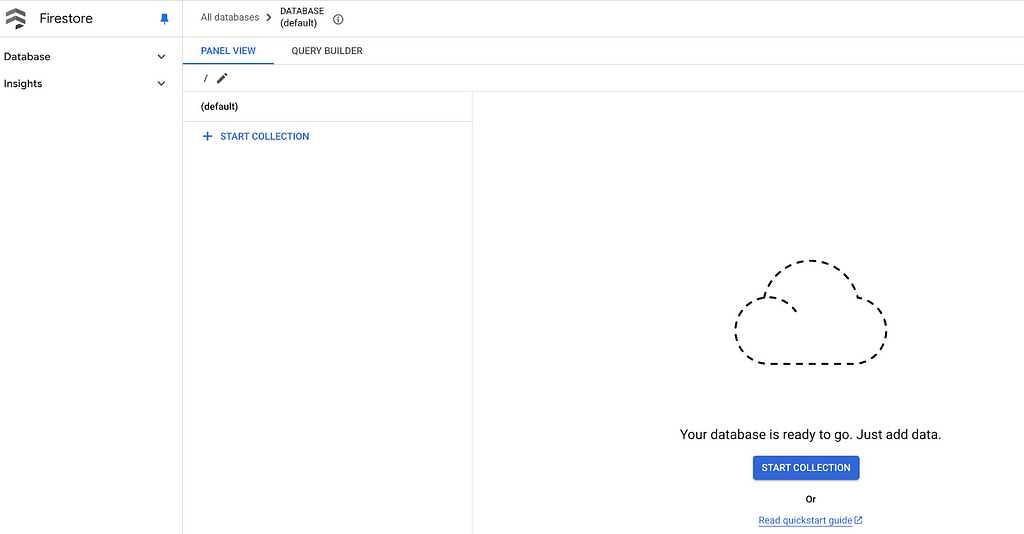
Once it’s set up, you should see the Firestore Database, Collection, and Document view in Native mode as seen in the image below:
Create a GCP Service Account
A service account is a Google Cloud identity used by applications and services to access Google Cloud resources programmatically.
Create a new service account using this command. (Use the same terminal opened in the previous section)
gcloud iam service-accounts create expense-tracker-sacc
To provide access to your project and resources, grant a role to the service account.
gcloud projects add-iam-policy-binding ${PROJECT_ID} --member="serviceAccount:expense-tracker-sacc@${PROJECT_ID}.iam.gserviceaccount.com" --role=roles/datastore.ownerGet GEMINI API Key
Google AI Studio is a web-based platform for prototyping and experimenting with Google’s generative AI models.
- Visit aistudio.google.com and sign in using the same Google Account associated with your Google Cloud Console project.
- In the top navigation bar, click “Get API Key” to access the API key management page.
- Click “Create API Key”, then select the Google Cloud project you created earlier. Your new API key will be generated.
- Save this API key securely — you’ll need it to run and deploy the application.
Great, we’re all set! Now, let’s dive into building the Agentic system and explore how it interacts with our databases.
Why Firestore?
Let’s see why we chose Firestore as our primary database.
Firestore is a serverless, real-time NoSQL database that perfectly fits ExpenseTracker’s AI-driven, chat-based workflow. It offers:
- Flexible Schema: Easily stores structured data like expenses and budgets.
- Tight Integration: Works seamlessly with Google Cloud and Gemini APIs.
- Secure & Scalable: Granular access rules and built-in scalability for growth.
- Event Triggers: Pairs well with Cloud Functions for reactive flows like alerts or summaries.
Agentic System Building
Agentic systems shift from traditional software to intelligent, autonomous modules that interpret data, make decisions, and act independently. The Expense Agent uses AI to simplify adding and categorizing expenses with natural language and image processing.
Features of the Expense Agent
Our Expense Agent enhances the typical expense tracking workflow by handling unstructured inputs — text and images — with minimal user effort.
- Smart Text Parsing: Users can type entries like “Paid ₹500 for Zomato yesterday”, and the agent extracts the amount, vendor, category, and date automatically.
- Image-Based Entry: Upload a receipt, and the agent, using Gemini multimodal APIs, analyzes it to extract key data like total amount, vendor name, and purchase date.
- Persistence: The Agent stores the extracted expense data in the Firestore database using the available tools.
How do Agents use Tools?
Agents can’t directly access databases, APIs, or websites. So we give them tools, aka functions, that do those actions (like search, fetch data, update records). The agent “calls” these tools when needed.
Example Interactions
- Add ₹500 for groceries yesterday.
- Set my monthly budget to ₹10,000”.
- Show me my expenses for travel this month.
Deploy the Application
Clone the repository and go to the directory.
git clone https://github.com/bhaaratkrishnan/expense-tracker-gcp.git
cd expense-tracker-gcp
Open Google Cloud Editor and replace GEMINI_API_KEY in the Dockerfile with your API KEY.
If the database name for the Firestore is not (default), mention it as an FIRESTORE_DB environment variable in the
Docker file

Deploy the application to Cloud Run using this command:
gcloud run deploy expense-tracker-gcp --source=. --port=8000 --allow-unauthenticated --service-account=expense-tracker-sacc@${PROJECT_ID}.iam.gserviceaccount.com --project=${PROJECT_ID} --region=us-east1Yaay !! Expense Tracker is up and running.
Expense Tracker is designed to simplify personal finance management and add a touch of fun. Give it a try and let Gemini models make your financial life easier and more enjoyable!
AI Expense Tracker using Gemini 2.5 Flash, Google ADK, and Firestore was originally published in Google Cloud - Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
11 Jul 2025, 4:22 am
Simplify your Open Telemetry tracing in Google Cloud
OpenTelemetry (OTel) is the go-to standard for monitoring applications, offering a vendor-neutral way to capture telemetry data like traces, metrics, and logs. This enables consistent instrumentation and avoids vendor lock-in. Developers widely use OTel to instrument applications, with exporting telemetry data to Google Cloud Observability services.
OTel’s native data format follows OTLP (standing for OpenTelemetry Protocol) standard. To export OTel data to Google Cloud usually requires exporters like Google Cloud Trace Exporter for Go that exist for most of the popular programming languages. What these exporters do is:
1. Transform the telemetry data from OTLP format into a proprietary format defined by the Cloud Observability service (e.g. Cloud Trace).
2. Sends the transformed data using the service API.
While this approach works, you should consider several factors when using Google Cloud-specific exporters.
- Additional Complexity: In some configurations the use of the Google Cloud-specific exporter library requires extra dependencies or customization to OTel collector pipeline.
- Vendor Awareness: If the export code is a part of the application, using a specific vendor’s exporter makes the instrumentation code depending on this vendor. If you ever need to send telemetry to a different backend, the change will require adding another vendor-specific exporter.
- Risk of Data Loss: Despite the best effort the transformation of the telemetry data from the OTLP data format to the proprietary format can result in some data loss. For example it can occur if the proprietary format has different limits or doesn’t support certain OTLP fields.
In Q2 2025 Google Cloud introduced support for OTLP (referenced as Telemetry API). At this moment (Q3) it supports only Cloud Trace. Now developers can use OTel native exporter to post data to the trace endpoint:
https://telemetry.googleapis.com/v1/traces
To use the Telemetry API to write traces you will need Cloud Telemetry Traces Writer (roles/telemetry.tracesWriter) role or, if you authenticate using OAuth, the following OAuth scopes:
- https://www.googleapis.com/auth/trace.append
- https://www.googleapis.com/auth/cloud-platform
Migrating from the Trace exporter to the native OTLP endpoint
Let’s see how the use of Telemetry API looks in practice using an example of the Go application that already uses OTel to generate metrics and traces and uses Google Cloud-specific exporters.
The first step is to add code that reads the application default credentials from the runtime environment. The example runs as a Cloud Run service and uses the compute engine default service account unless you set differently. The following code adds import packages:is added to the setup.go file that configures telemetry:
import (
// add the following import packages
"google.golang.org/grpc"
"google.golang.org/grpc/credentials/oauth"
)
And reads credentials:
func setupTelemetry(ctx context.Context) (shutdown func(context.Context) error, err error) {
// …
// add this code after call to otel.SetTextMapPropagator()
scopes := []string{
"https://www.googleapis.com/auth/trace.append",
"https://www.googleapis.com/auth/cloud-platform",
}
creds, err2 := oauth.NewApplicationDefault(ctx, scopes…)
if err2 != nil {
err = errors.Join(err2, shutdown(ctx))
return
}
// …
}The second step updates imported packages to replace the Google’s trace exporter with the native OTLP exporter: replaces the existing exporter with the native OTLP exporter and configures it to use the credentials from the first step:
import (
// replace package github.com/GoogleCloudPlatform/opentelemetry-operations-go/exporter/trace with the following two
"go.opentelemetry.io/otel/attribute"
"go.opentelemetry.io/otel/exporters/otlp/otlptrace/otlptracegrpc"
)
And further updates setupTelemetry method to initialize the OTLP exporter with the credentials from the first step:
func setupTelemetry(ctx context.Context) (shutdown func(context.Context) error, err error) {
// …
// replace the call to resource.New() with the following version
res, err2 := resource.New(ctx,
resource.WithDetectors(gcp.NewDetector()),
resource.WithTelemetrySDK(),
resource.WithAttributes(
semconv.ServiceNameKey.String(os.Getenv("K_SERVICE")),
attribute.String("gcp.project_id", projectID),
),
)
// …
// replace the call to cloudtrace.New() with the following
texporter, err2 := otlptracegrpc.New(ctx,
otlptracegrpc.WithEndpoint("telemetry.googleapis.com:443"),
otlptracegrpc.WithDialOption(grpc.WithPerRPCCredentials(creds)),
)
// …
}The changes do the following:
- Each span in the trace will be generated with additional attribute gcp.project_id that is used by Telemetry API to determine the span’s destination
- The native OTLP exporter is configured to use the Telemetry API endpoint with the Cloud Run service’s service account credentials
This example uses OTLP/gRPC exporter, which is the recommended transport for Google Cloud APIs. The format of the endpoint follows the hostname:port notation requested for gRPC. An OTLP/HTTP alternative (otlptracehttp) also exists. It would require using https://... URL for the endpoint and different credential handling.
This is all. After these changes are applied, do not forget to update dependencies and download missing packages by running the go CLI command:
go mod tidy
Now your code does all the same but uses native OTLP to export trace data to Cloud Trace. You can see examples for Java, NodeJS and Python in the same repository.
Note that the example configures the resource attribute and the OTLP exporter’s endpoint in the code. It is done to avoid unexpected value injections. The same configuration can be done using environment variables. You can see the migration guide in documentation for the example.
Before running the example, ensure you have completed the following:
1) Enable the Telemetry API on the project where you deploy the example. Use the following command to do it from the shell:
gcloud service enable telemetry.googleapis.com - project=${YOUR_PROJECT_ID}2) The example deploys Cloud Run service that uses the default compute engine service account. The service account associated with the service should be granted the roles/telemetry.tracesWriter role to allow it using Telemetry API.
Migrate OTel Collector configuration
Before wrapping up, let’s look at what to do if the application uses OTel Collector instead of having the exporter coded inside the source code. In this scenario the migration includes only changes in the OTel Collector configuration. Follow these steps to update the collector’s configuration file and restart the collector.
- Remove the googlecloud exporter from the configuration and from the traces pipeline
- Modify the collector’s configuration with the changes shown below:
extensions:
# add auth extension
googleclientauth:
processors:
# add resource attribute
resource/gcp_project_id:
attributes:
- key: gcp.project_id
value: "YOUR_PROJECT_ID"
action: insert
exporters:
# add OTLP exporter
otlp:
auth:
authenticator: googleclientauth
endpoint: telemetry.googleapis.com:443
service:
# update the following lists by appending the values after …,
extensions: […, googleclientauth]
pipelines:
traces:
exporters: […, otlp]
processors: […, resource/gcp_project_id]
These changes do the following:
- Add the googleclientauth extension that reads the application default credentials from the runtime environment
- Insert the gcp.project_id resource attribute with the value of the project ID to which spans will be exported
- Sets the OTLP exporter’s endpoint and authentication configuration to enable the exporter to send spans to Telemetry API
The changes in the service section reflect the added extension, processor and exporter to the existing lists. Note that the list of the trace exporters under the service section should not include the Google Trace Exporter unless you want to duplicate the spans.
The use of the googleclientauth extension reads credentials at runtime and eliminates the need to statically store credentials such as OAuth client ID or secret inside the configuration file.
The OTLP exporter and the googleclientauth extension are a part of most popular builds of the OTel collector. (e.g. Google-Built OTel Collector) If the build of the OTel Collector in use does not include them, follow documentation to build the version of the collector with these packages.
Wrapping up
Using native OTLP exporter for transferring spans to Cloud Trace has no drawbacks and many benefits including:
- Reduced complexity
- Vendor agnostic pipeline
- Elimination of potential data loss
- Alignment with OTel recommended practices
If your code already uses OTel to generate traces, it is very easy to convert it to using native OTLP endpoint of Google Cloud.
Telemetry API supports OTLP endpoint only for spans now. The support for metrics and logs will be added in the future.
For additional code samples and information look at
- Github repository with examples in Go, Java, NodeJS and Python
- Telemetry API Overview
- Official migration guide from the Trace exporter to the OTLP endpoint
- Google-Built OTel Collector
Simplify your Open Telemetry tracing in Google Cloud was originally published in Google Cloud - Community on Medium, where people are continuing the conversation by highlighting and responding to this story.
11 Jul 2025, 4:21 am
Is Your IT Job Safe? The 3 Google Cloud Skills You Can’t Afford to Ignore in the AI (& Data) Era
A Google Cloud consultant’s perspective on staying relevant in rapidly evolving tech landscape. This content is from my own perspective through my experience and domain knowledge.

The Question That Keeps IT Professionals Awake at Night
Picture this: You’re sitting in your comfortable IT role, confident in your skills, when suddenly your company announces they’re implementing AI agents that can automate 70% of what you do daily. The question isn’t whether this will happen — it’s whether you’ll be ready when it does, equipped with the knowledge and tools to pivot and thrive.
I’ve been working as a Google Cloud consultant across Southeast Asia for the past few years, and I’ve witnessed firsthand how traditional IT roles are being reshaped by technology, especially Cloud, Big Data & now definitely AI. The professionals who thrive aren’t necessarily the smartest or most experienced — they’re the ones who master specific, forward-looking skills that make them indispensable, now in an AI-driven world.
The Journey: From Confusion to Clarity
The pervasive talk about AI’s impact on jobs can be unsettling. However, through my work advising organizations on their AI transformations, a clear pattern has emerged. While many are still debating whether AI will replace jobs, the real winners are already learning to build, orchestrate, and leverage AI systems effectively, not compete with them. This shift demands a new set of capabilities.
The Conflict: Traditional Skills vs. AI-Native Approaches
Here’s the uncomfortable truth: traditional IT skills like basic automation, routine database management, traditional application code development and standard system administration are being commoditized by AI. But this creates an immense opportunity for those who understand how to work with AI systems rather than against them.
The conflict isn’t between humans and AI — it’s between professionals who adapt to AI-driven workflows and those who cling to outdated approaches.
The Uncertain Path: What Skills Actually Matter?
I’ve identified three critical areas where IT professionals must excel to remain not just relevant right now (please kindly note, this is purely driven by my personal thought based on my domain knowledge and experience ):
1. Architecting Intelligent Agent Systems: using Google ADK, A2A, MCP, and Agent Engine
A. The Reality: The future of AI isn’t just about large language models; it’s about intelligent agents that can act autonomously, communicate with each other, and adapt to complex tasks. Building and deploying these sophisticated agent systems requires a specialized toolkit and understanding of their entire lifecycle.
B. What You Need to Know: Google provides a powerful open-source ecosystem to develop, connect, and deploy advanced AI agents.
- Agent Development Kit (ADK): This is Google’s comprehensive open-source framework designed to help developers build sophisticated AI agents. ADK provides the foundational structures and higher-level abstractions for agent development, making it easier to create production-ready, modular, and scalable agents.
- Agent-to-Agent (A2A) Protocol: Announced in April 2025, A2A is a new open standard that enables AI agents to communicate and collaborate seamlessly, regardless of their underlying framework or vendor. ADK helps developers build agents that are A2A-compliant, handling the complexities of agent discovery (via Agent Cards and Registries) and standardized communication (JSON-RPC or HTTP).
- Model Context Protocol (MCP): This open standard by Anthropic standardizes how LLMs (like Gemini and Claude) connect to external applications, data sources, and tools. ADK includes specific tools and integration guides to leverage MCP, ensuring your agents can access and utilize external information and execute actions with rich, standardized context.
- Vertex AI Agent Engine: Once agents are developed with ADK, Vertex AI Agent Engine provides the managed infrastructure to deploy, scale, and manage these production-ready AI agents. ADK’s command-line interface now supports deploying agents directly to the Agent Engine, streamlining the transition from development to enterprise-grade production. You can deploy the solution in Google Kubernetes Engine too if you prefer that approach.
C. Real-World Application: Imagine an “IT Helpdesk Agent” built using the ADK. When a user reports an issue, this agent, through A2A communication (orchestrated by ADK), connects with a “Network Monitoring Agent” and a “System Status Agent” to gather diagnostic information. If the issue requires accessing internal knowledge bases, it leverages MCP (integrated via ADK) to pull relevant articles and execute troubleshooting steps. Finally, this robust agent can be deployed and managed at scale using Vertex AI Agent Engine to serve thousands of employees efficiently.
D. Why This Matters: Mastering these interconnected technologies means you’re not just building AI; you’re building the infrastructure for autonomous, intelligent systems that can truly transform operations and automate complex workflows. This skill set is foundational for the next wave of enterprise AI.
E. Sample Code & Resources:
- Agent Development Kit Documentation — Comprehensive ADK implementation guide.
- A2A Python SDK Examples — Working ADK examples for different use cases, showcasing A2A.
- ADK MCP Tools Documentation — Integration guide for MCP with ADK.
- Start to Code your first application using this free guidance from Codelab & Cloudskillsboost from Google Cloud.
- What’s New in Agent Development Kit (ADK) v1.0.0+ — Latest updates including Agent Engine support.
2. Empowering Productivity: using Google Agentspace for Enterprise Knowledge, Understanding, and Action
A. The Reality: Information silos are a notorious bottleneck in every organization, costing countless hours in lost productivity. The future workplace isn’t about replacing employees — it’s about augmenting their capabilities with AI agents that have deep access to enterprise knowledge, making information actionable.
B. What You Need to Know: Google Agentspace Enterprise is designed to solve this. It empowers employees to find the right information at the right time by connecting content across an organization and generating grounded, personalized answers. Agentspace helps employees Find information swiftly, Understand it in context, and facilitate Action efficiently.
- Find: Agentspace intelligently connects to over 100 apps including Confluence, SharePoint, and Google Drive, allowing employees to discover information scattered across disparate systems.
- Understand: The platform combines Gemini’s reasoning capabilities with Google-quality search to process both structured and unstructured enterprise data, generating grounded, personalized answers. It builds enterprise knowledge graphs that link employees to their teams, documents, software, and available data, providing rich context.
- Action: Beyond just answers, Agentspace aims to facilitate action by putting relevant insights at employees’ fingertips. While it handles many productivity tasks out-of-the-box, custom agents (potentially built with ADK) can further extend Agentspace’s capabilities for highly specialized workflows or integrations.
C. Real-World Application: Agentspace can be used by marketing managers to draft reports by pulling relevant insights from past documents and suggesting key trends. Another example: a new employee could use Agentspace to quickly find answers to HR questions, understand company policies without digging through manuals, and initiate common HR actions like submitting expense reports, all through natural language queries. This significantly reduces onboarding time and increases self-service capabilities.
D. Why This Matters: Professionals who can implement and manage these AI-powered knowledge systems become invaluable in breaking down information barriers and driving enterprise-wide productivity improvements. You become the architect of a more informed and efficient workforce.
E. Get Started:
- Google Agentspace Official Page — Learn about features and benefits.
- Agentspace Enterprise Documentation — Complete implementation guide.
- Google Next ’25 Updates: ADK, Agentspace, Application Integration — Highlights how Agentspace enhances productivity.
3. Driving Strategic Decisions: using Google Cortex Framework for Data to Insight
A. The Reality: Raw data, however vast, is merely expensive storage without actionable insights. The winning organizations are those that can rapidly transform disparate data into strategic decisions, unifying their data landscape to unlock its full potential.
B. What You Need to Know: Google Cloud Cortex Framework provides reference architectures, deployable solutions, and packaged implementation services to kickstart your Data and AI Cloud journey. It’s a comprehensive toolkit designed to help organizations rapidly design, build, and deploy robust data and AI solutions for their business.
- Unified Data Foundation: Cortex Framework is designed to help organizations unify data from critical enterprise systems like SAP, Salesforce, and marketing platforms into Google Cloud’s BigQuery. This creates a single, governed source of truth across the organization.
- Accelerated Insights: The framework provides pre-built data extractors, data transformations, and pre-designed data marts for analytics, significantly accelerating the process of generating insights.
- AI-Ready Infrastructure: Cortex Framework supports the deployment of AI models for business intelligence, allowing organizations to move beyond descriptive analytics to predictive and prescriptive capabilities, directly impacting strategic decisions.
C. Real-World Application: Cortex Framework is designed to help organizations unify data from SAP, Salesforce, and marketing platforms into BigQuery. For example, a global retail company could use Cortex Framework to integrate sales data from Salesforce, inventory levels from SAP, and customer engagement data from marketing campaigns. This unified view would allow their business intelligence teams to identify real-time trends, optimize supply chains, personalize marketing offers, and predict demand with unprecedented accuracy, leading to tangible business outcomes and a competitive edge.
D. Why This Matters: Professionals who can architect and implement these data unification and analytics solutions become strategic assets for organizations seeking to improve their data analytics capabilities, accelerate decision-making, and drive competitive advantage through data-driven insights. You become the linchpin connecting raw data to strategic business value.
E. Get Started:
- Google Cloud Cortex Framework — Official product page with solutions overview.
- Cortex Framework Documentation — Complete guide and reference architectures.
- Cortex Data Foundation GitHub — Open-source data foundation repository.
(+1) The Ripple Effect: What You’ll Gain Along the Way
As you dive deep into these three critical areas, you’ll naturally develop additional expertises in:
- Industry Knowledge: Understanding how AI’s impact on industries and it can transform specific sectors (ex: Financial, Retail, Media, Healthcare, Education, Tourism, etc). You will learn the real use cases in the field, and how it can benefit the vertical industry.
- Big Data: Managing and processing enterprise-scale big data with cloud-native tools. Either it is structured, unstructured, and semi-structured data based on its volume, velocity, and variety.
- Infrastructure Modernization: Designing cloud-native AI application platforms by using a robust well-architected framework architectures like this reference samples.
- Code Automation with AI: Using AI to code with you or for you, such as using Google Gemini CLI or Gemini Code Assist to create an enterprise application faster, better, and production ready!
The Bottom Line
The AI revolution isn’t coming — it’s here. The question isn’t whether your role will change, but whether you’ll lead that change by mastering the skills to build intelligent agents, empower employee productivity, and transform data into strategic insights.
The choice is yours: Will you be a casualty of change, or will you be the one leading the transformation?
Note: I am writing more articles to dive deep into those topics above.
Wait my upcoming three-part series where we’ll dissect how agentic AI, powered by Google’s cutting-edge tools, is revolutionizing retail media content creation, exemplified by our innovative e-commerce platform, The Priyambodo Store:
Part 1: An Architectural Overview to innovate my Retail store using AI,
Part 2: Using Gemini CLI & Code Assist to build the application,
Part 3: Leveraging ADK, A2A, MCP, and Agentengine.
About the Author: Doddi Priyambodo as Google Cloud consultant specializing in Data & AI transformations across Southeast Asia, I helped organizations navigate the transition to AI-driven operations. Connect with me to discuss how these strategies can be implemented in your organization.
You can follow and subscribe me for email notification. (To-Be Continued)
Is Your IT Job Safe? The 3 Google Cloud Skills You Can’t Afford to Ignore in the AI (& Data) Era was originally published in Google Cloud - Community on Medium, where people are continuing the conversation by highlighting and responding to this story.


33")